1. 系统监视和进程控制工具—top和free
1) 掌握top命令的功能:top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
2) 了解使用top命令列出系统状态时,系统默认每5秒刷新一下屏幕上的显示结果。
1. 第一行是任务队列信息
|
12:38:33 |
当前时间 |
|
up 50days |
系统运行时间,格式为时:分 |
|
1 user |
当前登录用户数 |
|
load average: 0.06, 0.60, 0.48 |
系统负载。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
2. 第二、三行为进程和CPU的信息
|
Tasks: 29 total |
进程总数 |
|
1 running |
正在运行的进程数 |
|
28 sleeping |
睡眠的进程数 |
|
0 stopped |
停止的进程数 |
|
0 zombie |
僵尸进程数 |
|
Cpu(s): 0.3% us |
用户空间占用CPU百分比 |
|
1.0% sy |
内核空间占用CPU百分比 |
|
0.0% ni |
用户进程空间内改变过优先级的进程占用CPU百分比 |
|
98.7% id |
空闲CPU百分比 |
|
0.0% wa |
等待输入输出的CPU时间百分比 |
|
0.0% hi |
硬件中断占用CPU时间的百分比 |
|
0.0% si |
软件中断占用CPU时间的百分比 |
3. 第四五行为内存信息。

4. 进程信息
|
列名 |
含义 |
|
PID |
进程id |
|
PPID |
父进程id |
|
RUSER |
Real user name |
|
UID |
进程所有者的用户id |
|
USER |
进程所有者的用户名 |
|
GROUP |
进程所有者的组名 |
|
TTY |
启动进程的终端名。不是从终端启动的进程则显示为 ? |
|
PR |
优先级 |
|
NI |
nice值。负值表示高优先级,正值表示低优先级 |
|
P |
最后使用的CPU,仅在多CPU环境下有意义 |
|
%CPU |
上次更新到现在的CPU时间占用百分比 |
|
TIME |
进程使用的CPU时间总计,单位秒 |
|
TIME+ |
进程使用的CPU时间总计,单位1/100秒 |
|
%MEM |
进程使用的物理内存百分比 |
|
VIRT |
进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
|
SWAP |
进程使用的虚拟内存中,被换出的大小,单位kb。 |
|
RES |
进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
|
CODE |
可执行代码占用的物理内存大小,单位kb |
|
DATA |
可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
|
SHR |
共享内存大小,单位kb |
|
nFLT |
页面错误次数 |
|
nDRT |
最后一次写入到现在,被修改过的页面数。 |
|
S |
进程状态。 |
|
COMMAND |
命令名/命令行 |
|
WCHAN |
若该进程在睡眠,则显示睡眠中的系统函数名 |
|
Flags |
任务标志,参考 sched.h |
cpu利用率与load average
cpu是用来干活的,按照这个层面去理解,每个码农都是一个cpu
cpu利用率:上一天班的时间是8个小时,而码农敲代码的时间为2个小时,2/8=0.25 ,25%就是码农在一天的时间内的利用率(正常情况,cpu利用率<70%)
cpu负载:公司在一分钟内为某个码农安排了3个任务,而1分钟内该码农能做6个任务,那么该码农一分钟内的负载为0.5
如果公司在5分钟内为某个码农安排了100个任务,而5分钟内该码农只能做50个任务,那么该码农5分钟内的负载为2.0,即超负荷运转
cpu负载<=1:能正常应付
cpu负载>1:超负荷运转
如果有4核,相当于将100个任务交给4个码农去干,如果每个码农的负载都是100%,那么整体的cpu负载达到4.0则是很正常的现象
多核cpu, load average 应该 <= cpu核数 * 0.7
为何要有1分钟,5分钟,15分钟三种cpu负载?
