day18
1.Map引入
Map是区分于Collection的另外一个"老大"
作为学生来说,是根据学号来区分不同的学生的,那么假设我现在已经知道了学生的学号,我要根据学号去获取学生姓名,请问怎么做呢?
如果采用前面讲解过的集合,我们只能把学号和学生姓名作为一个对象的成员,然后存储整个对象,将来遍历的时候,判断,获取对应的名称。
但是呢,如果我都能把学生姓名拿出来了,我还需要根据编号去找吗?
针对我们目前的这种需求:仅仅知道学号,就想知道学生姓名的情况,Java就提供了一种新的集合 Map。
通过查看API,我们知道Map集合的一个最大的特点,就是它可以存储键值对的元素。这个时候存储我们上面的需求,就可以这样做
* 学号1 姓名1
* 学号2 姓名2
* 学号3 姓名3
* 学号2(不行)姓名4
* 学号4 姓名4
Map集合的特点:
* 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
*
* Map集合和Collection集合的区别?
* Map集合存储元素是成对出现的,Map集合的键是唯一的,值是可重复的。可以把这个理解为:夫妻对
* Collection集合存储元素是单独出现的,Collection的儿子Set是唯一的,List是可重复的。可以把这个理解为:光棍(11.11)
注意:
* Map集合的数据结构值针对键有效,跟值无关
* HashMap,TreeMap等会讲。
* Collection集合的数据结构是针对元素有效
2. Map集合的功能概述:
* 1:添加功能
* V put(K key,V value):添加元素。这个其实还有另一个功能?先不告诉你,等会讲
* 如果键是第一次存储,就直接存储元素,返回null
* 如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
* 2:删除功能
* void clear():移除所有的键值对元素
* V remove(Object key):根据键删除键值对元素,并把值返回
* 3:判断功能
* boolean containsKey(Object key):判断集合是否包含指定的键
* boolean containsValue(Object value):判断集合是否包含指定的值
* boolean isEmpty():判断集合是否为空
* 4:获取功能
* Set<Map.Entry<K,V>> entrySet():???
* V get(Object key):根据键获取值
* Set<K> keySet():获取集合中所有键的集合
* Collection<V> values():获取集合中所有值的集合
* 5:长度功能
* int size():返回集合中的键值对的对数
import java.util.HashMap;
import java.util.Map;
public class MapDemo {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 添加元素
// V put(K key,V value):添加元素。这个其实还有另一个功能?先不告诉你,等会讲
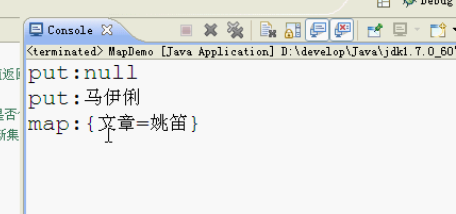
// System.out.println("put:" + map.put("文章", "马伊俐"));
// System.out.println("put:" + map.put("文章", "姚笛"));
map.put("邓超", "孙俪");
map.put("黄晓明", "杨颖");
map.put("周杰伦", "蔡依林");
map.put("刘恺威", "杨幂");
// void clear():移除所有的键值对元素
// map.clear();
// V remove(Object key):根据键删除键值对元素,并把值返回
// System.out.println("remove:" + map.remove("黄晓明"));
// System.out.println("remove:" + map.remove("黄晓波"));
// boolean containsKey(Object key):判断集合是否包含指定的键
// System.out.println("containsKey:" + map.containsKey("黄晓明"));
// System.out.println("containsKey:" + map.containsKey("黄晓波"));
// boolean isEmpty():判断集合是否为空
// System.out.println("isEmpty:"+map.isEmpty());
//int size():返回集合中的键值对的对数
System.out.println("size:"+map.size());
// 输出集合名称
System.out.println("map:" + map);
}
}
一些测试


查看put的源码,了解它的返回值为什么是这样

3.Map集合的获取功能测试
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* 获取功能:
* V get(Object key):根据键获取值
* Set<K> keySet():获取集合中所有键的集合
* Collection<V> values():获取集合中所有值的集合
*/
public class MapDemo2 {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 创建元素并添加元素
map.put("邓超", "孙俪");
map.put("黄晓明", "杨颖");
map.put("周杰伦", "蔡依林");
map.put("刘恺威", "杨幂");
// V get(Object key):根据键获取值
System.out.println("get:" + map.get("周杰伦"));
System.out.println("get:" + map.get("周杰")); // 返回null
System.out.println("----------------------");
// Set<K> keySet():获取集合中所有键的集合
Set<String> set = map.keySet();
for (String key : set) {
System.out.println(key);
}
System.out.println("----------------------");
// Collection<V> values():获取集合中所有值的集合
Collection<String> con = map.values();
for (String value : con) {
System.out.println(value);
}
}
}
输出如下

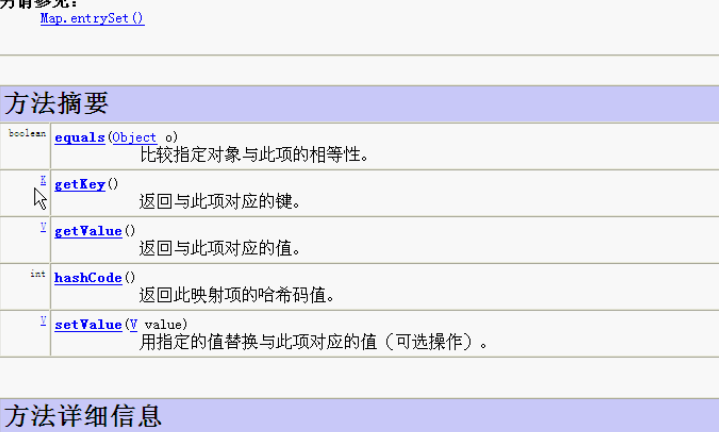
4.Map集合的遍历之键找值
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* Map集合的遍历。
* Map -- 夫妻对
* 思路:
* A:把所有的丈夫给集中起来。
* B:遍历丈夫的集合,获取得到每一个丈夫。
* C:让丈夫去找自己的妻子。
*
* 思路转换:
* A:获取所有的键
* B:遍历键的集合,获取得到每一个键
* C:根据键去找值
*/
public class MapDemo3 {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 创建元素并添加到集合
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("杨康", "穆念慈");
map.put("陈玄风", "梅超风");
// 遍历
// 获取所有的键
Set<String> set = map.keySet();
// 遍历键的集合,获取得到每一个键
for (String key : set) {
// 根据键去找值
String value = map.get(key);
System.out.println(key + "---" + value);
}
}
}
5.Map集合的遍历之键值对对象找键和值
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* Map集合的遍历。
* Map -- 夫妻对
*
* 思路:
* A:获取所有结婚证的集合
* B:遍历结婚证的集合,得到每一个结婚证
* C:根据结婚证获取丈夫和妻子
*
* 转换:
* A:获取所有键值对对象的集合
* B:遍历键值对对象的集合,得到每一个键值对对象
* C:根据键值对对象获取键和值
*
* 这里面最麻烦的就是键值对对象如何表示呢?
* 看看我们开始的一个方法:
* Set<Map.Entry<K,V>> entrySet():返回的是键值对对象的集合
*/
public class MapDemo4 {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 创建元素并添加到集合
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("杨康", "穆念慈");
map.put("陈玄风", "梅超风");
// 获取所有键值对对象的集合
Set<Map.Entry<String, String>> set = map.entrySet();
// 遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : set) {
// 根据键值对对象获取键和值,me相当于
一个结婚证
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "---" + value);
}
}
}
注意一个奇怪的接口

及其方法
6.Map集合遍历的两种方式比较图解

7.一个快速新建包以及新java文件的方法


8.HashMap集合键是Stirng值是String的案例
import java.util.HashMap;
import java.util.Set;
/*
* HashMap:是基于哈希表的Map接口实现。
* 哈希表的作用是用来保证键的唯一性的。
*
* HashMap<String,String>
* 键:String
* 值:String
*/
public class HashMapDemo {
public static void main(String[] args) {
// 创建集合对象
HashMap<String, String> hm = new HashMap<String, String>();
// 创建元素并添加元素
// String key1 = "it001";
// String value1 = "马云";
// hm.put(key1, value1);
hm.put("it001", "马云");
hm.put("it003", "马化腾");
hm.put("it004", "乔布斯");
hm.put("it005", "张朝阳");
hm.put("it002", "裘伯君"); // wps
hm.put("it001", "比尔盖茨");
// 遍历
Set<String> set = hm.keySet();
for (String key : set) {
String value = hm.get(key);
System.out.println(key + "---" + value);
}
}
}
9.HashMap集合键是Integer值是String的案例
import java.util.HashMap;
import java.util.Set;
/*
* HashMap<Integer,String>
* 键:Integer
* 值:String
*/
public class HashMapDemo2 {
public static void main(String[] args) {
// 创建集合对象
HashMap<Integer, String> hm = new HashMap<Integer, String>();
// 创建元素并添加元素
// Integer i = new Integer(27);
// Integer i = 27;//这样也可以的
// String s = "林青霞";
// hm.put(i, s);
hm.put(27, "林青霞");
hm.put(30, "风清扬");
hm.put(28, "刘意");
hm.put(29, "林青霞");
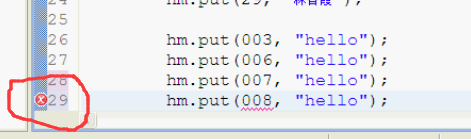
// 下面的写法是八进制,但是不能出现8以上的单个数据
// hm.put(003, "hello");
// hm.put(006, "hello");
// hm.put(007, "hello");
// hm.put(008, "hello");
//003前面的0代表进制是八进制
// 遍历
Set<Integer> set = hm.keySet();
for (Integer key : set) {
String value = hm.get(key);
System.out.println(key + "---" + value);
}
// 下面这种方式仅仅是集合的元素的字符串表示
// System.out.println("hm:" + hm);
}
}
10.HashMap集合键是String值是Student的案例)
import java.util.HashMap;
import java.util.Set;
/*
* HashMap<String,Student>
* 键:String 学号
* 值:Student 学生对象
*/
public class HashMapDemo3 {
public static void main(String[] args) {
// 创建集合对象
HashMap<String, Student> hm = new HashMap<String, Student>();
// 创建学生对象
Student s1 = new Student("周星驰", 58);
Student s2 = new Student("刘德华", 55);
Student s3 = new Student("梁朝伟", 54);
Student s4 = new Student("刘嘉玲", 50);
// 添加元素
hm.put("9527", s1);
hm.put("9522", s2);
hm.put("9524", s3);
hm.put("9529", s4);
// 遍历
Set<String> set = hm.keySet();
for (String key : set) {
// 注意了:这次值不是字符串了
// String value = hm.get(key);
Student value = hm.get(key);
System.out.println(key + "---" + value.getName() + "---"
+ value.getAge());
}
}
}
(Student类就省略了)
11.HashMap集合键是Student值是String的案例
常规思路
HashMapDemo4.java
================================
import java.util.HashMap;
import java.util.Set;
/*
* HashMap<Student,String>
* 键:Student
* 要求:如果两个对象的成员变量值都相同,则为同一个对象。
* 值:String
*/
public class HashMapDemo4 {
public static void main(String[] args) {
// 创建集合对象
HashMap<Student, String> hm = new HashMap<Student, String>();
// 创建学生对象
Student s1 = new Student("貂蝉", 27);
Student s2 = new Student("王昭君", 30);
Student s3 = new Student("西施", 33);
Student s4 = new Student("杨玉环", 35);
Student s5 = new Student("貂蝉", 27);
// 添加元素
hm.put(s1, "8888");
hm.put(s2, "6666");
hm.put(s3, "5555");
hm.put(s4, "7777");
hm.put(s5, "9999");
// 遍历
Set<Student> set = hm.keySet();
for (Student key : set) {
String value = hm.get(key);
System.out.println(key.getName() + "---" + key.getAge() + "---"
+ value);
}
}
}
=============================
但是有问题,貂蝉是相同的Student对象,重复了

