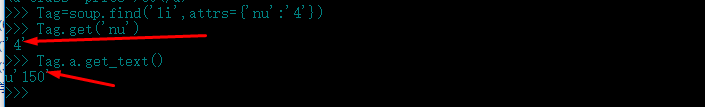1.与Scrapy不同的是Beautiful Soup并不是一个框架,而是一个模块;与Scrapy相比,bs4中间多了一道解析的过程(Scrapy是URL返回什么数据,程序就接受什么数据进行过滤),bs4则在接收数据和进行过滤之间多了一个解析的过程,根据解析器的不同,最终处理的数据也有所不同,加上这一步骤的优点是可以根据输入数据的不同进行针对性的解析;同一选择lxml解析器;
2.安装Beautiful Soup环境:pip install beautifulsoup4

3.Beautiful Soup除了支持python标准库中的HTML解析器外,还支持一些第三方解析器;效率更高
4.安装lxml解析器:pip install lxml

5.Beautiful Soup的查找数据的方法更加灵活方便,不但可以通过标签查找,还可以通过标签属性来查找,而且bs4还可以配合第三方的解析器,可以针对性的对网页进行解析,使得bs4威力更加强大,方便
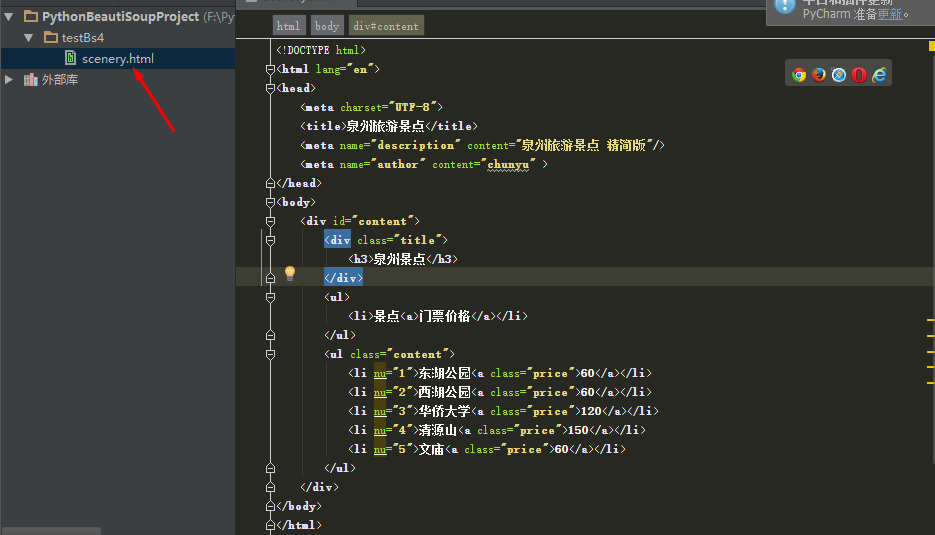
自建一个html的示例文件scenery.html,通过对scenery.html的操作学习bs4模块:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>泉州旅游景点</title>
<meta name="description" content="泉州旅游景点 精简版"/>
<meta name="author" content="chunyu" >
</head>
<body>
<div id="content">
<div class="title">
<h3>泉州景点</h3>
</div>
<ul>
<li>景点<a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">东湖公园<a class="price">60</a></li>
<li nu="2">西湖公园<a class="price">60</a></li>
<li nu="3">华侨大学<a class="price">120</a></li>
<li nu="4">清源山<a class="price">150</a></li>
<li nu="5">文庙<a class="price">60</a></li>
</ul>
</div>
</body>
</html>
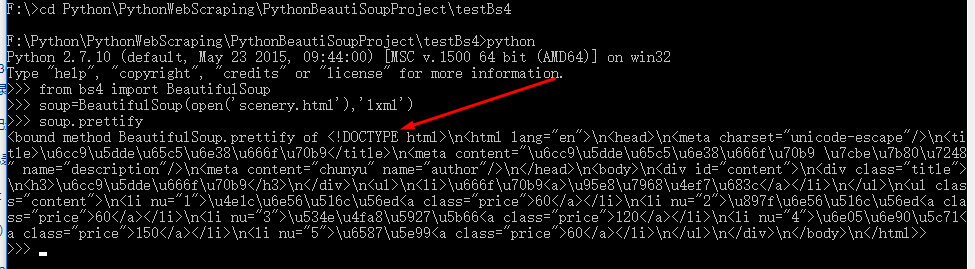
6.进入文件目录执行命令:
F:>cd PythonPythonWebScrapingPythonBeautiSoupProject estBs4
F:PythonPythonWebScrapingPythonBeautiSoupProject estBs4>python
>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(open('scenery.html'),'lxml')
>>> soup.prettify
执行结果:
7.一个文件或者一个网页,在导入BeautifulSoup处理之前,bs4并不知道它的字符编码是什么,在导入BeautifulSoup过程中,它会自动猜测这个文件或者网页的字符编码,常用的字符编码当然很快就会猜出来,但是不常用的编码就需要BeautifulSoup提供的两个参数解决:exclude_encoding和from_encoding
(1)参数exclude_encoding的作用是排除不正确的字符编码,例如已经确定非常网页不是iso-8859-7也不是gb2312编码,就可以使用命令:
soup=BeautifulSoup(response.read(),exclude_encoding=['iso-8859-7','gb2312'])
(2)如果已经知道网页的编码是big5,也可以直接使用from_encoding参数直接确定编码:
soup=BeautifulSoup(response.read(),from_encoding=['big5'])
(3)如果不知道文件的字符编码,而bs4又解析错误时,那就只有安装chardet或者cchardet模块,然后使用UnicodeDammit自动检测了
8.解决字符编码这个问题后,已经得到了soup这个bs4的类。在soup中,bs4将网页节点解析成一个个Tag;
执行命令:Tag1=soup.ul

