boot接入elasticsearch
参考博客:https://blog.csdn.net/li521wang/article/details/83792552
项目源码demo:https://github.com/huanghuizhou/elasticsearch-demo
1 es相关安装
1.1 elasticsearch 安装
zip下载地址 https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-4-2
es不支持root用户启动,创建es用户在bin下启动es
#创建用户并设置密码
useradd esuser -p espassword
#给esuser用户授权
chown -R esuser:esgroup /usr/local/elasticsearch-6.2.4
#切换用户
su esuser
#启动es
./elasticsearch
1.2 es analyzer-ik 中文分词安装
命令行安装 ,下载完后移到/plugins/analyzer-ik 目录。若没有analyzer-ik 目录手动新建。
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.2/elasticsearch-analysis-ik-6.4.2.zip
直接下载ziphttps://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.2/elasticsearch-analysis-ik-6.4.2.zip 手动解压到/plugins/analyzer-ik 目录
安装完后重启 es
1.3 elasticsearch-head 安装
由于head插件本质上还是一个nodejs的工程,因此需要安装node,使用npm来安装依赖的包。
下载head插件
git clone https://github.com/mobz/elasticsearch-head.git
npm 初始化并启动
npm install
npm install -g grunt --registry=https://registry.npm.taobao.org
npm run start
修改es配置文件,支持跨域访问,在config/elasticseach.yml下新增。
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
重启es,然后访问 localhost:9100。如下图所示:

1.4 使用logstash 实现mysql与es同步
下载zip https://artifacts.elastic.co/downloads/logstash/logstash-6.4.2.tar.gz
在myes目录下新建 mysql.conf
input {
stdin {
}
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "123456"
# 驱动
jdbc_driver_library => "/Users/logstash-6.4.2/myes/mysql-connector-java-5.1.40.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
statement_filepath => "/Users/logstash-6.4.2/myes/user.sql"
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "doc"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "testindex"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
在myes目录下新建 test.sql
SELECT
*
FROM
test
把mysql-connector-java-5.1.40.jar 包放到myes下。
然后启动logstash
./logstash -f ../myes/mysql.conf
数据如图所示
2 es常用查询手册
match
字段全文搜索
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-match-query.html
{
"query": {
"match": {
"name": "3c product"
}
}
}
match_phrase
整词完全匹配
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-match-query-phrase.html
{
"query": {
"match_phrase": {
"name": "Shanghai HB"
}
}
}
match_phrase_prefix
单词前缀匹配(不是字段前缀)
{
"query": {
"match_phrase_prefix": {
"name": "Advert"
}
}
}
multi_match
多字段匹配
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-multi-match-query.html
{
"query": {
"multi_match": {
"query": "shenzhen led",
"fields": [
"name^2",
"business_scope^4",
"registration_location"
]
}
}
}
fuzzy
单词模糊匹配,根据字符串编辑距离https://www.cnblogs.com/BlackStorm/p/5400809.html
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-fuzzy-query.html