回想到存储到Set的Student 并没有重写HashCode以及equals方法,因此

12.LinkedHashMap
LinkedHashMap:是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。
* 由哈希表保证键的唯一性
* 由链表保证键盘的有序(存储和取出的顺序一致)
public static void main(String[] args) {
// 创建集合对象
LinkedHashMap<String, String> hm = new LinkedHashMap<String, String>();
// 创建并添加元素
hm.put("2345", "hello");
hm.put("1234", "world");
hm.put("3456", "java");
hm.put("1234", "javaee");
hm.put("3456", "android");
// 遍历
Set<String> set = hm.keySet();
for (String key : set) {
String value = hm.get(key);
System.out.println(key + "---" + value);
}
}

13.TreeMap
TreeMap集合键是String值是String的案例
import java.util.Set;
import java.util.TreeMap;
/*
* TreeMap:是基于红黑树的Map接口的实现。
*
* HashMap<String,String>
* 键:String
* 值:String
*/
public class TreeMapDemo {
public static void main(String[] args) {
// 创建集合对象
TreeMap<String, String> tm = new TreeMap<String, String>();
// 创建元素并添加元素
tm.put("hello", "你好");
tm.put("world", "世界");
tm.put("java", "爪哇");
tm.put("world", "世界2");
tm.put("javaee", "爪哇EE");
// 遍历集合
Set<String> set = tm.keySet();
for (String key : set) {
String value = tm.get(key);
System.out.println(key + "---" + value);
}
}
}
14.TreeMap集合键是Student值是String的案例(留意,默认Student类并不实现Comparable接口。所以要自己写)
import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;
/*
* TreeMap<Student,String>
* 键:Student
* 值:String
*/
public class TreeMapDemo2 {
public static void main(String[] args) {
// 创建集合对象
TreeMap<Student, String> tm = new TreeMap<Student, String>(
new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 主要条件
int num = s1.getAge() - s2.getAge();
// 次要条件
int num2 = num == 0 ? s1.getName().compareTo(
s2.getName()) : num;
return num2;
}
});
// 创建学生对象
Student s1 = new Student("潘安", 30);
Student s2 = new Student("柳下惠", 35);
Student s3 = new Student("唐伯虎", 33);
Student s4 = new Student("燕青", 32);
Student s5 = new Student("唐伯虎", 33);
// 存储元素
tm.put(s1, "宋朝");
tm.put(s2, "元朝");
tm.put(s3, "明朝");
tm.put(s4, "清朝");
tm.put(s5, "汉朝");
// 遍历
Set<Student> set = tm.keySet();
for (Student key : set) {
String value = tm.get(key);
System.out.println(key.getName() + "---" + key.getAge() + "---"
+ value);
}
}
}
15.统计字符串中每个字符出现的次数案例图解
需求 :"aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5)b(4)c(3)d(2)e(1)

代码实现
import java.util.Scanner;
import java.util.Set;
import java.util.TreeMap;
/*
* 需求 :"aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5)b(4)c(3)d(2)e(1)
*
* 分析:
* A:定义一个字符串(可以改进为键盘录入)
* B:定义一个TreeMap集合
* 键:Character
* 值:Integer
* C:把字符串转换为字符数组
* D:遍历字符数组,得到每一个字符
* E:拿刚才得到的字符作为键到集合中去找值,看返回值
* 是null:说明该键不存在,就把该字符作为键,1作为值存储
* 不是null:说明该键存在,就把值加1,然后重写存储该键和值
* F:定义字符串缓冲区变量
* G:遍历集合,得到键和值,进行按照要求拼接
* H:把字符串缓冲区转换为字符串输出
*
* 录入:linqingxia
* 结果:result:a(1)g(1)i(3)l(1)n(2)q(1)x(1)
*/
public class TreeMapDemo {
public static void main(String[] args) {
// 定义一个字符串(可以改进为键盘录入)
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String line = sc.nextLine();
// 定义一个TreeMap集合
TreeMap<Character, Integer> tm = new TreeMap<Character, Integer>();
//把字符串转换为字符数组
char[] chs = line.toCharArray();
//遍历字符数组,得到每一个字符
for(char ch : chs){
//拿刚才得到的字符作为键到集合中去找值,看返回值
Integer i = tm.get(ch);
//是null:说明该键不存在,就把该字符作为键,1作为值存储
if(i == null){
tm.put(ch, 1);
}else {
//不是null:说明该键存在,就把值加1,然后重写存储该键和值
i++;
tm.put(ch,i);
}
}
//定义字符串缓冲区变量
StringBuilder sb= new StringBuilder();
//遍历集合,得到键和值,进行按照要求拼接
Set<Character> set = tm.keySet();
for(Character key : set){
Integer value = tm.get(key);
sb.append(key).append("(").append(value).append(")");
}
//把字符串缓冲区转换为字符串输出
String result = sb.toString();
System.out.println("result:"+result);
}
}
16.两个个面试题
1:Hashtable和HashMap的区别?
2:List,Set,Map等接口是否都继承子Map接口?

import java.util.Hashtable;
/*
* 1:Hashtable和HashMap的区别?
* Hashtable:线程安全,效率低。不允许null键和null值
* HashMap:线程不安全,效率高。允许null键和null值
* (其实HashMap就是用来替代Hashtable的,就像ArrayList替代vector一样)
* 2:List,Set,Map等接口是否都继承子Map接口?
* List,Set不是继承自Map接口,它们继承自Collection接口
* Map接口本身就是一个顶层接口
*/
public class HashtableDemo {
public static void main(String[] args) {
// HashMap<String, String> hm = new HashMap<String, String>();
Hashtable<String, String> hm = new Hashtable<String, String>();
hm.put("it001", "hello");
// hm.put(null, "world"); //NullPointerException
// hm.put("java", null); // NullPointerException
System.out.println(hm);
}
}
17. Collections类
(对应也有Arrays类)
* Collections:是针对集合进行操作的工具类,都是静态方法。
*
* 面试题:
* Collection和Collections的区别?
* Collection:是单列集合的顶层接口,有子接口List和Set。(Map是双列的)
* Collections:是针对集合操作的工具类,有对集合进行排序和二分查找的方法
18.Collections的静态方法
要知道的方法
* public static <T> void sort(List<T> list):排序 默认情况下是自然顺序。
* public static <T> int binarySearch(List<?> list,T key):二分查找
* public static <T> T max(Collection<?> coll):最大值
* public static void reverse(List<?> list):反转(逆序排序)
* public static void shuffle(List<?> list):随机置换(犹如洗牌,每次运行结果不一样)
19.如果同时有自然排序和比较器排序,以比较器排序为主(也就是说,当同时实现了Student类的自然排序(implements Comparable<Student>)以及
比较器排序的话(new Comparator<Student>()),比较器排序会覆盖自然排序)
以下是同一个包的两个类(共同实现了自然排序以及比较器排序)
Student类
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
int num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
}
=================================================
CollectionsDemo 类
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/*
* Collections可以针对ArrayList存储基本包装类的元素排序,存储自定义对象可不可以排序呢?
*/
public class CollectionsDemo {
public static void main(String[] args) {
// 创建集合对象
List<Student> list = new ArrayList<Student>();
// 创建学生对象
Student s1 = new Student("林青霞", 27);
Student s2 = new Student("风清扬", 30);
Student s3 = new Student("刘晓曲", 28);
Student s4 = new Student("武鑫", 29);
Student s5 = new Student("林青霞", 27);
// 添加元素对象
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
// 排序
// 自然排序
// Collections.sort(list);
// 比较器排序
// 如果同时有自然排序和比较器排序,以比较器排序为主
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num = s2.getAge() - s1.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName())
: num;
return num2;
}
});
// 遍历集合
for (Student s : list) {
System.out.println(s.getName() + "---" + s.getAge());
}
}
}
附:Collections 的 两种sort方法

20.模拟斗地主洗牌和发牌案例(省略)
注意问题
特殊字符保存问题

未排序版本
import java.util.ArrayList;
import java.util.Collections;
/*
* 模拟斗地主洗牌和发牌
*
* 分析:
* A:创建一个牌盒
* B:装牌
* C:洗牌
* D:发牌
* E:看牌
*/
public class PokerDemo {
public static void main(String[] args) {
// 创建一个牌盒
ArrayList<String> array = new ArrayList<String>();
// 装牌
// 黑桃A,黑桃2,黑桃3,...黑桃K
// 红桃A,...
// 梅花A,...
// 方块A,...
// 定义一个花色数组
String[] colors = { "♠", "♥", "♣", "♦" };
// 定义一个点数数组
String[] numbers = { "A", "2", "3", "4", "5", "6", "7", "8", "9", "10",
"J", "Q", "K" };
// 装牌
for (String color : colors) {
for (String number : numbers) {
array.add(color.concat(number));
}
}
array.add("小王");
array.add("大王");
// 洗牌
Collections.shuffle(array);//shuffle方法只能是接收list,而不接受set,map

// System.out.println("array:" + array);
// 发牌
ArrayList<String> fengQingYang = new ArrayList<String>();
ArrayList<String> linQingXia = new ArrayList<String>();
ArrayList<String> liuYi = new ArrayList<String>();
ArrayList<String> diPai = new ArrayList<String>();
for (int x = 0; x < array.size(); x++) {
if (x >= array.size() - 3) {
diPai.add(array.get(x));
} else if (x % 3 == 0) {
fengQingYang.add(array.get(x));
} else if (x % 3 == 1) {
linQingXia.add(array.get(x));
} else if (x % 3 == 2) {
liuYi.add(array.get(x));
}
}
// 看牌
lookPoker("风清扬", fengQingYang);
lookPoker("林青霞", linQingXia);
lookPoker("刘意", liuYi);
lookPoker("底牌", diPai);
}
public static void lookPoker(String name, ArrayList<String> array) {
System.out.print(name + "的牌是:");
for (String s : array) {
System.out.print(s + " ");
}
System.out.println();
}
}
运行示例图