9.使用命令soup.find_all(Tag,[attrs])可以获取所有符合条件的标签列表,然后直接从列表中读取就可以了:
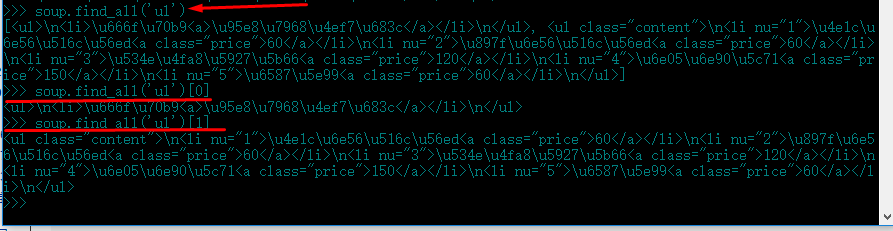
10.从顺序上区别同名标签,这样出现再多的同名标签也可以很从容的定位了。在html中,同名标签比较少,可以用soup.find_all
来获取标签位置列表,再一个一个数的方法确定标签位置,但是如果这个列表太长,就没法接受了;
所以,需要使用soup.find和soup.find_all都支持的名字+属性值定位:

11.如果标签名相同,属性相同,连属性值都相同的标签,那就用soup.find_all(tagName,attrs={'attName':'attValue'})将所有符合条件的标签装入列表,然后一个一个的慢慢数吧,本实例中符合此条件的也就是<a>标签了:
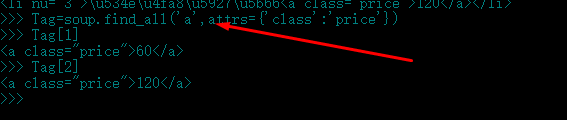
所有<a>标签的标签名,属性和属性值虽然相同,但是他们的上级标签(父标签)标签名,属性和属性值总不可能都相同:

这种不直接定位目标标签,而是先间接定位目标的上级标签,再间接定位目标标签的方法,有点类似于Scrapy中的XPath的嵌套过滤了
12.一般来说,最终获取保存的不会是标签,而是标签里的数据,这个数据可能是标签所包含的字符串,也可能是标签的属性值
Tag=soup.find('li',attrs={'nu':'4'})
Tag.get('nu')
Tag.a.get_text()