参考链接:
(44条消息) Python:六步教会你使用python爬虫爬取数据_只晓得闲逛的博客-CSDN博客_python爬取数据
复制好URL后,我们就进入一个网页Convert curl commands to code。(非常好用)这个网页可以根据你复制的URL,自动生成header和cookie,如下图。生成的header和cookie,直接复制走就行,粘贴到程序中。
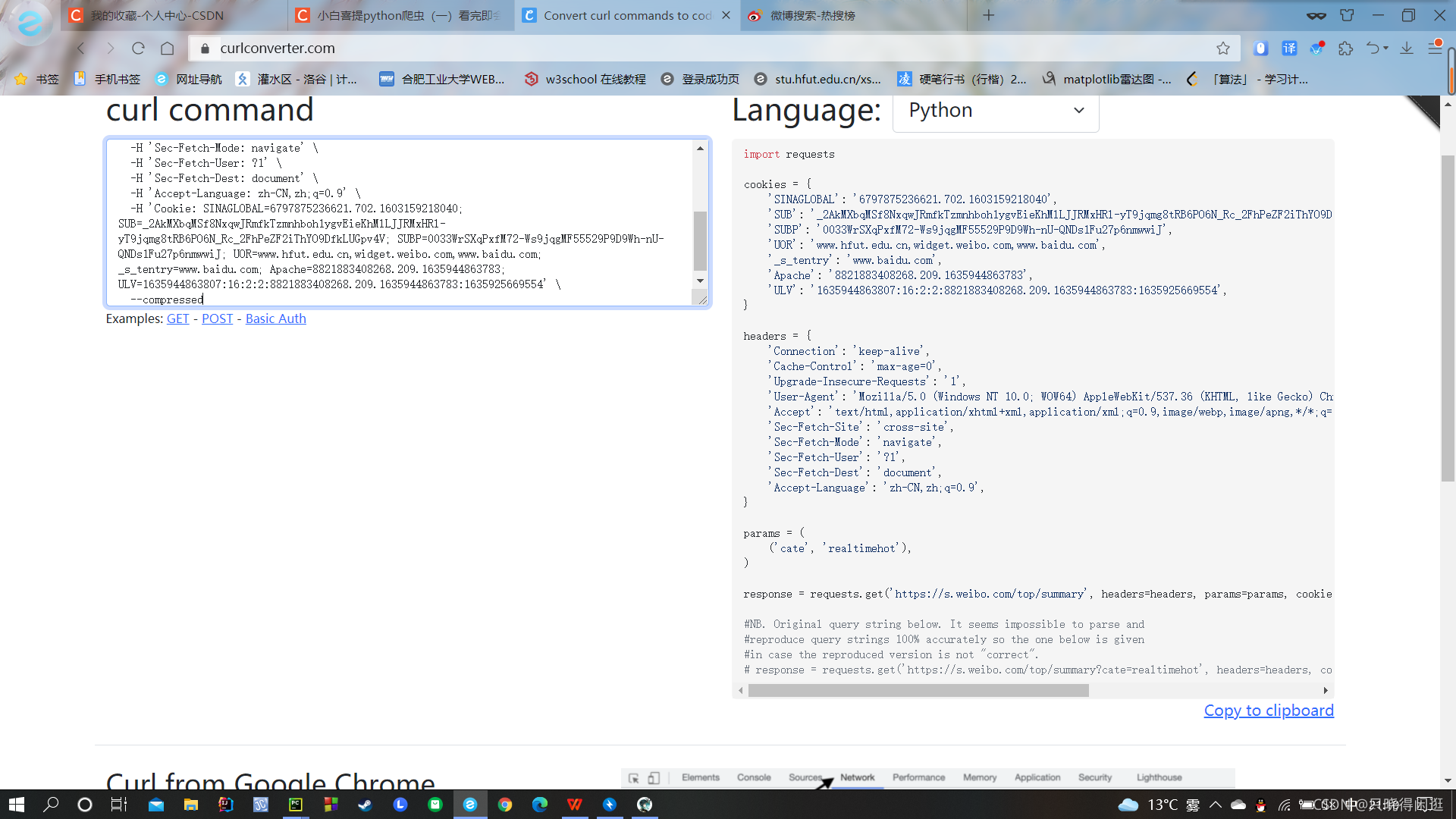
#爬虫头数据 cookies = { 'SINAGLOBAL': '6797875236621.702.1603159218040', 'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V', 'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ', '_s_tentry': 'www.baidu.com', 'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com', 'Apache': '7782025452543.054.1635925669528', 'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256', } headers = { 'Connection': 'keep-alive', 'Cache-Control': 'max-age=0', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Sec-Fetch-Site': 'cross-site', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-User': '?1', 'Sec-Fetch-Dest': 'document', 'Accept-Language': 'zh-CN,zh;q=0.9', } params = ( ('cate', 'realtimehot'), )
#获取网页
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)