1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
K-means算法:
from sklearn.datasets import load_iris import matplotlib.pyplot as plt import numpy as np import copy iris = load_iris() data = iris.data[:,1] def get_distance(X,Y): return np.sum((X-Y)**2)**0.5 center=data[:3] last_center=center result=[[],[],[]] max_iter=10 for i in range(max_iter): result = [[], [], []] for j in range(len(data)): temp = [] for k in range(len(center)): temp.append(get_distance(data[j], center[k])) result[temp.index(min(temp))].append(data[j]) center=[] for l in range(3): if result[l]: center.append(np.mean(result[l])) else: center.append(0) if(np.all(center == last_center)): break else: last_center = np.copy(center) end_result=[] k_result=[] for i in range(len(result)): for j in range(len(result[i])): end_result.append(result[i][j]) k_result.append(i) print('最终聚类中心',center) print('最终聚类结果',end_result) plt.scatter(end_result,end_result,c=k_result,cmap='rainbow') plt.show()
结果截图:
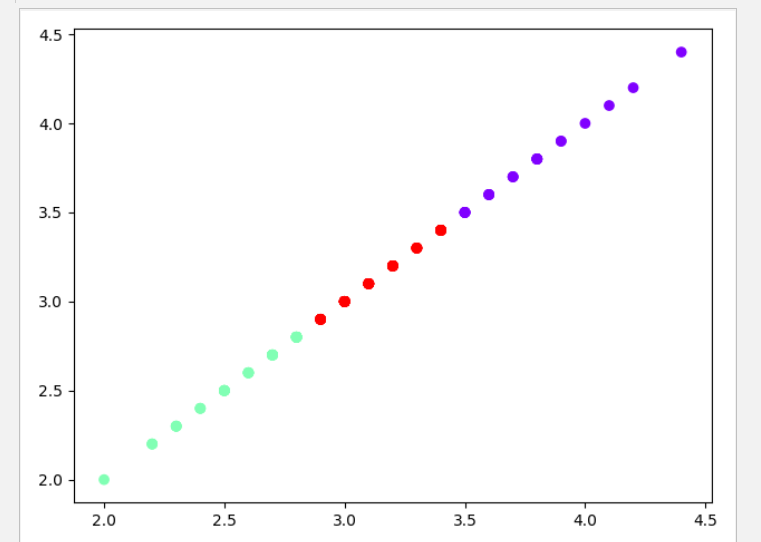
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np iris=load_iris() sl = iris.data[:,1] X=sl.reshape(-1,1) est = KMeans(n_clusters=3) est.fit(X) y_kmeans=est.predict(X) plt.scatter(X[:,0],X[:,0],c=y_kmeans,cmap='rainbow') plt.show()
结果截图:
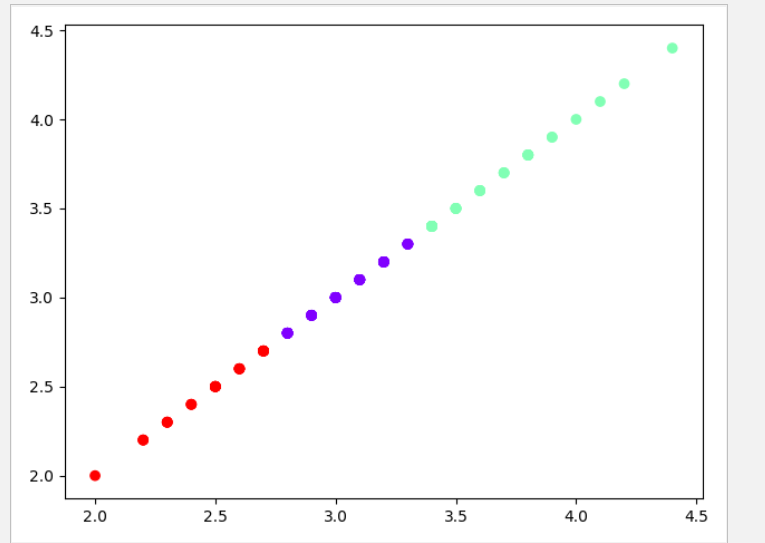
4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np data=load_iris() x2=data.data k2=KMeans(n_clusters=3) k2.fit(x2) kc2=k2.cluster_centers_ y_kmeans2=k2.predict(x2) print(x2) plt.scatter(x2[:,0],x2[:,1],c=y_kmeans2,cmap='rainbow') plt.show()
结果截图:

5).想想k均值算法中以用来做什么?
k均值算法是聚类算法,通过聚类可以更好的用来识别事物的特性,所以,k均值算法可以用来实现自动识别,通过数据训练,获取模型,根据特性,来实现自动识别。