对牌进行排序的思路,代码
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.TreeSet;
/*
* 思路:
* A:创建一个HashMap集合
* B:创建一个ArrayList集合
* C:创建花色数组和点数数组
* D:从0开始往HashMap里面存储编号,并存储对应的牌(相当于一个信息对照表)
* 同时往ArrayList里面存储编号即可。(洗牌只能用list)
* E:洗牌(洗的是编号)
* F:发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收)
* G:看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
*/
public class PokerDemo {
public static void main(String[] args) {
// 创建一个HashMap集合
HashMap<Integer, String> hm = new HashMap<Integer, String>();
// 创建一个ArrayList集合
ArrayList<Integer> array = new ArrayList<Integer>();
// 创建花色数组和点数数组
// 定义一个花色数组
String[] colors = { "♠", "♥", "♣", "♦" };
// 定义一个点数数组
String[] numbers = { "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q",
"K", "A", "2", };
// 从0开始往HashMap里面存储编号,并存储对应的牌,同时往ArrayList里面存储编号即可。
int index = 0;
for (String number : numbers) {
for (String color : colors) {
String poker = color.concat(number);
hm.put(index, poker);
array.add(index);
index++;
}
}
hm.put(index, "小王");
array.add(index);
index++;
hm.put(index, "大王");
array.add(index);
// 洗牌(洗的是编号)
Collections.shuffle(array);
// 发牌(发的也是编号,为了保证编号是排序的,就创建TreeSet集合接收)
TreeSet<Integer> fengQingYang = new TreeSet<Integer>();
TreeSet<Integer> linQingXia = new TreeSet<Integer>();
TreeSet<Integer> liuYi = new TreeSet<Integer>();
TreeSet<Integer> diPai = new TreeSet<Integer>();
for (int x = 0; x < array.size(); x++) {
if (x >= array.size() - 3) {
diPai.add(array.get(x));
} else if (x % 3 == 0) {
fengQingYang.add(array.get(x));
} else if (x % 3 == 1) {
linQingXia.add(array.get(x));
} else if (x % 3 == 2) {
liuYi.add(array.get(x));
}
}
// 看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
lookPoker("风清扬", fengQingYang, hm);
lookPoker("林青霞", linQingXia, hm);
lookPoker("刘意", liuYi, hm);
lookPoker("底牌", diPai, hm);
}
// 写看牌的功能
public static void lookPoker(String name, TreeSet<Integer> ts,
HashMap<Integer, String> hm) {
System.out.print(name + "的牌是:");
for (Integer key : ts) {
String value = hm.get(key);
System.out.print(value + " ");
}
System.out.println();
}
}
对以上代码的解析:为了用Collections的shuffle功能,只能创建ArrayList:
为了实现自动排序,只能选择TreeSet;然后为了有一个对照表,使用了HashMap。
=======================================
day19
1.前一天的笔记补充
Map(双列集合)
A:Map集合的数据结构仅仅针对键有效,与值无关。
B:存储的是键值对形式的元素,键唯一,值可重复。
HashMap
底层数据结构是哈希表。线程不安全,效率高
Hashtable
底层数据结构是哈希表。线程安全,效率低
注意Map的方法
Map:
containskey(),containsValue()
entrySet()
2.异常
异常引入
异常:程序出现了不正常的情况。
*
* 举例:今天天气很好,班长出去旅游。骑着自行车,去山里面呼吸新鲜空气。
* 问题1:山路塌陷了,班长及时停住了,但是过不去了。严重的问题。
* 问题2:班长出门推自行车,发现气没了,把气吹起来。出发前就应该检查的问题。
* 问题3:班长骑着车在山路上惬意的行驶着,山路两边是有小石子的,中间是平坦的水泥路。
* 一直在平坦的水泥路上行驶是没有任何问题的,但是呢,他偏偏喜欢骑到小石子上,结果爆胎了。旅游的过程中出现的问题。
* no zuo no die。
*
* 程序的异常:Throwable
* 严重问题:Error 我们不处理。这种问题一般都是很严重的,比如说内存溢出。
* 问题:Exception
* 编译期问题:不是RuntimeException的异常 必须进行处理的,因为你不处理,编译就不能通过。
* 运行期问题:RuntimeException 这种问题我们也不处理,因为是你的问题,而且这个问题出现肯定是我们的代码不够严谨,需要修正代码的。
*
* 如何程序出现了问题,我们没有做任何处理,最终jvm会做出默认的处理。
* 把异常的名称,原因及出现的问题等信息输出在控制台。
* 同时会结束程序。

3.处理异常
我们自己如何处理异常呢?
A:try...catch...finally
B:throws 抛出
try...catch...finally的处理格式:
try {
可能出现问题的代码;
}catch(异常名 变量) {
针对问题的处理;
}finally {
释放资源;
}
变形格式:
try {
可能出现问题的代码;
}catch(异常名 变量) {
针对问题的处理;
}
注意:
A:try里面的代码越少越好
B:catch里面必须有内容,哪怕是给出一个简单的提示
==========================================
public static void main(String[] args) {
// 第一阶段
int a = 10;
// int b = 2;
int b = 0;
try {
System.out.println(a / b);
} catch (ArithmeticException ae) {
System.out.println("除数不能为0");
}
// 第二阶段
System.out.println("over");
}
======================================
4.二个异常的处理
* a:每一个写一个try...catch
* b:写一个try,多个catch
* try{
* ...
* }catch(异常类名 变量名) {
* ...
* }
* catch(异常类名 变量名) {
* ...
* }
* ...
*
* 注意事项:
* 1:能明确的尽量明确,不要用大的来处理。
* 2:平级关系的异常谁前谁后无所谓,如果出现了子父关系,父必须在后面。
// 爷爷在前面是不可以的

*
* 注意:
* 一旦try里面出了问题,就会在这里把问题给抛出去,然后和catch里面的问题进行匹配,
* 一旦有匹配的,就执行catch里面的处理,然后结束了try...catch
* 继续执行后面的语句
// 一个异常
public static void method1() {
// 第一阶段
int a = 10;
// int b = 2;
int b = 0;
try {
System.out.println(a / b);
} catch (ArithmeticException ae) {
System.out.println("除数不能为0");
}
// 第二阶段
System.out.println("over");

int a = 10;
int b = 0;
int[] arr = { 1, 2, 3 };
// 爷爷在最后
try {
System.out.println(a / b);
System.out.println(arr[3]);
System.out.println("这里出现了一个异常,你不太清楚是谁,该怎么办呢?");
} catch (ArithmeticException e) {
System.out.println("除数不能为0");
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("你访问了不该的访问的索引");
} catch (Exception e) {
System.out.println("出问题了");
}
5.JDK7针对多个异常的处理方案
JDK7出现了一个新的异常处理方案:
try{
}catch(异常名1 | 异常名2 | ... 变量 ) {
...
}
注意:这个方法虽然简洁,但是也不够好。
A:处理方式是一致的。(实际开发中,好多时候可能就是针对同类型的问题,给出同一个处理)
B:多个异常间必须是平级关系。
public static void main(String[] args) {
method();
}
public static void method() {
int a = 10;
int b = 0;
int[] arr = { 1, 2, 3 };
// try {
// System.out.println(a / b);
// System.out.println(arr[3]);
// System.out.println("这里出现了一个异常,你不太清楚是谁,该怎么办呢?");
// } catch (ArithmeticException e) {
// System.out.println("除数不能为0");
// } catch (ArrayIndexOutOfBoundsException e) {
// System.out.println("你访问了不该的访问的索引");
// } catch (Exception e) {
// System.out.println("出问题了");
// }
// JDK7的处理方案
try {
System.out.println(a / b);
System.out.println(arr[3]);
} catch (ArithmeticException | ArrayIndexOutOfBoundsException e) {
System.out.println("出问题了");
}
System.out.println("over");
}
6.编译期异常和运行期异常的区别
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
* 编译时异常和运行时异常的区别
* 编译期异常:Java程序必须显示处理,否则程序就会发生错误,无法通过编译
* 运行期异常:无需显示处理,也可以和编译时异常一样处理
*/
public class ExceptionDemo {
public static void main(String[] args) {
// int a = 10;
// int b = 0;
// if (b != 0) {
// System.out.println(a / b);
// }
String s = "2014-11-20";
// SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// Date d = sdf.parse(s);
try {
Date d = sdf.parse(s);
System.out.println(d);
} catch (ParseException e) {
// e.printStackTrace();
System.out.println("解析日期出问题了");
}
}
}
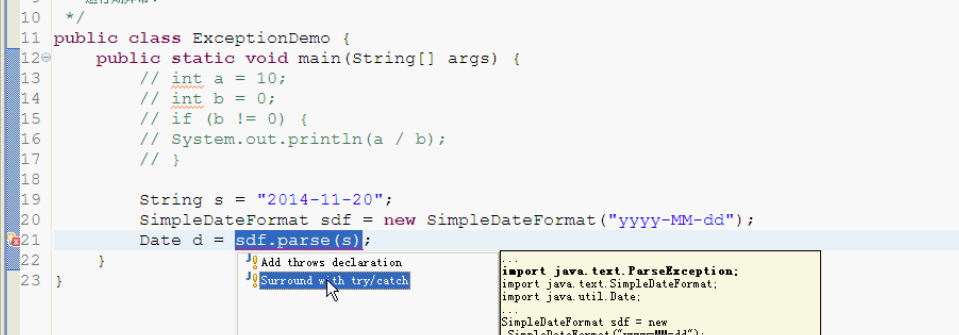
7.Throwable的几个常见方法
Throwable是Exception的父类,下面是子类调用父类的方法
在try里面发现问题后,jvm会帮我们生成一个异常对象,然后把这个对象抛出,和catch里面的类进行匹配。
如果该对象是某个类型的,就会执行该catch里面的处理信息。
异常中要了解的几个方法:
public String getMessage():异常的消息字符串
public String toString():返回异常的简单信息描述
此对象的类的 name(全路径名)
": "(冒号和一个空格)
调用此对象 getLocalizedMessage()方法的结果 (默认返回的是getMessage()的内容)
printStackTrace() 获取异常类名和异常信息,以及异常出现在程序中的位置。返回值void。把信息输出在控制台。
public static void main(String[] args) {
String s = "2014-11-20";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
Date d = sdf.parse(s); // 创建了一个ParseException对象,然后抛出去,和catch里面进行匹配
System.out.println(d);
} catch (ParseException e) { // ParseException e = new ParseException();
// ParseException
// e.printStackTrace();
// getMessage()
// System.out.println(e.getMessage());
// Unparseable date: "2014-11-20"
// toString()
// System.out.println(e.toString());
// java.text.ParseException: Unparseable date: "2014-11-20"
e.printStackTrace();
//跳转到某个指定的页面(index.html)
}
System.out.println("over");//注意这一句的作用
}
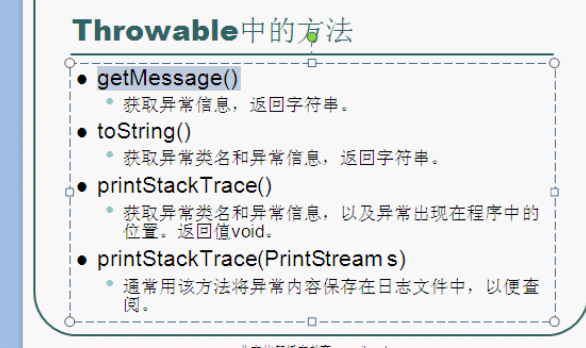
e.printStackTrace();的运行效果图

