一、elasticsearch是什么
elasticsearch是一个基于Lucene的搜索服务器,采用Java语言编写,使用Lucene构建索引、提供搜索功能,并作为Apache许可条款下的开发源码发布,是当前流行的企业级搜索引擎。其实Lucene的功能已经很强大了,为什么还要多此一举的开发elasticsearch呢?原因是因为Lucene只是一个由Java语言编写的库,对不适用Java语言的开发人员并不友好。所以elasticsearch在Lucene上做了很多改进,提供了多种语言的接口。Lucene之于elasticsearch堪比发动机之于汽车,elasticsearch底层使用的仍然是Lucene的api,Lucene专注于底层搜索的建设,elasticsearch专注于企业应用。elasticsearch的目标是让全文搜索变得简单,开发者可以通过简单明了的restful api轻松实现搜索功能,而不必去面对Lucene的复杂性。
二、elasticsearch架构
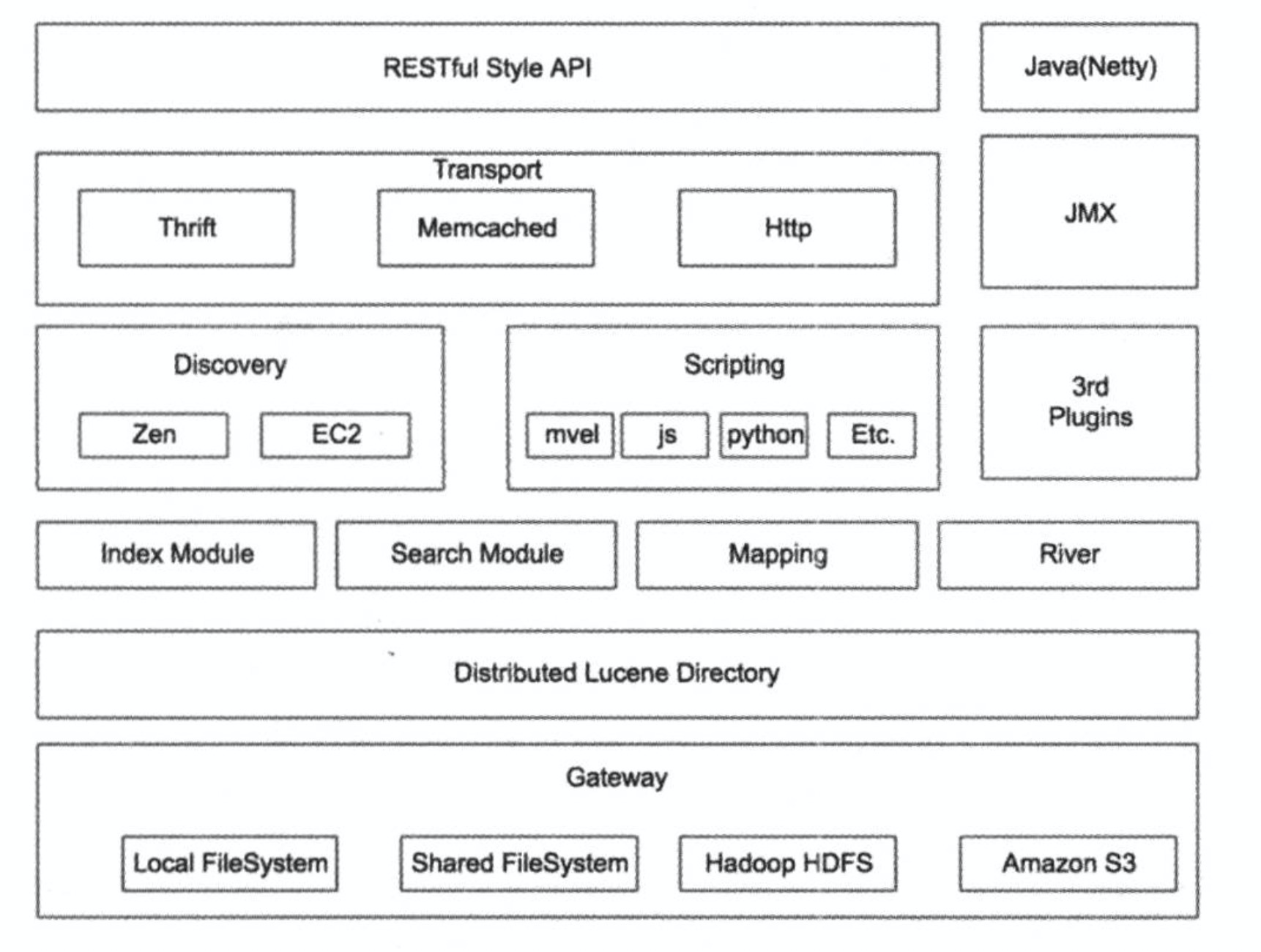
Gateway是elasticsearch用来存储索引的文件系统,支持多种文件类型,Local FileSystem是本地的文件系统,Shared FileSystem是共享存储,也可以使用Hadoop的HDFS分布式存储,也可以存储在Amazon的s3服务器上。
Gateway上层是一个分布式的Lucene框架,elasticsearch的底层Api是由Lucene提供的,每一个elasticsearch节点上都有一个Lucene节点的支持。
Lucene之上是elasticsearch的模块,包括索引模块、搜索模块、映射解析模块等。river相当于第三方插件,用于导入第三方数据源,在2.x之后已经不再使用。
elasticsearch模块之上是Discovery和Scripting和第三方插件。Discovery是elasticsearch的节点发现模块,不同机器上的elasticsearch节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是Discovery模块完成的。Scripting用来支持Python、JavaScript等多种语言的,可以在查询语句中嵌入,使用script语句性能稍低。elasticsearch也支持多种第三方插件。
再上层是elasticsearch的传输模块和JMX。传输模块支持Thrift、Memcached、Http,默认使用HTTP传输。JMX是Java的管理框架,用来管理elasticsearch应用
最上层是elasticsearch提供给用户的接口,可以通过restful api和elasticsearch集群进行交互。
三、elasticsearch优点
- 分布式:Elasticsearch横向扩展非常方便灵活,当规模较小时可以使用小规模的集群,随着数据的增长,需要更大的容量和更高的性能,此时只需增加更多的节点,Elasticsearch的自动发现机制会识别新增的节点并重新平衡分配数据。