其实之所以要给出3个值,就是希望我们能结合起来看。或者说希望展示一个动态的图表式的数据,比如最近一分钟显示负载120%。而最近5分钟和15分钟显示负载为50%。可能你不用太过担心。但是如果你发现系统的负载一直维持在120%以上,就必须要提高硬件配置了。
cpu利用率和cpu负载过高,都是不好的现象,但是也有可能出现,低利用率,高负载的情况:
为一个码农分配了100个项目,毫无疑问,该码农的负载是很高的,但是码农在具体去做一个项目时,可能会碰到需要购买机器,或者查询资料等耗费时间的问题,真正动手写代码的时间可能很短,而这段时间才是码农真正为公司干活的时间,如果每个项目都有类似这种问题,那么100个项目加到一起,码农真正工作的时间也不会太多,这就造成了低利用率。
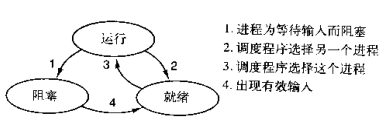
在两种情况下会导致一个进程在逻辑上不能运行,
1. 进程挂起是自身原因,遇到I/O阻塞,便要让出CPU让其他进程去执行,这样保证CPU一直在工作
2. 与进程无关,是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU。
因而一个进程有三种状态
3) 掌握free命令的功能:显示内存的使用状态。(下图centos6中查看效果,用二维数组代表FO即free output)
1 2 3 4 5 6 1 total used free shared buffers cached 2 Mem: 24677460 23276064 1401396 0 870540 12084008 3 -/+ buffers/cache: 10321516 14355944 4 Swap: 25151484 224188 24927296
从操作系统的角度:
物理内存FO[2][1]=24677460KB
物理内存被使用的内存FO[2][2]=23276064KB
可以用内存F[2][3]=1401396KB
等式:FO[2][1] = FO[2][2] + FO[2][3]
共享内存F[2][4]=0,表示几个进程共享的内存(数据共享)
F[2][5]=870540表示已经分配但是还未使用的buffers大小
F[2][6]=12084008表示已经分配但是还未使用的buffers大小
buffer和cache的解释:
- A buffer is something that has yet to be "written" to disk.
- A cache is something that has been "read" from the disk and stored for later use.
也就是说buffer是用于存放要输出到disk(块设备)的数据的,而cache是存放从disk上读出的数据。这二者是为了提高IO性能的,并由OS管理。
Linux和其他成熟的操作系统(例如windows),为了提高IO read的性能,总是要多cache一些数据,这也就是为什么FO[2][6](cached memory)比较大,而FO[2][3]比较小的原因。我们可以做一个简单的测试
- 释放掉被系统cache占用的数据;
echo 3>/proc/sys/vm/drop_caches
- 读一个大文件,并记录时间;
- 关闭该文件;
- 重读这个大文件,并记录时间;
第二次读应该比第一次快很多。
free输出的第二行是从一个应用程序的角度看系统内存的使用情况。
- 对于FO[3][2],即-buffers/cache,表示一个应用程序认为系统被用掉多少内存;
- 对于FO[3][3],即+buffers/cache,表示一个应用程序认为系统还有多少内存;
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多。
这里还用两个等式:
- FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6]
- FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
free命令的所有输出值都是从/proc/meminfo中读出的。
4) 掌握free命令的功能:显示内存的使用状态。(下面均为centos7中查看效果)
http://www.linuxatemyram.com/提到使用free命令查看Linux系统使用内存时,used一项会把当前cache的大小也会加进去,这样会造成free这一栏显示的内存特别少:
$ free -m
total used free shared buff/cache available
Mem: 1504 1491 13 0 855 869
Swap: 2047 6 2041
可是实际上,cache根据应用程序的需要是可以回收利用的,因此free这一栏并不能真实地表现有多少“可以使用”的内存。实际系统可用内存应该以available数据为准。