这跟我们平时运行报错时的信息差不多,但事实真的如此吗?不是的。
从上图可以看见,打出了报错信息后下面的语句还能执行(over已经打印出来了),
如果是平时运行报错时,下面的语句不会打印出来

8.throws的方式处理异常
定义功能方法时,需要把出现的问题暴露出来让调用者去处理。那么就通过throws在方法上标识。
有些时候,我们是可以对异常进行处理的,但是又有些时候,我们根本就没有权限去处理某个异常。
或者说,我处理不了,我就不处理了。
为了解决出错问题,Java针对这种情况,就提供了另一种处理方案:抛出。
格式:
throws 异常类名
注意:这个格式必须跟在方法的括号后面。
注意:
尽量不要在main方法上抛出异常。
但是为了讲课方便就这样做了。
public static void main(String[] args) {
System.out.println("今天天气很好");
try {
method();
} catch (ParseException e) {
e.printStackTrace();
}
System.out.println("但是就是不该有雾霾");
method2();
}
// 运行期异常的抛出
public static void method2() throws ArithmeticException {//这是运行时异常,其实这里的throws有点多余,可以去掉,也可以看见,调用method2的main方法不做任何反应也不会报错
int a = 10;
int b = 0;
System.out.println(a / b);
}
// 编译期异常的抛出
// 在方法声明上抛出,是为了告诉调用者(在上面的代码指的是main方法),你注意了,我有问题。(throws意味着扔给上一级处理,main方法中的throws意味着扔给虚拟机处理)
public static void method() throws ParseException {
String s = "2014-11-20";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse(s);
System.out.println(d);
}
try……catch可以继续执行最后一行代码

throws执行,忽略下面的代码
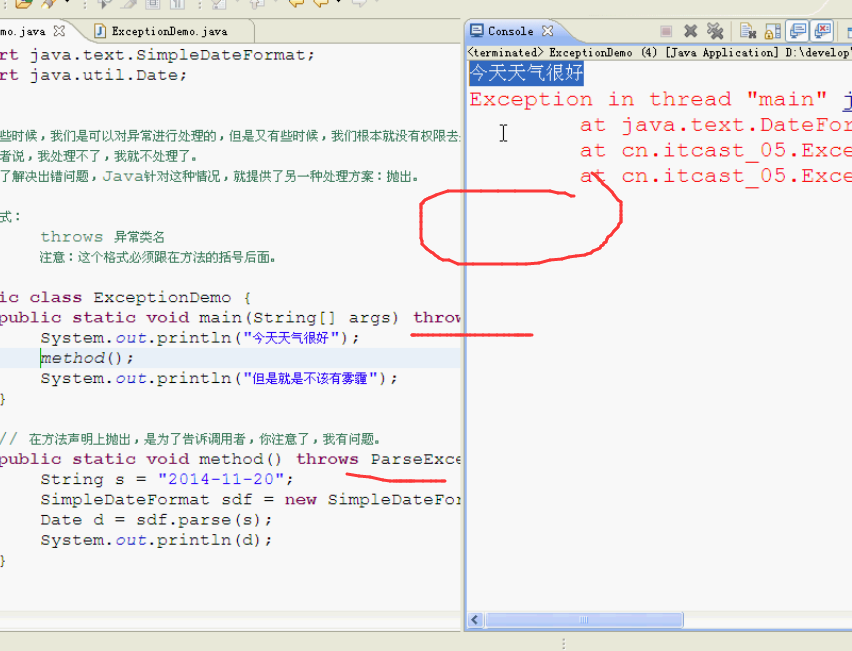
小结:
编译期异常抛出,将来调用者必须处理。
运行期异常抛出,将来调用可以不用处理。
注意:throws后面可以加多个异常名, throws Xxx,Xxx()
9.throw概述
throw:如果出现了异常情况,我们可以把该异常抛出,这个时候的抛出的应该是异常的对象。


public static void main(String[] args) {
// method();
try {
method2();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void method() {
int a = 10;
int b = 0;
if (b == 0) {
throw new ArithmeticException();//对于运行时异常,,method()并没有任何表示,没有throws任何东西
} else {
System.out.println(a / b);
}
}
public static void method2() throws Exception {
int a = 10;
int b = 0;
if (b == 0) {
throw new Exception();
} else {
System.out.println(a / b);
}
}

10.throws和throw的区别(面试题)
throws
用在方法声明后面,跟的是异常类名
可以跟多个异常类名,用逗号隔开
表示抛出异常,由该方法的调用者来处理
throws表示出现异常的一种可能性,并不一定会发生这些异常
throw
用在方法体内,跟的是异常对象名
只能抛出一个异常对象名
表示抛出异常,由方法体内的语句处理
throw则是抛出了异常,执行throw则一定抛出了某种异常。
11.实际如何用异常
注意:
在main方法中一般用try……catch来处理异常而不用throws

12.finally关键字

按照先前知识,可以进行如下改进

finally:被finally控制的语句体一定会执行
注意一个特殊情况:如果在执行到finally之前jvm退出了,就不能执行了。
A:格式
try...catch...finally...
B:用于释放资源,在IO流操作和数据库操作中会见到
public static void main(String[] args) {
String s = "2014-11-20";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = null;
try {
// System.out.println(10 / 0);
d = sdf.parse(s);
} catch (ParseException e) {
e.printStackTrace();
System.exit(0);//jvm退出了,下面的finally以及最后的打印d就都不能执行了
} finally {
System.out.println("这里的代码是可以执行的");
}
System.out.println(d);
}
13.3个面试题
面试题1:
1:final,finally和finalize的区别
final:最终的意思,可以修饰类,成员变量,成员方法
修饰类,类不能被继承
修饰变量,变量是常量
修饰方法,方法不能被重写
finally:是异常处理的一部分,用于释放资源。
一般来说,代码肯定会执行,特殊情况:在执行到finally之前jvm退出了
finalize:是Object类的一个方法,用于垃圾回收
面试题2:如果catch里面有return语句,请问finally里面的代码还会执行吗?
如果会,请问是在return前,还是return后。
会。前。
准确的说,应该是在中间。
3:try...catch...finally的格式变形
A:try...catch...finally
B:try...catch
C:try...catch...catch...
D:try...catch...catch...finally
E:try...finally
这种做法的目前是为了释放资源。
public static void main(String[] args) {
System.out.println(getInt());
}
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a在程序执行到这一步的时候,这里不是return a而是return 30;这个返回路径就形成了。
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的返回路径,继续走return 30;
*/
} finally {
a = 40;
return a;//如果这样结果就是40了。
}
// return a;
}
debug查看原因



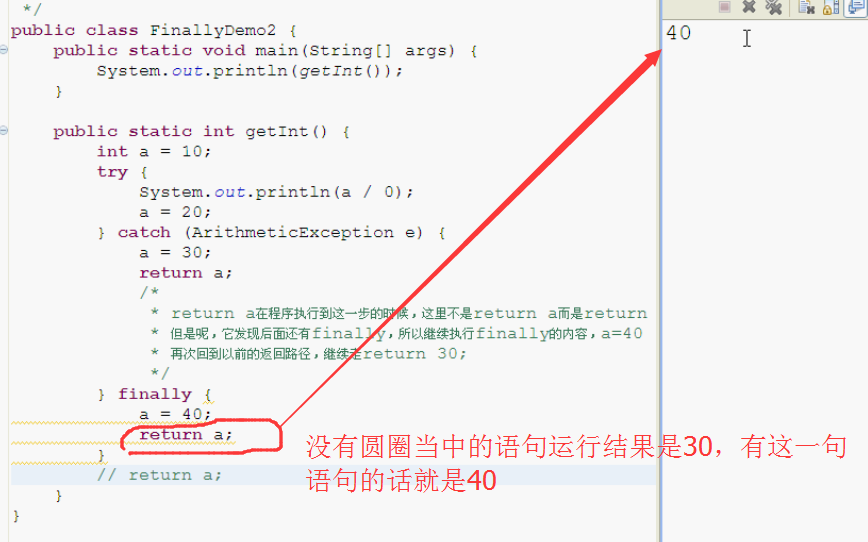
当然,上一幅图还有一个前提:就是注释掉最后那个return a;
14.自定义异常
分为两类 继承自Exception,
继承自RuntimeException
java不可能对所有的情况都考虑到,所以,在实际的开发中,我们可能需要自己定义异常。
而我们自己随意的写一个类,是不能作为异常类来看的,要想你的类是一个异常类,就必须继承自Exception或者RuntimeException
下面是示例
=================分割线============================
MyException.java
==============
public class MyException extends Exception {//这是编译异常,需要处理
public MyException() {
}
public MyException(String message) {
super(message);
}
}
==================分割线============================
Teacher.java
===========
public class Teacher {
public void check(int score) throws MyException {
if (score > 100 || score < 0) {
throw new MyException("分数必须在0-100之间");//需要打印的错误信息,利用了带参的构造方法
} else {
System.out.println("分数没有问题");
}
}
================分割线=============================
StudentDemo.java
============
import java.util.Scanner;
public class StudentDemo {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入学生成绩:");
int score = sc.nextInt();
Teacher t = new Teacher();
try {
t.check(score);
} catch (MyException e) {
e.printStackTrace();
}
}
}
====================分割线=====================
需要注意的是,自定义的异常类要继承Exception或者RuntimeException而且,自定义的异常类写起来非常容易,不需要写任何方法,只需要两个构造方法就可以了(为什么要写构造方法呢?原因是为了打印错误提示信息,如下图所示)


至于




public MyException(String message) {
super(message);
}
中super(message);具体是怎样实现的可以查看源码,以下为简略截图
15.异常的注意事项
A:子类重写父类方法时,子类的方法必须抛出相同的异常或父类异常的子类。(父亲坏了,儿子不能比父亲更坏)
下图报错