- 全文检索:Apache Lucene是一个用Java编写的高性能的功能齐全的信息检索库,Elasticsearch在底层使用Lucene来提供强大的全文检索,提供任何开源产品的能力。自带多语言支持、强大的查询语言、地理位置支持,上下文感知的建议、自动完成和搜索片段。
- 近实时搜索和分析:数据进入Elasticsearch后,可达到实时搜索。Elasticsearch还支持聚合分析操作
- 高可用:高可用主要体现在容错方面,Elasticsearch集群会自动发现新的或失败的节点,重组和重新平衡数据,确保数据是安全和可访问的。
- 模式自由:Elasticsearch的动态mapping机制可以自动的检测数据的结构和类型,创建索引,并使数据可搜索。
- Restful Api:Elasticsearch是Api驱动,几乎任何操作都可以用一个简单的Restful Api使用JSON基于HTTP请求实现,客户端也可使用多种编程语言。
- 应用场景丰富:站内搜索、nosql数据库(Elasticsearch在读写性能上由于MongoDB,同时也支持地理位置查询)、日志分析(日志分析平台ELK,能够对日志进行集中的收集、存储、搜索、分析、监控以及可视化)等。
四、Elasticsearch核心概念[1]
来源:https://www.jianshu.com/p/cec1b8b3698d
集群(cluster)
代表一个集群,集群中有多个节点node,其中一个为主节点,这个主节点可以通过选举产生的,主节点是对于集群内部来说的。ES的一个概念就是去中心化,字面上理解就是无中心化节点,这是对于集群外部来说的,因为从外部来看ES集群,在逻辑上是一个整体,你与任何一个节点的通信和整个ES集群通信是等价的
一个集群就是由一个或者多个节点组织在一起,它们共同持有整个的数据,并在一起提供索引和搜索功能。一个集群由一个唯一的名字标识。一个节点只能通过指定某个集群的名字,来加入这个集群。
节点(node)
一个节点是集群中的一个服务器,作为集群的一部分,存储数据,参与集群的索引和搜索功能。一个节点也是由一个名字来标识的。默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点,这个名字对于管理工作来说挺重要的,因为在这个管理过程中,要确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
索引(index)
ES将它的数据存储在一个或多个索引(index)中。类似sql中的数据库。可以向索引中写入文档或者读取文档,并通过ES内部使用Lucene将数据索引或从索引中检索数据
一个索引就是一个拥有几分相似特征的文档的集合(类似于我们在数据库中的库结构),一个索引由一个名字来标识,并且在我们要对对这个索引中的文档进行索引,搜索,更新和删除的时候,都要使用到这个名字。
文档(document)