{
"query": {
"fuzzy": {
"name": {
"value": "produtc",
"fuzziness": "AUTO"
}
}
}
}
term
精确匹配
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-term-query.html
{
"query": {
"term": {
"year_established": 2001
}
}
}
term精确匹配,在对某些被全文索引的字段匹配时,由于字段被分词器分过词,词组被分割,有时候没法精确匹配到比如"input string"这个词,会被分词器分成input和string两个词存储在索引里,term就没法通过"input string"搜索到,因为索引里没有"input string",只有input和string
bool
组合条件查询
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-bool-query.html
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Shenzhen"
}
},
{
"term": {
"year_established": "2001"
}
}
]
}
}
}
- and => must
- or => should
- not => must_not
function_score
自定义评分规则
https://www.elastic.co/guide/en/elasticsearch/reference/master/query-dsl-function-score-query.html
{
"query": {
"function_score": {
"query": {
"match": {
"name": "shenzhen product"
}
},
"functions": [
{
"field_value_factor": {
"field": "num_viewed",
"modifier": "log1p",
"factor": "1"
}
},
{
"field_value_factor": {
"field": "level",
"modifier": "square",
"factor": "10"
}
}
]
}
}
}
相关度控制: http://wiki.great-tao.com/xwiki/bin/view/Main/JAVA开发/公共资源说明/Elasticsearch/相关度控制/
highlight
返回结果高亮
https://www.elastic.co/guide/en/elasticsearch/reference/master/search-request-highlighting.html
{
"query": {
"fuzzy": {
"name": {
"value": "produtc",
"fuzziness": "AUTO"
}
}
},
"_source": [
"name"
],
"highlight": {
"pre_tags": "<em>",
"post_tags": "</em>",
"fields": {
"name": {}
}
}
}
附录
- 23种非常有用的ElasticSearch查询例子: https://www.iteblog.com/archives/1741.html
3 项目demo
项目源码demo:https://github.com/huanghuizhou/elasticsearch-demo
swagger-ui如下图
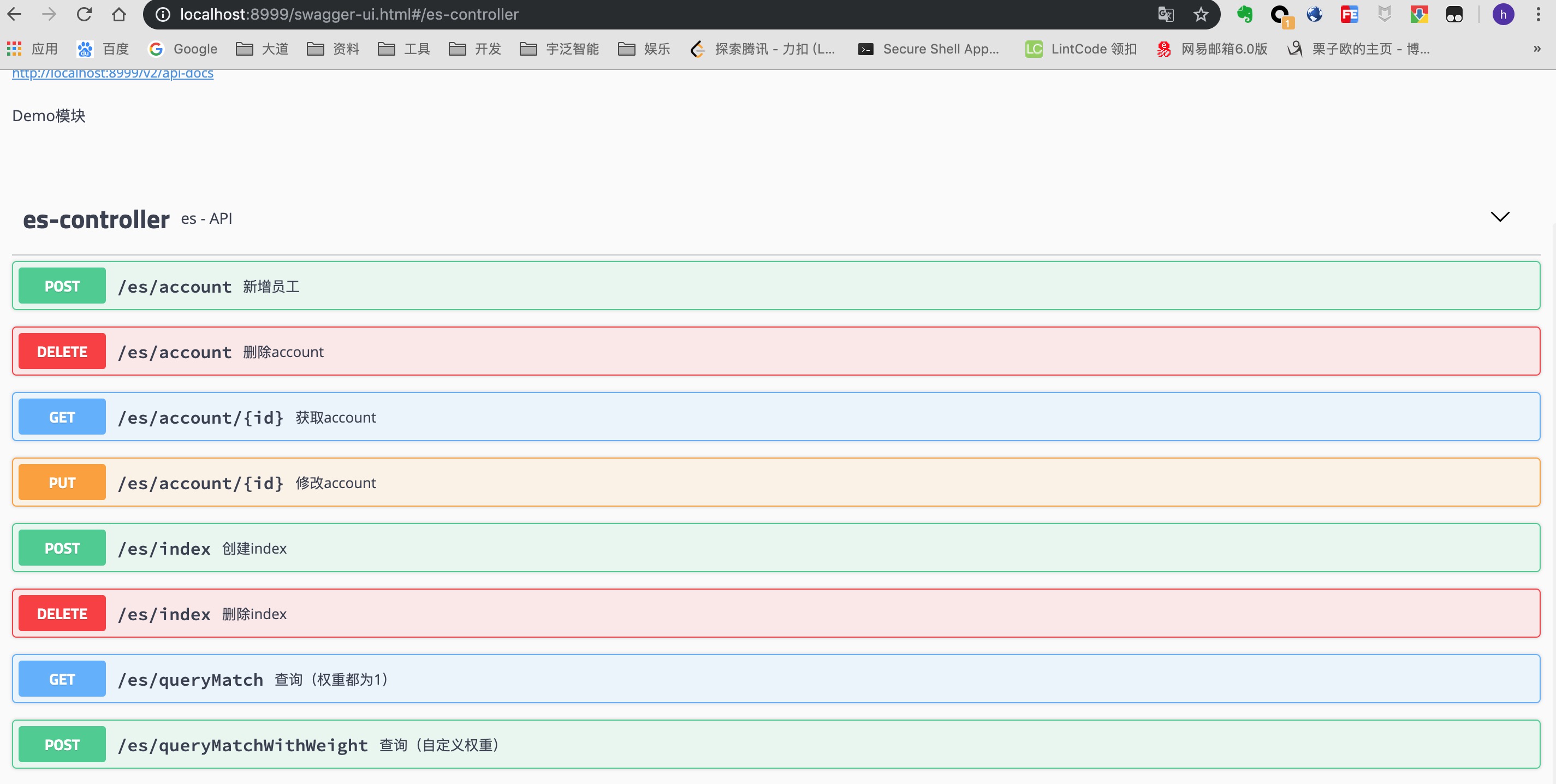
实现了简单的增删该查,中文分词,自定义权重查询等。
4 注意点
4.1
match_phrase 匹配条件:
1).match_phrase先分词后去搜的
2).目标文档需要包含分词后的所有词
3).目标文档还要保持这些词的相对顺序和文档中的一致
term 匹配条件:
1).term不做分词。如果使用term查询,要确保字段是no analyzed的。建索引的时候要注意。
例1:
建索引时使用 ik_max_world 分词。 插入一条数据 name:王富贵
这时会把它分词为 [王,富贵]
使用match_phrase 匹配时 输入 '王富' 则匹配不到。'王富' 分词为[王,富]。 只有 {王 ,富贵,王富贵} 可以匹配到。
同理使用term 匹配时 只有 {王 ,富贵} 可以匹配到。
使用match 匹配时,只要带有 '王','富贵'的任意短语都可以匹配到。 例如{*王*,*富贵*,*王*富贵*.......}
例2:
建索引时不使用中文分词。 插入一条数据 name:王富贵
这时默认分词器会把它分词为 [王,富,贵]
使用match_phrase 匹配时{王,富,贵,王富,富贵,王富贵} 可以匹配到。
同理使用term 匹配时 只有 {王 ,富,贵} 可以匹配到。
使用match 匹配时,只要带有 '王','富','贵'的任意短语都可以匹配到。 例如{*王*,*富*,*贵*.......}
看业务需求选择是否使用中文分词。字段字符数少,且常出现不连贯的中文,例如姓名、行星名等字段不建议使用中文分词。
4.2
logstash 同步mysql数据到es时,并不会同步del操作。也就是mysql中删除后es并不会删除。
方案:
- 1.新增字段status 0:未删除 1:删除。 del走update逻辑。 定期删除mysql和es中status为1的数据。
- 2.手动维护mysql与es关系。手动增删改同步。
logstash 并不会实时同步数据。具体参考配置文件
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
因此对于需要实时查询的业务不建议使用logstash同步数据。需手动同步数据。使es与mysql数据更新处于一个事务下确保一致性。