以下运行正常

B:如果父类抛出了多个异常,子类重写父类时,只能抛出相同的异常或者是他的子集,子类不能抛出父类没有的异常
C:如果被重写的方法没有异常抛出,那么子类的方法绝对不可以抛出异常,如果子类方法内有异常发生,那么子类只能try,不能throws。
改为Date d = null;即可
其实, 在要重写的方法加上 @Override eclipse会在自动识别重写的方法而没有throws 的选项,也就避免了上图的throws报错。
16.File类的概述
我们要想实现IO的操作,就必须知道硬盘上文件的表现形式。
而Java就提供了一个类File供我们使用。
File:文件和目录(文件夹)路径名的抽象表示形式。//并不代表一定存在
构造方法:
File(String pathname):根据一个路径得到File对象(一般用这个)
File(String parent, String child):根据一个目录和一个子文件/目录得到File对象(也就是说,parent是文件夹,child代表这个文件夹里面的文件或者子文件夹)
File(File parent, String child):根据一个父File对象和一个子文件/目录得到File对象
===============分割线============================
public static void main(String[] args) {
// File(String pathname):根据一个路径得到File对象
// 把e:\demo\a.txt封装成一个File对象
File file = new File("E:\demo\a.txt");
// File(String parent, String child):根据一个目录和一个子文件/目录得到File对象
File file2 = new File("E:\demo", "a.txt");
// File(File parent, String child):根据一个父File对象和一个子文件/目录得到File对象
File file3 = new File("e:\demo");
File file4 = new File(file3, "a.txt");
// 以上三种方式其实效果一样
}
==================分割线=======================
17.File类的创建功能
public boolean createNewFile():创建文件 如果存在这样的文件,就不创建了
public boolean mkdir():创建文件夹 如果存在这样的文件夹,就不创建了(只能一级一级的创建文件夹)
public boolean mkdirs():创建文件夹,如果父文件夹不存在,会帮你创建出来(可以快速创建多级文件夹)
骑白马的不一定是王子,可能是班长。(a.txt不一定是文本文件,它有可能是文件夹的名字)
注意:你到底要创建文件还是文件夹,你最清楚,方法不要调错了。
=============分割线=================================
public static void main(String[] args) throws IOException {
// 需求:我要在e盘目录下创建一个文件夹demo
File file = new File("e:\demo");
System.out.println("mkdir:" + file.mkdir());
// 需求:我要在e盘目录demo下创建一个文件a.txt
File file2 = new File("e:\demo\a.txt");
System.out.println("createNewFile:" + file2.createNewFile());
// 需求:我要在e盘目录test下创建一个文件b.txt(创建文件有可能抛异常,但是创建文件不会抛异常)
// Exception in thread "main" java.io.IOException: 系统找不到指定的路径。
// 注意:要想在某个目录下创建内容,该目录首先必须存在。
// File file3 = new File("e:\test\b.txt");
// System.out.println("createNewFile:" + file3.createNewFile());
// 需求:我要在e盘目录test下创建aaa目录
// File file4 = new File("e:\test\aaa");
// System.out.println("mkdir:" + file4.mkdir());
// File file5 = new File("e:\test");
// File file6 = new File("e:\test\aaa");
// System.out.println("mkdir:" + file5.mkdir());
// System.out.println("mkdir:" + file6.mkdir());
// 其实我们有更简单的方法
File file7 = new File("e:\aaa\bbb\ccc\ddd");
System.out.println("mkdirs:" + file7.mkdirs());
// 看下面的这个东西:
File file8 = new File("e:\liuyi\a.txt");
System.out.println("mkdirs:" + file8.mkdirs());
}
==================分割线==========================
注意:创建文件有可能抛异常,但是创建文件不会抛异常
查源码


想创建文件,但是却是文件夹
// 看下面的这个东西:
File file8 = new File("e:\liuyi\a.txt");
System.out.println("mkdirs:" + file8.mkdirs());
骑白马的不一定是王子,可能是班长。(a.txt不一定是文本文件,它有可能是文件夹的名字)

18.File类的删除功能
删除功能:public boolean delete()
注意:
A:如果你创建文件或者文件夹忘了写盘符路径,那么,默认在项目路径下。

注意,是项目路径下,而不是包目录下!

B:Java中的删除不走回收站。(删除后,回收站无记录保存)
C:要删除一个文件夹,请注意该文件夹内不能包含文件或者文件夹(也就是说,不能跨级删除文件夹)
19.File类的重命名功能---renameTo
重命名功能:public boolean renameTo(File dest)
如果路径名相同,就是改名。
如果路径名不同,就是改名并剪切。
路径以盘符开始:绝对路径 c:\a.txt
路径不以盘符开始:相对路径 a.txt
public static void main(String[] args) {
// 创建一个文件对象
// File file = new File("林青霞.jpg");
// // 需求:我要修改这个文件的名称为"东方不败.jpg"
// File newFile = new File("东方不败.jpg");
// System.out.println("renameTo:" + file.renameTo(newFile));
File file2 = new File("东方不败.jpg");
File newFile2 = new File("e:\林青霞.jpg");
System.out.println("renameTo:" + file2.renameTo(newFile2));
}
20.File类的判断功能
判断功能:
public boolean isDirectory():判断是否是目录
public boolean isFile():判断是否是文件
public boolean exists():判断是否存在
public boolean canRead():判断是否可读
public boolean canWrite():判断是否可写
public boolean isHidden():判断是否隐藏
===============分割线========================
public static void main(String[] args) {
// 创建文件对象
File file = new File("a.txt");
System.out.println("isDirectory:" + file.isDirectory());// false
System.out.println("isFile:" + file.isFile());// true
System.out.println("exists:" + file.exists());// true
System.out.println("canRead:" + file.canRead());// true
System.out.println("canWrite:" + file.canWrite());// true
System.out.println("isHidden:" + file.isHidden());// false
}
21.File类的获取功能
获取功能:
public String getAbsolutePath():获取绝对路径
public String getPath():获取相对路径
public String getName():获取名称
public long length():获取长度。字节数
public long lastModified():获取最后一次的修改时间,毫秒值
=================分割线=========================
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
public static void main(String[] args) {
// 创建文件对象
File file = new File("demo\test.txt");
System.out.println("getAbsolutePath:" + file.getAbsolutePath());
System.out.println("getPath:" + file.getPath());
System.out.println("getName:" + file.getName());
System.out.println("length:" + file.length());
System.out.println("lastModified:" + file.lastModified());
// 1416471971031
Date d = new Date(1416471971031L);//构造方法接收毫秒值
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String s = sdf.format(d);//转换
System.out.println(s);
}
注意Date构造方法接收毫秒值

运行示例(a.txt里面是字符串hello,所以5个字节)
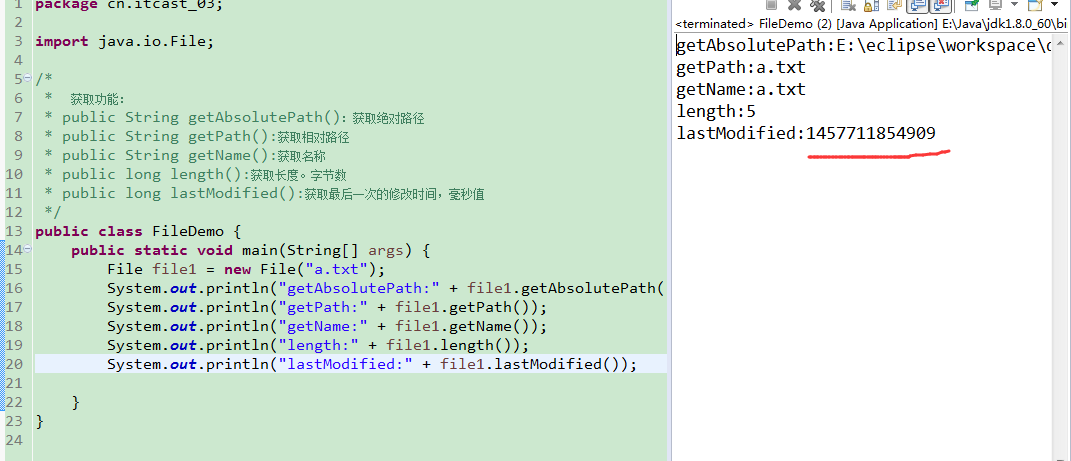
对lastModified进行format

不加L会报错:The literal 1457711854909 of type int is out of
range

22.File类的高级获取功能
获取功能:
public String[] list():获取指定目录下的所有文件或者文件夹的名称数组
public File[] listFiles():获取指定目录下的所有文件或者文件夹的File数组
================分割线====================
public static void main(String[] args) {
// 指定一个目录
File file = new File("e:\");
// public String[] list():获取指定目录下的所有文件或者文件夹的名称数组
String[] strArray = file.list();
for (String s : strArray) {
System.out.println(s);
}
System.out.println("------------");
// public File[] listFiles():获取指定目录下的所有文件或者文件夹的File数组
File[] fileArray = file.listFiles();
for (File f : fileArray) {
System.out.println(f.getName());
}
}
=================分割线==================

23.一个案例----输出指定目录下指定后缀名的文件名称
判断E盘目录下是否有后缀名为.jpg的文件,如果有,就输出此文件名称
分析:
A:封装e判断目录
B:获取该目录下所有文件或者文件夹的File数组

C:遍历该File数组,得到每一个File对象,然后判断
D:是否是文件
是:继续判断是否以.jpg结尾
是:就输出该文件名称
否:不搭理它
否:不搭理它
==================分割线==================
public static void main(String[] args) {
// 封装e判断目录
File file = new File("e:\");
// 获取该目录下所有文件或者文件夹的File数组
File[] fileArray = file.listFiles();
// 遍历该File数组,得到每一个File对象,然后判断
for (File f : fileArray) {
// 是否是文件
if (f.isFile()) {
// 继续判断是否以.jpg结尾
if (f.getName().endsWith(".jpg")) {
// 就输出该文件名称
System.out.println(f.getName());
}
}
}
}
==================分割线===================
该案例值得留意的地方:String类的endsWith方法
24关于上一个案例的反思:文件过滤器改进输出指定目录下指定后缀名的文件名称案例
接口 FilenameFilter
判断E盘目录下是否有后缀名为.jpg的文件,如果有,就输出此文件名称
* A:先获取所有的,然后遍历的时候,依次判断,如果满足条件就输出。
* B:获取的时候就已经是满足条件的了,然后输出即可。
*
* 要想实现这个效果,就必须学习一个接口:文件名称过滤器
* public String[] list(FilenameFilter filter)
* public File[] listFiles(FilenameFilter filter)
=====================================================
public static void main(String[] args) {
// 封装e判断目录
File file = new File("e:\");
// 获取该目录下所有文件或者文件夹的String数组
// public String[] list(FilenameFilter filter)
String[] strArray = file.list(new FilenameFilter() {//匿名内部类
//上面这个语句用String[]的原因是只需要获取文件(夹)名称
@Override
public boolean accept(File dir, String name) {
// return false;
// return true;
// 通过这个测试,我们就知道了,到底把这个文件或者文件夹的名称加不加到数组中,取决于这里的返回值是true还是false
// 所以,这个的true或者false应该是我们通过某种判断得到的
// System.out.println(dir + "---" + name);
// File file = new File(dir, name);//第三种构造方法
// // System.out.println(file);
// boolean flag = file.isFile();
// boolean flag2 = name.endsWith(".jpg");
// return flag && flag2;
return new File(dir, name).isFile() && name.endsWith(".jpg");//意思是接收的两个参数组成的文件能否是一个File而且这个文件是否以.jpg结尾
}
});
// 遍历
for (String s : strArray) {
System.out.println(s);
}
}
====================================================
查源码---带文件名称过滤器的list()方法的源码

