为什么需要链表?
对于上部分顺序表的学习,我们了解到在构建顺序表时需要预先知道数据大小来申请连续的存储空间,而在进行扩充的时候又需要进行数据的搬迁,所以使用起来并不是很灵活。
那我们就想,能不能存在一种数据结构是的在数据扩充的时候,在原有的数据完全不变化,扩充一个数据就增加一个,我们需要这样的一个数据结构,那么这样的数据结构怎么存储呢?
比如构造了一组数据Li=[200],然后申请了一个存储空间将200存储下来,然后补充了一个数据400,Li=[200,400],这时候又申请了一个空间用来储存400,现在我们要做的是不利用顺序表的方式进行存储,把他们顺序链接在一起,并且也不考虑我们最终扩充多少的数据,即扩充一个数据就申请一个单元来储存它,比如在扩充一个数据600,数据结构Li=[200,400,600],那么就在申请一个空间来储存600。如下表所示,我们怎么吧这种离散的空间关联在一起呢?
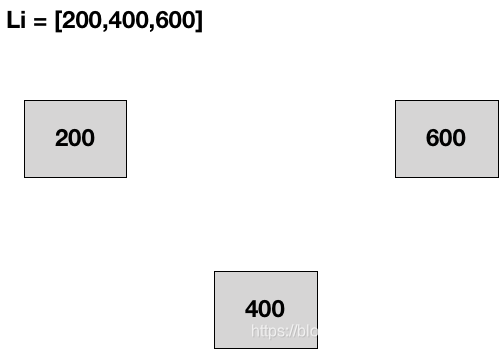
上表的结构已经没有了连续的概念了,但是我们可以通过找一根线将它们串联起来,这个概念已经在顺序表中的元素外置中引入过,具体的做法是:首先申请一个空间存储元素200,在数据扩充个400以后,在申请一个空间用于存储,然后将200与400之间通过一条线进行连接,使之建立一种关系,同样在扩充600的时候,也会申请一个空间用于存储600,然后通过一条线将400与600进行链接,重复这个过程,就可以扩充任意个数据,当然这里暂时先不用明白这条线是怎么具体链接的,后续会详细讲解。如下表所示
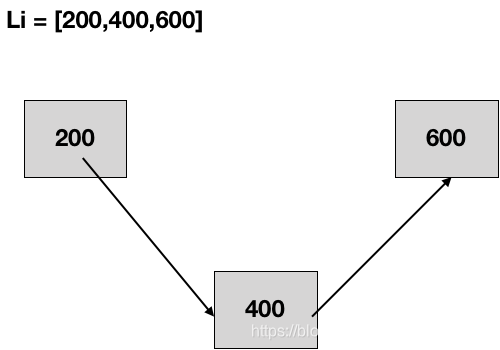
这样链接好了以后,在想获取数据的时候就可以根据200,沿着这条线往下寻找,就能根据这条线将所有元素串联在一起,而且并不需要预估元素的占用空间是多大(整型数据和char)。这种数据结构就叫做链表。
链表的定义
链表(Linked list)是一种常见的基础数据结构。是一种线性表,但是不像顺序表一样连续存储数据,而是在每一个节点(数据存储单元)里存放下一个节点的位置信息(即地址)。

即在申请储存单元的时候,对单个的单元进行拓展,不仅保留该数据,还要保留另外的一部分数据,这两部分称为一个整体,叫做节点。其中第一部分保存数据,第二部分保存地址。而为了链接200和400这两个节点,就将第一个节点的链接区储存为400的地址,后面执行相同的步骤,这样就达到了一种线性关系,通过构建这样的一种数据结构来达到这样的链接关系。
单项链表
单项链表也叫单链表,是链表中最简单的一种形式,他的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。

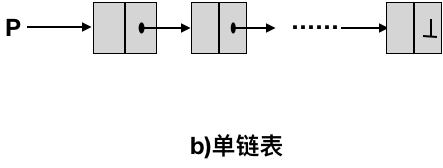
- 表元素elem用来存放具体的数据。
- 链接域next用来存放下一个节点的位置(python中的标识)
- 变量p指向链表的头节点(首节点)的位置,从p出发能找到表中的任意节点。
单链表的操作
下面对该数据结构通过类的方式进行实现,一方面是指数据的保存,一方面是对数据的操作。
具体操作包括:
- is_empty():链表是否为空
- length():链表长度
- travel():遍历链表
- add(item):链表头部添加元素
- append(item):链表尾部添加元素
- insert(pos,item):指定位置添加元素
- remove(item):删除节点
- delete(self, index):指定位置删除元素
- search(self,item):查找指定元素
- find(self,index):根据指定位置查找元素
- change(self,elem,index):根据指定位置替换值
- clear(self):清空链表
- sort(self):排序
- isExist(self,item):是否存在指定的元素
- __init__:初始化节点
单链表实现操作
# 单链表 # 实现功能 # 声明节点类 class Node(object): # 初始化节点 def __init__(self,elem): self.elem=elem self.next=None # 声明链表类 class SingleLinkList(object): # 1、初始化置为空 def __init__(self,node=None): self._head=node # 2、判断是否为空 def is_empty(self): return self._head==None # 3、计算链表长度 def length(self): cur=self._head count=0 while cur != None: count=count+1 cur=cur.next return count # 4、遍历链表 def travel(self): cur=self._head while cur != None: print(cur.elem,end=" ") cur=cur.next # 5、头部添加元素 def add(self,item): node=Node(item) node.next=self._head self._head=node #6、尾部追加元素 def append(self,item): node=Node(item) if self.is_empty(): self._head=node else: cur=self._head while cur.next !=None: cur=cur.next cur.next=node #7、指定位置添加元素 def insert(self,position,item): # 头插法 if position<0: self.add(item) # 尾插法 elif position>(self.length()-1): self.append(item) else: node=Node(item) pre=self._head count=0 while count<(position-1): pre=pre.next count+=1 node.next=pre.next pre.next=node # 8、删除指定元素 def remove(self,item): cur=self._head pre=None while cur!