文档是ES中主要的实体。对所有使用ES的案例来说,他们最终都可以终结为对文档的搜索。文档由字段构成。
映射(mapping)
所有文档写进索引之前都会先进行分析,如果将输入的文本分割为词条,哪些词条又会被过滤,这种行为叫做映射(mapping)。一般由用户自己定义规则
类型(type)
每个文档都有与之对应的类型定义。这允许用户在一个索引中存储多种文档类型,并为不同文档类型提供不同的映射
分片(shards)
shards代表索引分片,ES可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
分片有两个好处,一是可以水平扩展,另一个是可以并发提高性能。
副本(replicas)
代表索引副本,ES可以设置多个索引副本,副本的作用一是提高系统的容错性,实现高可用(HA),当某个节点某个分片损坏或丢失时可以从副本中恢复;二是提高ES的查询效率,ES会自动对搜索请求进行负载均衡。
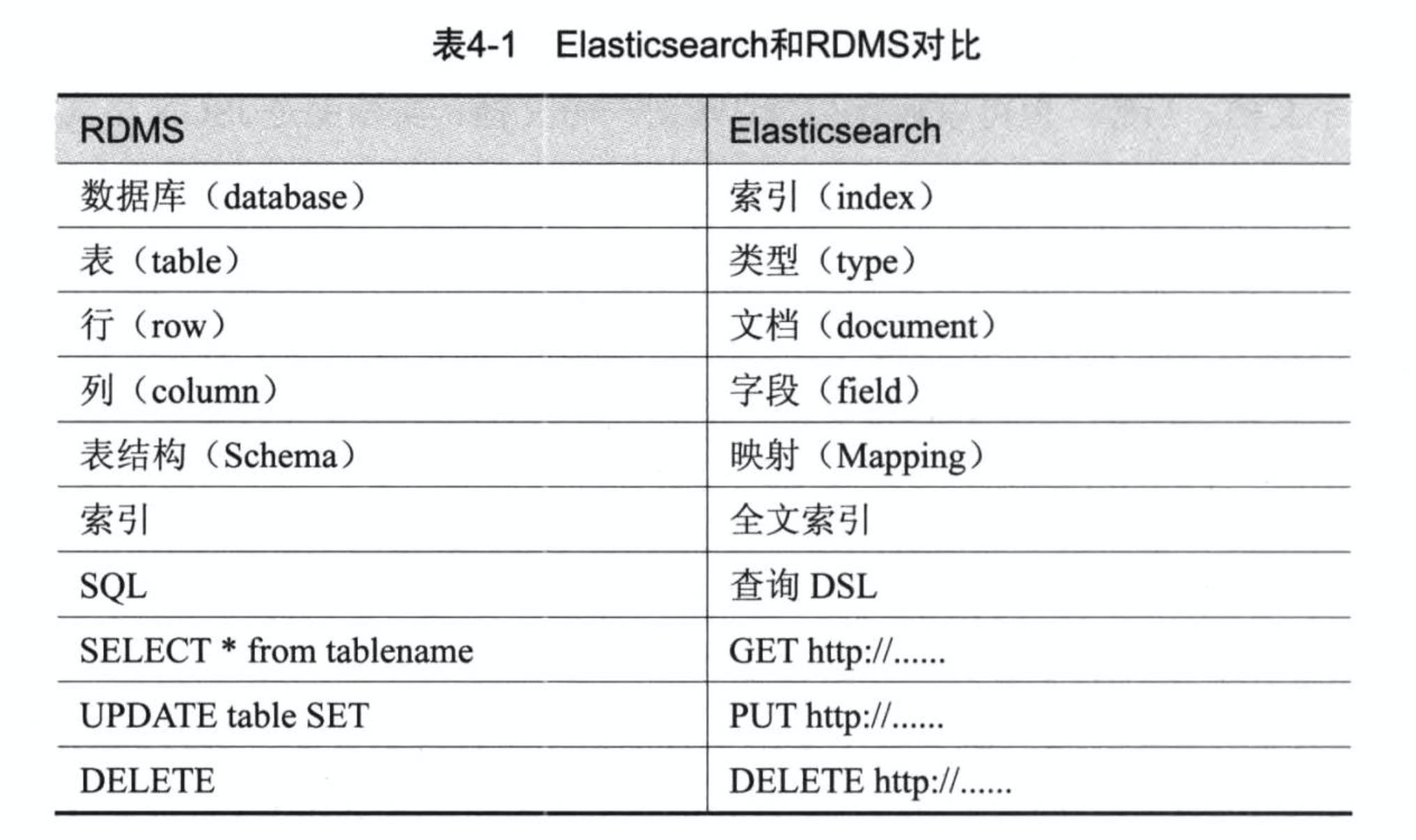
五、对比RDBMS
Elasticsearch可以看成是一个数据库,只是和关系型数据库比起来数据格式和功能不一样而已
六、索引管理
创建索引和mysql中创建一个数据库是一样的,注意Elasticsearch索引名称中不能出现大写字母
新建一个索引,名为blog
PUT blog
响应结果:
{ "acknowledged": true, "shards_acknowledged": true, "index": "blog" }
返回结果显示acknowledged的值为true,说明新建索引成功。如果索引名含有大写字母,会报一个非法的索引名异常
PUT ABC
响应结果:
{ "error": { "root_cause": [ { "type": "invalid_index_name_exception", "reason": "Invalid index name [ABC], must be lowercase", "index_uuid": "_na_", "index": "ABC" } ], "type": "invalid_index_name_exception", "reason": "Invalid index name [ABC], must be lowercase", "index_uuid": "_na_", "index": "ABC" }, "status": 400 }
如果新添加的索引在Elasticsearch服务器中已存在,新建同名索引已存在
PUT blog
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [blog/X95-a-PIRDK0EONkuAeKcg] already exists",
"index_uuid": "X95-a-PIRDK0EONkuAeKcg",
"index": "blog"
}
],
"type": "resource_already_exists_exception",