24.批量修改文件名称案例
import java.io.File;
/*
* 需求:把E:评书三国演义下面的视频名称修改为
* 00?_介绍.avi
*
* 思路:
* A:封装目录
* B:获取该目录下所有的文件的File数组
* C:遍历该File数组,得到每一个File对象
* D:拼接一个新的名称,然后重命名即可。
*/
public class FileDemo {
public static void main(String[] args) {
// 封装目录
File srcFolder = new File("E:\评书\三国演义");
// 获取该目录下所有的文件的File数组
File[] fileArray = srcFolder.listFiles();
// 遍历该File数组,得到每一个File对象
for (File file : fileArray) {
// System.out.println(file);
// E:评书三国演义三国演义_001_[评书网-今天很高兴,明天就IO了]_桃园三结义.avi
// 改后:E:评书三国演义�01_桃园三结义.avi
String name = file.getName(); // 三国演义_001_[评书网-今天很高兴,明天就IO了]_桃园三结义.avi
int index = name.indexOf("_");
String numberString = name.substring(index + 1, index + 4);
// System.out.println(numberString);
// int startIndex = name.lastIndexOf('_');
// int endIndex = name.lastIndexOf('.');
// String nameString = name.substring(startIndex + 1, endIndex);
// System.out.println(nameString);
int endIndex = name.lastIndexOf('_');
String nameString = name.substring(endIndex);
String newName = numberString.concat(nameString); // 001_桃园三结义.avi
// System.out.println(newName);
File newFile = new File(srcFolder, newName); // E:\评书\三国演义\001_桃园三结义.avi
// 重命名即可
file.renameTo(newFile);
}
}
}
详细解析略
改名前
24.批量修改文件名称案例
import java.io.File;
/*
* 需求:把E:评书三国演义下面的视频名称修改为
* 00?_介绍.avi
*
* 思路:
* A:封装目录
* B:获取该目录下所有的文件的File数组
* C:遍历该File数组,得到每一个File对象
* D:拼接一个新的名称,然后重命名即可。
*/
public class FileDemo {
public static void main(String[] args) {
// 封装目录
File srcFolder = new File("E:\评书\三国演义");
// 获取该目录下所有的文件的File数组
File[] fileArray = srcFolder.listFiles();
// 遍历该File数组,得到每一个File对象
for (File file : fileArray) {
// System.out.println(file);
// E:评书三国演义三国演义_001_[评书网-今天很高兴,明天就IO了]_桃园三结义.avi
// 改后:E:评书三国演义�01_桃园三结义.avi
String name = file.getName(); // 三国演义_001_[评书网-今天很高兴,明天就IO了]_桃园三结义.avi
int index = name.indexOf("_");
String numberString = name.substring(index + 1, index + 4);
// System.out.println(numberString);
// int startIndex = name.lastIndexOf('_');
// int endIndex = name.lastIndexOf('.');
// String nameString = name.substring(startIndex + 1, endIndex);
// System.out.println(nameString);
int endIndex = name.lastIndexOf('_');
String nameString = name.substring(endIndex);
String newName = numberString.concat(nameString); // 001_桃园三结义.avi
// System.out.println(newName);
File newFile = new File(srcFolder, newName); // E:\评书\三国演义\001_桃园三结义.avi
// 重命名即可
file.renameTo(newFile);
}
}
}
详细解析略
改名前

运行程序,改名后

本人根据上面的思路重写了一个程序
import java.io.File;
/*
* 需求:把F:评书 下面的视频名称修改为
* 00?_第?节课.avi
*
* 思路:
* A:封装目录
* B:获取该目录下所有的文件的File数组
* C:遍历该File数组,得到每一个File对象
* D:拼接一个新的名称,然后重命名即可。
*/
public class FileDemo {
public static void main(String[] args) {
// 封装目录
File srcFolder = new File("F:\评书");
// 获取该目录下所有的文件的File数组
File[] files = srcFolder.listFiles();
// 遍历该File数组,得到每一个File对象
for (File f : files) {
String name = f.getName();
// 拼接一个新的名称,然后重命名即可
// 刘意_001_day19_第一节课.avi
int index = name.indexOf('_');
String nameString = name.substring(index + 1, index + 4);
// System.out.println(nameString);
int endIndex = name.lastIndexOf('_');
String endString = name.substring(endIndex);
// System.out.println(endString);
String newName = nameString.concat(endString);
File newFile = new File(srcFolder, newName);
f.renameTo(newFile);
}
}
}
运行前(目录在 F:评书 )

运行后

day19补充笔记
异常的处理:
A:JVM的默认处理
把异常的名称,原因,位置等信息输出在控制台,但是呢程序不能继续执行了。
B:自己处理
a:try...catch...finally
自己编写处理代码,后面的程序可以继续执行
b:throws
把自己处理不了的,在方法上声明,告诉调用者,这里有问题
day20
1.递归概述和注意事项
递归:方法定义中调用方法本身的现象
方法的嵌套调用,这不是递归。
Math.max(Math.max(a,b),c);
public void show(int n) {
if(n <= 0) {
System.exit(0);
}
System.out.println(n);
show(--n);
}
注意事项:
A:递归一定要有出口,否则就是死递归
B:递归的次数不能太多,否则就内存溢出
C:构造方法不能递归使用
举例:
A:从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚在给小和尚讲故事,故事是:
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚在给小和尚讲故事,故事是:
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚在给小和尚讲故事,故事是:
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚在给小和尚讲故事,故事是:
...
庙挂了,或者山崩了
2.递归求阶乘的代码实现及内存图解
需求:请用代码实现求5的阶乘。
下面的知识要知道:
5! = 1*2*3*4*5
5! = 5*4!
有几种方案实现呢?
A:循环实现
B:递归实现
a:做递归要写一个方法
b:出口条件
c:规律
public static void main(String[] args) {
int jc = 1;
for (int x = 2; x <= 5; x++) {
jc *= x;
}
System.out.println("5的阶乘是:" + jc);
System.out.println("5的阶乘是:"+jieCheng(5));
}
/*
* 做递归要写一个方法:
* 返回值类型:int
* 参数列表:int n
* 出口条件:
* if(n == 1) {return 1;}
* 规律:
* if(n != 1) {return n*方法名(n-1);}
*/
public static int jieCheng(int n){
if(n==1){
return 1;
}else {
return n*jieCheng(n-1);
}
}
递归求阶乘的代码实现及内存图解

debug

3.兔子-斐波那契
有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问第二十个月的兔子对数为多少?
递归实现
假如相邻的两个月的兔子对数是a,b
* 第一个相邻的数据:a=1,b=1
* 第二个相邻的数据:a=1,b=2
* 第三个相邻的数据:a=2,b=3
* 第四个相邻的数据:a=3,b=5
* 看到了:下一次的a是以前的b,下一次是以前的a+b
/*
* 方法: 返回值类型:int 参数列表:int n 出口条件: 第一个月是1,第二个月是1 规律: 从第三个月开始,每一个月是前两个月之和
*/
public static int fib(int n) {
if (n == 1 || n == 2) { //出口条件
return 1;
} else {
return fib(n - 1) + fib(n - 2);//规律
}
}
写递归考虑两步:1.出口条件(if……)
2.寻找规律
4.一个递归案例(File)--递归输出指定目录下所有的java文件的绝对路径案例
import java.io.File;
/*
* 需求:请大家把E:JavaSE目录下所有的java结尾的文件的绝对路径给输出在控制台。
*
* 分析:
* A:封装目录
* B:获取该目录下所有的文件或者文件夹的File数组
* C:遍历该File数组,得到每一个File对象
* D:判断该File对象是否是文件夹
* 是:回到B
* 否:继续判断是否以.java结尾
* 是:就输出该文件的绝对路径
* 否:不搭理它
*/
public class FilePathDemo {
public static void main(String[] args) {
// 封装目录
File srcFolder = new File("E:\JavaSE");
// 递归功能实现
getAllJavaFilePaths(srcFolder);
}
private static void getAllJavaFilePaths(File srcFolder) {
// 获取该目录下所有的文件或者文件夹的File数组
File[] fileArray = srcFolder.listFiles();
// 遍历该File数组,得到每一个File对象
for (File file : fileArray) {
// 判断该File对象是否是文件夹
if (file.isDirectory()) {
getAllJavaFilePaths(file);
} else {
// 继续判断是否以.java结尾
if (file.getName().endsWith(".java")) {
// 就输出该文件的绝对路径
System.out.println(file.getAbsolutePath());
}
}
}
}
}
注意:注意file的isDirectory()方法和getAbsolutePath()方法
===========================
本人据此模仿了一个
import java.io.File;
/*
* 获取G:\迅雷下载分区中所有以.java为后缀的文件
*/
public class FilePathDemo {
public static void main(String[] args) {
// 封装文件目录
File srcFolder = new File("G:\迅雷下载分区");
getJavaFilePaths(srcFolder);
}
private static void getJavaFilePaths(File srcFolder) {
// 获取file数组
File[] fileArray = srcFolder.listFiles();
// 遍历file对象
for (File f : fileArray) {
// 判断是否为文件夹
if (f.isDirectory()) {
getJavaFilePaths(f);
} else {
if (f.getName().endsWith(".java")) {
System.out.println(new File(srcFolder, f.getName()));
// System.out.println(f.getAbsolutePath());
}
}
}
}
}
==============================

运行示例


5. 递归案例---递归删除带内容的目录
import java.io.File;
/*
* 需求:递归删除带内容的目录
*
* 目录我已经给定:demo
*
* 分析:
* A:封装目录
* B:获取该目录下的所有文件或者文件夹的File数组
* C:遍历该File数组,得到每一个File对象
* D:判断该File对象是否是文件夹
* 是:回到B
* 否:就删除
*/
public class FileDeleteDemo {
public static void main(String[] args) {
// 封装目录
File srcFolder = new File("demo");
// 递归实现
deleteFolder(srcFolder);
}
private static void deleteFolder(File srcFolder) {
// 获取该目录下的所有文件或者文件夹的File数组
File[] fileArray = srcFolder.listFiles();
// 遍历该File数组,得到每一个File对象
for (File file : fileArray) {
// 判断该File对象是否是文件夹
if (file.isDirectory()) {
deleteFolder(file);
} else {
System.out.println(file.getName() + "---" + file.delete());
}
System.out.println(srcFolder.getName() + "---" + srcFolder.delete());//没有这一句,删不了文件夹
}
}
}