linuxatemyram所提到的free命令也许是比较老的版本,我尝试了RHEL 7.2,Ubuntu 16.04和Arch Linux这3个Linux发行版,均没有出现used包含cache的情况:
$ free -m
total used free shared buff/cache available
Mem: 64325 47437 3150 1860 13737 14373
另外,从man free命令中也可以得到,目前计算used的值是要减掉free和buff/cache的:
used Used memory (calculated as total – free – buffers – cache)
可以使用-w命令行选项得到buff和cache各自使用的数量:
$ free -wm
total used free shared buffers cache available
Mem: 64325 48287 2476 1859 1430 12131 13524
需要注意的是,free表示的是当前完全没有被程序使用的内存;而cache在有需要时,是可以被释放出来以供其它进程使用的(当然,并不是所有cache都可以释放,比如当前被用作ramfs的内存)。而available才真正表明系统目前可以提供给应用程序使用的内存。/proc/meminfo从3.14内核版本开始提供MemAvailable的值;在2.6.27~3.14版本之间,是free程序自己计算available的值;早于2.6.27版本,available的值则同free一样。
2. 系统中进程的监控—ps(详见linux系统管理P363)
1) 掌握进程的定义:进程是程序的一次动态执行。
2) 掌握守护进程的定义:守护进程是在后台运行并提供系统服务的一些进程。
3) 掌握父进程、子进程的定义:当一个进程创建另一个进程时,第1个进程被称为新进程的父进程,而新进程被称为子进程。
4) 掌握ps命令的功能:用来显示当前进程的状态。
Ps –aux 显示所有的与用户相关的完整信息
系统中进程的监控pstree、kill
centos7默认没有pstree,需要yum -y install psmisc
1) 掌握pstree命令的功能:以树状图显示程序。
2) 掌握pstree命令的用法举例:
例如:列出PID为4729的进程的进程状态树的命令:pstree 4729
3) 掌握kill命令的功能:把一个信号发送给一个或多个进程。默认发送终止信号。
4) 灵活应用kill命令终止进程
例如:终止PID为3852的进程的命令:kill 3852
5) 灵活应用kill -9命令杀死进程
例如:杀死PID为3906的进程的命令:kill -9 3906
3. 掌握pgrep命令的功能:通过名称或其他属性查找进程
例如:查找名为firefox的进程的命令为:pgrep firefox
4. 掌握pkill命令的功能:通过名称或其他属性发信号给进程
例如:杀死名为firefox的进程的命令为:pkill firefox
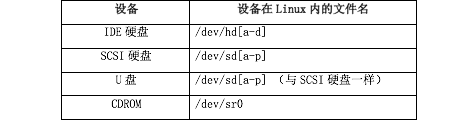
1. 硬件设备与文件名的对应关系(详见linux系统管理P297)
1) 掌握在Linux系统中,每个设备都被当初一个文件来对待。
2) 掌握各种设备在Linux中的文件名
2. 硬盘的结构及硬盘分区(详见linux系统管理P301)
1) 了解为什么要进行硬盘分区:
a) 更容易管理和控制系统,因为相关的文件和目录都放在一个分区中。
b) 系统效率更高。
c) 可以限制用户使用硬盘的份额(磁盘空间的大小)。
d) 更容易备份和恢复。
2) 掌握硬盘的逻辑结构:
一个硬盘逻辑上可以被划分成块、磁道、磁柱和分区。
3) 掌握块的定义:块是盘片上寻址(访问)的最小单位,一个块可以存储一定字节的数据。
4) 掌握磁道的定义:磁道是由一系列头尾相连的块组成的圆圈。
5) 掌握磁柱的定义:磁柱是由一叠磁道,由在相同半径上每个盘面的磁道所组成。
6) 掌握分区的定义:分区是由一组相邻的磁柱所组成。
3. Linux系统中硬盘的分区(详见linux系统管理P303)
1) 掌握硬盘分区的分类:硬盘的分区可以分为主分区、扩展分区和逻辑分区。
2) 掌握主分区的数量:在一个硬盘上最多可以划分出4个主分区。
3) 了解Linux操作系统的内核支持每个硬盘上的分区数量还是有一定限制的,Linux内核在每个硬盘上可以最多支持:
a) 在SCSI硬盘上划分15个分区(Partitions)。
b) 在IDE硬盘上划分63个分区(Partitions)。
4. 使用fdisk和partprobe命令来管理硬盘分区(详见linux系统管理P394)
1) 掌握fdisk命令的功能:创建磁盘分区。
2) 掌握fdisk命令列表中常用的命令:
a) d:删除一个(已经存在的)分区,其中d是delete的第1个字母。
b) l:列出(已经存在的)分区的类型,其中l是list的第1个字母。
c) m:列出fdisk中使用的所有命令,其中m是menu的第1个字母。
d) n:添加一个新的分区,其中n是new的第1个字母。
