1、搭建一个 LNMP 架构请写出它的底层原理,当用户访问的是静态资源、和动态资源这两种类型的资源时,其中各个 service 之间做了什么操作。请分别一 一写出
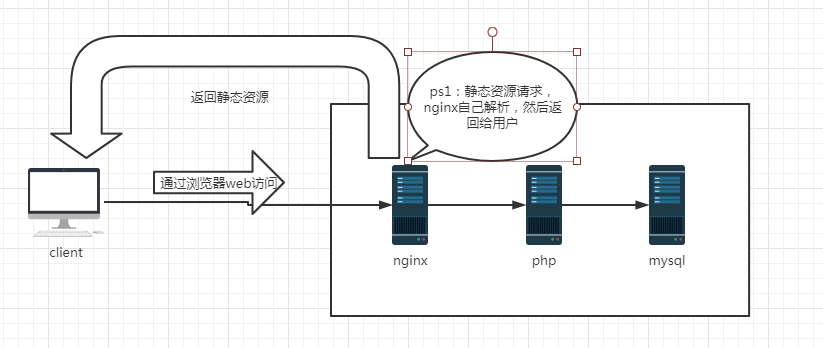
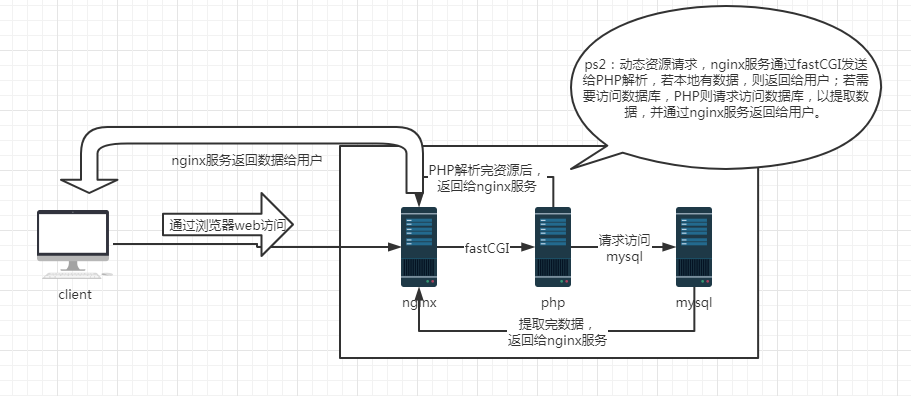
LNMP的工作原理: 当用户通过浏览器输入域名访问nginx web 服务时,如果用户访问的是静态资源,则由nginx解析并返回给用户; 如果用户访问的是动态请求,比如.php等结尾,那么nginx就会通过fastCGI接口发送给PHP解释器(php-fpm),让PHP服务进行解析;如果本机有用户需要访问的资源,则通过nginx服务返回给用户; 如果这个动态请求需要读取数据库,则PHP会请求访问数据库,以获取数据,最后通过nginx服务返回给用户。
2、AOF 和 RDB 的两者之间的区别以及优缺点
RDB模式的优点: RDB模式是快照模式,可以保存某个时间点的数据,可以通过自定义时间点备份,也可以保留多个备份,并且备份文件格式支持很多第三方工具尽心个后续的数据 分析; RDB可以最大化redis的性能,父进程再保存RDB文件时唯一要做的是fork出一个子进程,然后这个子进程处理接下来的所有保存工作,父进程无须执行任何磁盘I/O操作。 RDB恢复大量数据时,恢复速度比AOF快。 RDB模式的缺点: 不能实时保存数据,可能会丢失自上一次执行RDB备份到当前的内存数据。 AOF模式的优点: 数据安全性相对比较高,根据所使用的fsync策略,默认是appendfsync everysec ,每秒执行一次fsync ,即使redis宕机了,最多丢失一秒的数据 由于AOF模式对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek,即使出现宕机现象,也不会破坏日志文件中已存在的内容。 redis可以在AOF文件体积变得过大时,自动在后台对AOF进行重写。 AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。 AOF模式的缺点: 即使有些操作是重复的,AOF也会全部记录,所以导致AOF文件大于RDB 文件 AOF在恢复大数据集时的速度比RDB的恢复速度要慢 根据fsync策略不同,AOF速度可能会慢于RDB BUG出现的可能性更多
3、请问 Redis 持久化如何实现。
根据业务要求,可以实现俩种方案:
1)主要是充当缓存功能,或者可以承受数分钟数据的丢失,这种情况只需要启动RDB即可
vim /apps/redis/erc/redis.conf save 900 1 save 300 10 save 60 10000 dbfilename dump.rdb dir /apps/redis/data/ stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes
2)数据需要持久保存,一点也不能丢失,可以同时开启RDB和AOF
vim /apps/redis/erc/redis.conf save 900 1 save 300 10 save 60 10000 dbfilename dump.rdb dir /apps/redis/data/ stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes appendonly yes appendfilename " appendonly-3769.aof" appendfsync everysec dis /bigdiskpath no-appendfsync-on-rewrite yes auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes
4、通过脚本实现自动化 RDB 备份
修改/apps/redis/etc/redis.conf的配置 save "" dbfilename dump_6379.rdb dir "/apps/redis/data" appendonly no
vim redis_backup.sh
#!/bin/bash redis-cli -h 127.0.0.1 -a 123456 save &> /dev/null DATE =`date +%F_%H_%M_%S` [ -e /backup/redis-rdb/ ] || mkdir -p /backup/redis-rdb/ mv /apps/redis/data/dump_6379.rdb /backup/redis-rdb/dump_6379-${DATE}.rdb