6.IO流概述及分类
IO流的分类

如何判断使用字节流还是字符流呢?
用记事本打开判断,能读懂就可以用字符流,读不懂就可以用字节流
打开一个图片文件

打开一个java文件

7.IO流基类概述
IO流的分类:
* 流向:
* 输入流 读取数据
* 输出流 写出数据
* 数据类型:
* 字节流
* 字节输入流 读取数据 InputStream
* 字节输出流 写出数据 OutputStream
* 字符流
* 字符输入流 读取数据 Reader
* 字符输出流 写出数据 Writer
*
* 注意:一般我们在探讨IO流的时候,如果没有明确说明按哪种分类来说,默认情况下是按照数据类型来分的。
InputStream:此抽象类是表示字节输入流的所有类的超类。
OutputStream:此抽象类是表示输出字节流的所有类的超类。输出流接受输出字节并将这些字节发送到某个接收器。
Reader:用于读取字符流的抽象类。子类必须实现的方法只有 read(char[], int, int) 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
Writer:写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
8.FileOutputStream的构造方法
FileOutputStream的构造方法:
FileOutputStream(File file)
FileOutputStream(String name)
几个注意问题:
需求:我要往一个文本文件中输入一句话:"hello,io"
*
* 分析:
* A:这个操作最好是采用字符流来做,但是呢,字符流是在字节流之后才出现的,所以,今天我先讲解字节流如何操作。
* B:由于我是要往文件中写一句话,所以我们要采用字节输出流。
*
* 通过上面的分析后我们知道要使用:OutputStream
* 但是通过查看API,我们发现该流对象是一个抽象类,不能实例化。
* 所以,我们要找一个具体的子类。
* 而我们要找的子类是什么名字的呢?这个时候,很简单,我们回想一下,我们是不是要往文件中写东西。
* 文件是哪个单词:File
* 然后用的是字节输出流,联起来就是:FileOutputStream
* 注意:每种基类的子类都是以父类名作为后缀名。
* XxxOutputStream
* XxxInputStream
* XxxReader
* XxxWriter

留意以下代码
创建字节输出流对象
//FileOutputStream(File file)
File file = new File("fos.txt");
FileOutputStream fos = new FileOutputStream(file);
//FileOutputStream(String name)
FileOutputStream fos = new FileOutputStream("fos.txt");//这一句等价于上面的两句
原因如下

FileOutputStream(String name)这个构造方法虽然传的是字符串,但是底层实现实际上帮你封装了文件目录
因此这个构造方法可以实现
File file = new File("fos.txt");
FileOutputStream fos = new FileOutputStream(file);
这两行的功能
接着
FileOutputStream fos = new FileOutputStream("fos.txt");
/*
* 创建字节输出流对象了做了几件事情:
* A:调用系统功能去创建文件(即使这个文件不存在,也会创建一个新的)
* B:创建fos对象
* C:把fos对象指向这个文件
*/

//写数据
fos.write("hello,IO".getBytes());
fos.write("java".getBytes());//getBytes()是String类的一个方法,返回值是byte[ ]

//释放资源
//关闭此文件输出流并释放与此流有关的所有系统资源。
fos.close();
/*
* 为什么一定要close()呢?
* A:让流对象变成垃圾,这样就可以被垃圾回收器回收了
* B:通知系统去释放跟该文件相关的资源//这句话非常重要
*/
//java.io.IOException: Stream Closed//流关闭了就不可以读写数据了
//fos.write("java".getBytes());
总结:字节输出流操作步骤:
A:创建字节输出流对象
B:写数据
C:释放资源
9.FileOutputStream的三个write()方法
public void write(int b):写一个字节
public void write(byte[] b):写一个字节数组
public void write(byte[] b,int off,int len):写一个字节数组的一部分
public static void main(String[] args) throws IOException {
// 创建字节输出流对象
// OutputStream os = new FileOutputStream("fos2.txt"); // 多态
FileOutputStream fos = new FileOutputStream("fos2.txt");
// 调用write()方法
//fos.write(97); //97 -- 底层二进制数据 -- 通过记事本打开 -- 找97对应的字符值 -- a
// fos.write(57);//输出9
// fos.write(55);//输出7
//public void write(byte[] b):写一个字节数组
byte[] bys={97,98,99,100,101};//输出abcde
fos.write(bys);
//public void write(byte[] b,int off,int len):写一个字节数组的一部分
fos.write(bys,1,3);//输出bcd
//释放资源
fos.close();
}
10.FileOutputStream写出数据实现换行和追加写入
如何实现数据的换行?
代码
public static void main(String[] args) throws IOException {
// 创建字节输出流对象
FileOutputStream fos = new FileOutputStream("fos3.txt");
// 写数据
for (int x = 0; x < 10; x++) {
fos.write(("hello" + x).getBytes());
fos.write("
".getBytes());
}
// 释放资源
fos.close();
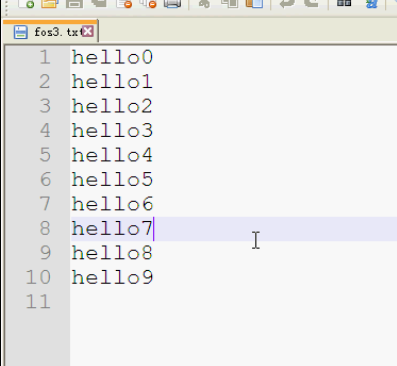
}
如果没有这一句 fos.write("
".getBytes()); 就不能换行
为什么现在没有换行呢?因为你值写了字节数据,并没有写入换行符号。
如何实现呢?写入换行符号即可呗。
fos.write("
".getBytes()); 加上这一句
运行如下
用notepad++打开
用windows自带的记事本打开
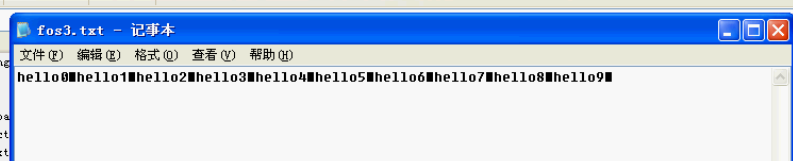
刚才我们看到了有写文本文件打开是可以的,通过windows自带的那个不行,为什么呢?
因为不同的系统针对不同的换行符号识别是不一样的?
windows:
linux:
Mac:
而一些常见的个高级记事本,是可以识别任意换行符号的。
因此,在windows下,只能改写
// 写数据
for (int x = 0; x < 10; x++) {
fos.write(("hello" + x).getBytes());
fos.write("
".getBytes());
}
再次用windows记事本打开

OK
然而还有一个问题,以上的每次运行程序(无论运行多少次),只会重新写进10行hello(也就是永远只有10行hello),而不会在后面追加数据。
来看看API

查看第2个

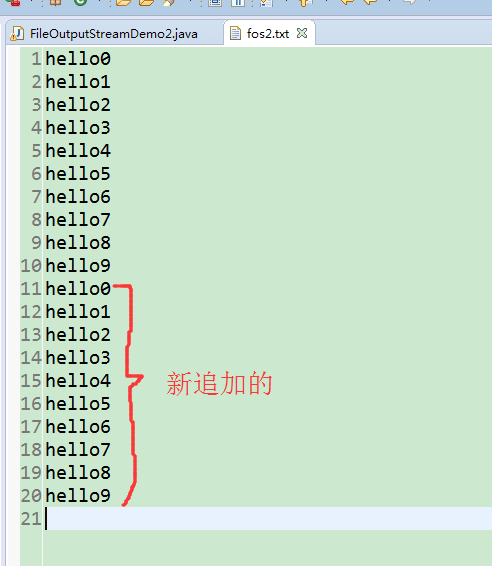
如何实现数据的追加写入?
用构造方法带第二个参数是true的情况即可
FileOutputStream fos = new FileOutputStream("fos3.txt", true);
运行效果如下(运行两次)
11.FileOutputStream写出数据加入异常处理
代码不再用throws来处理,如果用try……catch处理的话
效果如下

很明显,代码太累赘,不好看
改进一下
一起做异常处理
try {
FileOutputStream fos = new FileOutputStream("fos4.txt");
fos.write("java".getBytes());
fos.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
fos.close();位置不太对,因此再改进(还进行了几处修改)
// 改进版
// 为了在finally里面能够看到该对象就必须定义到外面,为了访问不出问题,还必须给初始化值
FileOutputStream fos = null;
try {
// fos = new FileOutputStream("z:\fos4.txt");//这是测试代码,为了验证空指针异常
fos = new FileOutputStream("fos4.txt");
fos.write("java".getBytes());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 如果fos不是null,才需要close()
if (fos != null) {
// 为了保证close()一定会执行,就放到这里了
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
解析一下
加finally 是为了保证fos.close()的正常执行;
FileOutputStream fos = null 这语句是为了初始化,否则finally语句的fos对象识别不了。
if (fos != null) {}这个if语句是为了防止创建文件不成功而抛出空指针异常

最终代码就是(try……catch有嵌套,第二个try……catch还嵌套有if语句)
public static void main(String[] args) {
// 改进版
FileOutputStream fos = null;
try {
fos = new FileOutputStream("fos4.txt");
fos.write("java".getBytes());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

写了这么多,最后输出的是:java
12.FileInputStream读取数据
字节输入流操作步骤:
A:创建字节输入流对象
B:调用read()方法读取数据,并把数据显示在控制台
C:释放资源
读取数据的方式:
A:int read():一次读取一个字节
B:int read(byte[] b):一次读取一个字节数组
=======================================
// 调用read()方法读取数据,并把数据显示在控制台
// // 第一次读取
// int by = fis.read();
// System.out.println(by);
// System.out.println((char) by);
//
// // 第二次读取
// by = fis.read();
// System.out.println(by);
// System.out.println((char) by);