=None: if cur.elem==item: if cur==self._head: self._head=cur.next else: pre.next=cur.next break else: pre=cur cur=cur.next # 9、指定位置删除元素 def delete(self, index): # 判空 lgh=self.length() if self.is_empty(): print('空链表') return if index < 0 or index > lgh: print('索引超过范围') return if index == 0: self._head = self._head.next else: pre = self._head for i in range(lgh): if i == index - 1: pre.next = pre.next.next break pre = pre.next lgh -= 1 return # 10、查找指定的元素 def search(self,item): cur=self._head while cur !=None: if cur.elem==item: return True else: cur=cur.next return False #11、根据指定位置查找元素 def find(self,index): len=self.length() if self.is_empty(): print('空链表') if index <0 or index >=len: print('索引超过范围') return node=self._head for i in range(len): if i == index: return node.elem node = node.next # 12、根据位置替换值 def change(self,elem,index): len=self.length() if self.is_empty(): print('空链表') return if index <0 or index >=len: print('索引超出范围') return node = self._head for i in range(len): if i==index: node.elem=elem return node=node.next # 13、清空链表 def clear(self): self._head=None len=self.length() len=0 # 14、排序 def sort(self): len=self.length() for i in range(0,len-1): current_node=self._head for j in range(0,len-i-1): if current_node.elem>current_node.next.elem: tmp=current_node.elem current_node.elem=current_node.next.elem current_node.next.elem=tmp current_node=current_node.next # 15、是否存在指定的元素 def isExist(self,item): count=0 current_node=self._head for i in range(self.length()): if current_node.elem==item: print("%d在链表中%d处 " % (item, i + 1)) # i+1是在正常人认为的位置处,程序员一般是从0开始算起 count = 1 current_node=current_node.next if count==0: print("%d不在链表中 " % item) # 测试 if __name__ == "__main__": lst = SingleLinkList() print(lst.is_empty()) print(lst.length()) lst.add(1) lst.travel() print() lst.append(10) lst.append(11) lst.append(12) lst.travel() print() lst.insert(2,7) lst.travel() print(lst.find(1)) lst.remove(7) lst.travel() print() print(lst.search(1)) lst.delete(1) lst.travel() print() lst.change(1,2) lst.travel() print() lst.sort() lst.travel() print() lst.isExist(1) lst.clear()
结果
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=65143
import sys; print('Python %s on %s' % (sys.version, sys.platform))
sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects'])
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help.
PyDev console: using IPython 7.12.0
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32
runfile('C:/app/PycharmProjects/DataStructure/LinkedList/single_linked_list.py', wdir='C:/app/PycharmProjects/DataStructure/LinkedList')
True
0
1
1 10 11 12
1 10 7 11 12 10
1 10 11 12
True
1 11 12
1 11 1
1 1 11
1在链表中1处
1在链表中2处
链表和顺序表的对比
链表失去了顺序表随机读取的优点,同时链表由于增加了节点的指针域,空间开销大,但对储存空间的使用要相对灵活。
链表域顺序表的各种操作复杂度如下所示:
| 操作 | 链表 | 顺序表 |
|---|---|---|
| 访问元素 | O(n) | O(1) |
| 在头部插入/删除 | O(1) | O(n) |
| 在尾部插入/删除 | O(n) | O(1) |
| 在中间插入/删除 | O(n) | O(n) |
注意虽然表面上看起来复杂度都是O(n),但是链表和顺序表在插入和删除时进行的是完全不同的操作。链表的主要耗时操作是遍历查找,删除和插入操作本身的复杂度是O(1)。顺序表查找很快,主要耗时的操作是拷贝和覆盖。因为除了目标元素在尾部的特殊情况,顺序表进行插入和删除时需要对操作之间的元素进行前后移位操作,只能通过拷贝和覆盖的方法进行。
- search(item):查找节点是否存在