e) p:列出分区表的内容,其中p是print的第1个字母。
f) q:退出fdisk,但是不存储所做的变化,其中q是quit的第1个字母。
g) t:改变分区系统的id,其中t是title的第1个字母。
h) w:退出fdisk并存储所做的变化,其中w是write的第1个字母。
3) 掌握partprobe命令的功能:重新初始化内存中内核的分区表。
5. 创建文件系统(数据的管理)(详见linux系统管理P399)
1) 掌握格式化的定义:所谓的格式化就是将分区中的硬盘空间划分成大小相等的一些数据块(Blocks),以及设定这个分区中有多少个i节点可以使用等。
2) 掌握文件系统的定义:文件系统是操作系统用于明确磁盘或分区上的文件的方法和数据结构;即在磁盘上组织文件的方法。
3) 了解常用的文件系统类型
ext2:Linux系统中标准的文件系统
ext3:一种日志式文件系统
ext4:一种针对ext3系统的扩展日志式文件系统
lvm:逻辑盘卷管理
iso9660:目前唯一通用的光盘文件系统
4) 掌握mkfs命令的功能:格式化磁盘。
5) 灵活应用常用的格式化命令:
mkfs.文件系统类型
例如,将分区/dev/sdb1格式化为ext4文件系统的命令为:
mkfs.ext4 /dev/sdb1
6. 为一个分区设定label(分区名)(详见linux系统管理P405)
1) 掌握e2label命令的功能:设定或查看一个设备的label名称。
2) 灵活应用e2label命令设定label:
a) 例如:查看/dev/sdb1分区的label的命令为:
e2label /dev/sdb1
b) 例如:将/dev/sdb1分区的label设定为wg的命令:
e2label /dev/sdb1 wg
1. 文件系统的挂载与卸载(详见linux系统管理P406)
1) 掌握挂载的定义:挂载指将一个设备(通常是存储设备)挂接到一个已存在的目录上。
2) 掌握mount命令的功能:实现文件系统的挂载。
3) 灵活应用mount命令实现文件系统的挂载:
例如:将/dev/sdb1分区挂载到/wg目录上的命令:
mount /dev/sdb1 /wg
4) 掌握umount命令的功能:实现文件系统的卸载。
5) 灵活应用umount命令实现文件系统的卸载:
例如:卸载/wg上的文件系统的命令:
umount /wg
2. 虚拟内存的概念以及设置与管理(详见linux系统管理P414)
1) 掌握虚拟内存的定义:所谓虚拟内存就是一块硬盘空间被当做内存使用,也被称为交换分区(swap)。
2) 了解Linux交换分区的类型为:0x82
3) 掌握mkswap命令的功能:设置交换分区。
4) 掌握使用mkswap命令设置交换分区的用法举例:
例如:将分区/dev/sdb2设置为交换分区的命令:mkswap /dev/sdb2
5) 掌握swapon命令的功能:启动交换分区。
6) 掌握swapon –a命令的功能:启动全部的交换分区。
7) 掌握swapon –s命令的功能:列出当前正在使用的所有系统交换分区的状态。
8) 掌握使用swapon命令的用法举例:
例如:启用交换分区/dev/sdb2的命令:swapon /dev/sdb2
3. i节点(详见linux系统管理P170)
1) 掌握i节点的定义:i节点实际上是一个数据结构,它存放了有关一个普通文件、目录或其他文件系统对象的基本信息。
4. 符号(软)链接(详见linux系统管理P174)
1) 掌握符号链接的定义:符号链接是指向另一个文件的一个文件。
2) 掌握ln命令创建软连接的用法举例:
a) 为wolf/dog.wolf.baby文件建立一个dog_ wolf.boy符号链接并放在bodydog目录中的命令:
ln –s wolf/dog.wolf.baby bodydog/dog_ wolf.boy
5. 硬链接(详见linux系统管理P179)
1) 掌握硬链接的定义:一个硬链接(hard link)是一个文件名与一个i节点之间的对应关系,也可以认为一个硬链接是在所对应的文件上添加了一个额外的路径名。
2) 掌握ln命令创建硬连接的用法举例:
a) 为wolf/wolf.dog文件在backup目录中建立一个名为wolf.dog2的硬链接命令:
ln wolf/wolf.dog backup/wolf.dog2
6. Linux系统中的文件类型(详见linux系统管理P183)
1) 掌握Linux系统中常见的文件类型:
-:普通文件(regular file),也有人称为正规文件。
d:目录(directory)。
l:符号(软)链接。
b:块特殊文件(b是block的第1个字符),一般指块设备,如硬盘。
c:字符特殊文件(c是character的第1个字符),一般指字符设备,如键盘。
7. 怎样检查磁盘空间(详见linux系统管理P185)
1) 掌握df命令的功能:显示文件系统中磁盘使用和空闲区的数量。
-a 显示所有磁盘
-h 单位转换
2) 掌握du命令的功能: 显示目录和文件的大小a h同上