========================================
当文件数据读完的时候,返回值统一变为-1
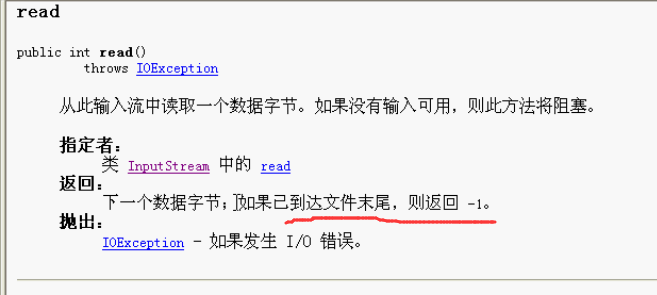
也就是说,如果你读取的数据是-1,就说明已经读取到文件的末尾了。
// 用循环改进
// int by = fis.read();
// while (by != -1) {
// System.out.print((char) by);
// by = fis.read();
// }
=================分割线=======================
// 最终版代码
int by = 0;
// 读取,赋值,判断
while ((by = fis.read()) != -1) {
System.out.print((char) by);
}
// 释放资源
fis.close();
=============分割线===========================
上面的代码解析一下,用print而不用println的原因是避免人为的引入换行符
13.字节流复制文本文件案例1
举例:
数据源:从哪里来
a.txt -- 读取数据 -- FileInputStream
目的地:到哪里去
b.txt -- 写数据 -- FileOutputStream
注意:读文件的话,那个文件一定要存在
把数据写入文件的话,那个文件可以不存在(自动创建)
也就是说,a.txt一定要先前存在,而b.txt不一定先前存在,可以在运行时期再创建
这一次复制中文没有出现任何问题,为什么呢?
上一次我们出现问题的原因在于我们每次获取到一个字节数据,就把该字节数据转换为了字符数据,然后输出到控制台。
上一次 int by = 0;
// 读取,赋值,判断
while ((by = fis.read()) != -1) {
System.out.print((char) by);
}
而这一次呢?确实通过IO流读取数据,写到文本文件,你读取一个字节,我就写入一个字节,你没有做任何的转换。它会自己做转换。
public static void main(String[] args) throws IOException {
// 封装数据源
FileInputStream fis = new FileInputStream("a.txt");
// 封装目的地
FileOutputStream fos = new FileOutputStream("b.txt");
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
// 释放资源(先关谁都行)
fos.close();
fis.close();
}
补充:计算机是如何识别什么时候该把两个字节转换为一个中文呢?
一个小demo
import java.util.Arrays;
/*
* 计算机是如何识别什么时候该把两个字节转换为一个中文呢?
* 在计算机中中文的存储分两个字节:
* 第一个字节肯定是负数。
* 第二个字节常见的是负数,可能有正数。但是没影响。
*/
public class StringDemo {
public static void main(String[] args) {
// String s = "abcde";
// // [97, 98, 99, 100, 101]
String s = "我爱你中国";
// [-50, -46, -80, -82, -60, -29, -42, -48, -71, -6]
byte[] bys = s.getBytes();
System.out.println(Arrays.toString(bys));
}
}
也就是说,我爱你中国--------
"我"对应[-50,-46],
"爱"对应[-80,-82]
"你"对应[-60,-29],
"中"对应[-42,-28]
"国"对应[-71,-6]
也就是说,如果是中文的话,第一个字节都是负数,第二个有可能是正的有可能是负的,但不影响,反正第一个是负的就拼接两个字节
14.字节流复制文本文件案例2
需求:把c盘下的a.txt的内容复制到d盘下的b.txt中
数据源:
c:\a.txt -- 读取数据-- FileInputStream
目的地:
d:\b.txt -- 写出数据 -- FileOutputStream
=================================================
public static void main(String[] args) throws IOException {
// 封装数据源
FileInputStream fis = new FileInputStream("c:\a.txt");
// 封装目的地
FileOutputStream fos = new FileOutputStream("d:\b.txt");
// 复制数据
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
// 释放资源
fos.close();
fis.close();
}
=================================================
15.字节流复制图片案例
需求:把e:\林青霞.jpg内容复制到当前项目目录下的mn.jpg中
数据源:
e:\林青霞.jpg --读取数据--FileInputStream
目的地:
mn.jpg--写出数据--FileOutputStream
=====================================
public static void main(String[] args) throws IOException {
// 封装数据源
FileInputStream fis = new FileInputStream("e:\林青霞.jpg");
// 封装目的地
FileOutputStream fos = new FileOutputStream("mn.jpg");
// 复制数据
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
// 释放资源
fos.close();
fis.close();
}
==========================================
16.字节流复制视频案例1(复制速度非常,非常的慢,一个一个字节复制)
需求:把e:\哥有老婆.mp4复制到当前项目目录下的copy.mp4中
数据源:
e:\哥有老婆.mp4--读取数据--FileInputStream
目的地:
copy.mp4--写出数据--FileOutputStream
=========================================
public static void main(String[] args) throws IOException {
// 封装数据源
FileInputStream fis = new FileInputStream("e:\哥有老婆.mp4");
// 封装目的地
FileOutputStream fos = new FileOutputStream("copy.mp4");
// 复制数据
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
// 释放资源
fos.close();
fis.close();
}
======================================
17.FileInputStream读取数据一次一个字节数组
一次读取一个字节数组:int read(byte[] b)
下图
FileInputStream的read方法

再附上:InputStream的read方法

创建字节输入流对象
FileInputStream fis = new FileInputStream("fis2.txt");
fis2.txt里面的内容(注意java后面没有换行符了)

// 读取数据

再进行第3,次第4次的读取
发现有如下的疑问

原因

(上图(
j)b……的b去掉,为多余)
为防止上面的问题,可以采取如下方法

输出

因此,最终版代码
==================分割线==================
FileInputStream fis = new FileInputStream("FileOutputStreamDemo.java");
// 最终版代码
// 数组的长度一般是1024或者1024的整数倍
byte[] bys = new byte[1024];
int len = 0;
while ((len = fis.read(bys)) != -1) {
System.out.print(new String(bys, 0, len));//print不要写成println
}
// 释放资源
fis.close();
===============分割线========================
注意:一定要用new String(bys,0,length); 而不能用new String(bys)!

byte[] bys = new byte[1024]; 这个数组默认的值都为0
len的值为实际读取的字节数(如果是-1意味着到结尾了)
18.FileInputStream读取数据的两种方式比较图解

一次读取一个字节数组---每次可以读取多个数据,提高了操作效率
19.BufferedOutputStream写出数据
通过定义数组的方式确实比以前一次读取一个字节的方式快很多,所以,看来有一个缓冲区还是非常好的。
既然是这样的话,那么,java开始在设计的时候,它也考虑到了这个问题,就专门提供了带缓冲区的字节类。
这种类被称为:缓冲区类(高效类)
写数据:BufferedOutputStream
读数据:BufferedInputStream
构造方法可以指定缓冲区的大小,但是我们一般用不上,因为默认缓冲区大小就足够了。

public static void main(String[] args) throws IOException {
// BufferedOutputStream(OutputStream out)
// FileOutputStream fos = new FileOutputStream("bos.txt");
// BufferedOutputStream bos = new BufferedOutputStream(fos);
// 简单写法
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("bos.txt"));
// 写数据
bos.write("hello".getBytes());
// 释放资源,注意,并不需要fos.close( );
bos.close();
}
======================================
为什么不传递一个具体的文件或者文件路径,而是传递一个OutputStream对象呢?
原因很简单,字节缓冲区流仅仅提供缓冲区,为高效而设计的。但是呢,真正的读写操作还得靠基本的流对象实现。

20.BufferedInputStream读取数据
注意:虽然我们有两种方式可以读取,但是,请注意,这两种方式针对同一个对象在一个代码中只能使用一个。
public static void main(String[] args) throws IOException {
// BufferedInputStream(InputStream in)
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(
"bos.txt"));
// 读取数据
// int by = 0;
// while ((by = bis.read()) != -1) {
// System.out.print((char) by);
// }
// System.out.println("---------");
byte[] bys = new byte[1024];
int len = 0;
while ((len = bis.read(bys)) != -1) {
System.out.print(new String(bys, 0, len));
}
// 释放资源
bis.close();
}
21.字节流四种方式复制MP4并测试效率
需求:把e:\哥有老婆.mp4复制到当前项目目录下的copy.mp4中
字节流四种方式复制文件
基本字节流一次读写一个字节
基本字节流一次读写一个字节数组
高效字节流一次读写一个字节
高效字节流一次读写一个字节数组
=================分割线==========================
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
//中间4个方法一个一个测试并注释掉其它的方法
// method1("e:\哥有老婆.mp4", "copy1.mp4");
// method2("e:\哥有老婆.mp4", "copy2.mp4");
// method3("e:\哥有老婆.mp4", "copy3.mp4");
method4("e:\哥有老婆.mp4", "copy4.mp4");
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - start) + "毫秒");
}
// 高效字节流一次读写一个字节数组:
public static void method4(String srcString, String destString)
throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(
srcString));
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream(destString));
byte[] bys = new byte[1024];
int len = 0;
while ((len = bis.read(bys)) != -1) {
bos.write(bys, 0, len);
}
bos.close();
bis.close();
}
// 高效字节流一次读写一个字节:
public static void method3(String srcString, String destString)
throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(
srcString));
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream(destString));
int by = 0;
while ((by = bis.read()) != -1) {
bos.write(by);
}
bos.close();
bis.close();
}
// 基本字节流一次读写一个字节数组
public static void method2(String srcString, String destString)
throws IOException {
FileInputStream fis = new FileInputStream(srcString);
FileOutputStream fos = new FileOutputStream(destString);
byte[] bys = new byte[1024];
int len = 0;
while ((len = fis.read(bys)) != -1) {
fos.write(bys, 0, len);
}
fos.close();
fis.close();
}
// 基本字节流一次读写一个字节
public static void method1(String srcString, String destString)
throws IOException {
FileInputStream fis = new FileInputStream(srcString);
FileOutputStream fos = new FileOutputStream(destString);
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
fos.close();
fis.close();
}
====================分割线==================
字节流四种方式复制文件运行结果:
* 基本字节流一次读写一个字节: 共耗时:117235毫秒
* 基本字节流一次读写一个字节数组: 共耗时:156毫秒
* 高效字节流一次读写一个字节: 共耗时:1141毫秒
* 高效字节流一次读写一个字节数组: 共耗时:47毫秒
22.仿照上一个案例
本人模仿了一个
下面是用于测试的文件f4v(9.14M)
代码如下
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/*
* 需求:把f:\测试视频.f4v复制到当前项目目录下的copy.f4v中
*
* 字节流四种方式复制文件:
* 基本字节流一次读写一个字节
* 基本字节流一次读写一个字节数组
* 高效字节流一次读写一个字节
* 高效字节流一次读写一个字节数组
*/
public class CopyF4VDemo {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
//method1("f:\测试视频.f4v", "copy1.f4v");
//method2("f:\测试视频.f4v", "copy2.f4v");
//method3("f:\测试视频.f4v", "copy3.f4v");
method4("f:\测试视频.f4v", "copy4.f4v");
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - start) + "毫秒");
}
public static void method4(String srcStirng, String desString) throws IOException {
// 高效字节流一次读写一个字节数组:
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcStirng));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(desString));
int len = 0;
byte[] bys = new byte[1024];
while ((len = bis.read(bys)) != -1) {
bos.write(bys, 0, len);
}
bis.close();
bos.close();
}
public static void method3(String srcStirng, String desString) throws IOException {
// 高效字节流一次读写一个字节:
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcStirng));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(desString));
int by = 0;
while ((by = bis.read()) != -1) {
bos.write(by);
}
bis.close();
bos.close();
}
public static void method2(String srcStirng, String desString) throws IOException {
// 基本字节流一次读写一个字节数组:
FileInputStream fis = new FileInputStream(srcStirng);
FileOutputStream fos = new FileOutputStream(desString);
byte[] bys = new byte[1024];
int len = 0;
while ((len = fis.read(bys)) != -1) {
fos.write(bys, 0, len);
}
fis.close();
fos.close();
}
public static void method1(String srcStirng, String desString) throws IOException {
// 基本字节流一次读写一个字节:
FileInputStream fis = new FileInputStream(srcStirng);
FileOutputStream fos = new FileOutputStream(desString);
int by = 0;
while ((by = fis.read()) != -1) {
fos.write(by);
}
fis.close();
fos.close();
}
}
=====================================
运行截图(逐个运行)




项目路径下(E:eclipseworkspaceday20_IO)有新复制的文件

总结:
字节流四种方式复制文件:
基本字节流一次读写一个字节: 共耗时:27348毫秒
基本字节流一次读写一个字节数组:共耗时:121毫秒
高效字节流一次读写一个字节: 共耗时:361毫秒
高效字节流一次读写一个字节数组: 共耗时:14毫秒
day20笔记补充
IO流分类
字节流:
InputStream
FileInputStream
BufferedInputStream
OutputStream
FileOutputStream
BufferedOutputStream
字符流:
Reader
FileReader
BufferedReader
Writer
FileWriter
BufferedWriter