"reason": "index [blog/X95-a-PIRDK0EONkuAeKcg] already exists",
"index_uuid": "X95-a-PIRDK0EONkuAeKcg",
"index": "blog"
},
"status": 400
}
Elasticsearch默认给一个索引设置5个分片1个副本,一个索引的分片数一经指定后就不能再修改,副本数可以通过命令随时更改。如果想创建自定义分片数和副本数的索引,可以通过setting参数在索引时设置初始化信息。以创建3个分片0个副本为例:
PUT blog
{ "settings": { "number_of_shards": 3, "number_of_replicas": 0 } }
更新副本数
PUT blog/_settings
{ "number_of_replicas": 2 }
查看索引
使用GET方法加上_settings参数可以查看一个索引的所有配置信息,例如查看blog索引的所有设置信息
GET blog/_settings
{ "blog": { "settings": { "index": { "creation_date": "1575511488734", "number_of_shards": "5", "number_of_replicas": "1", "uuid": "X95-a-PIRDK0EONkuAeKcg", "version": { "created": "6070199" }, "provided_name": "blog" } } } }
同时查看多个索引的settings信息
GET blog,doc/_settings
查看集群中所有索引的settings信息
GET _all/_settings
索引的删除只需要使用delete方法,传入要删除的索引名即可,执行索引删除命令前需要慎重考虑,因为一旦执行删除操作,索引中的文档就不复存在,注意在删除数据之前做好备份操作
删除名为blog的索引
DELETE blog
响应结果:
{ "acknowledged": true }
如果删除的索引不存在,会报索引未找到异常
DELETE blog
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index", "resource.type": "index_or_alias", "resource.id": "blog", "index_uuid": "_na_", "index": "blog" } ], "type": "index_not_found_exception", "reason": "no such index", "resource.type": "index_or_alias", "resource.id": "blog", "index_uuid": "_na_", "index": "blog" }, "status": 404 }