1.目标分析:
2.创建编辑Scrapy爬虫:
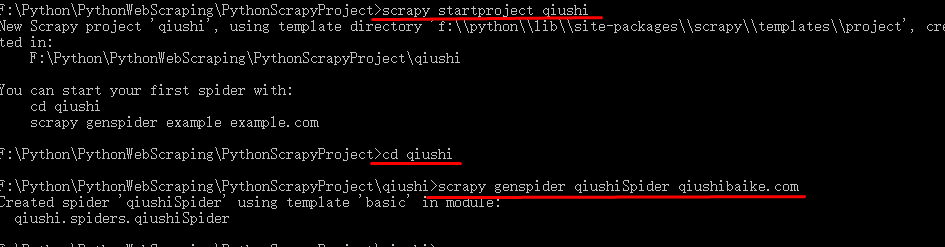
(1)执行命令:
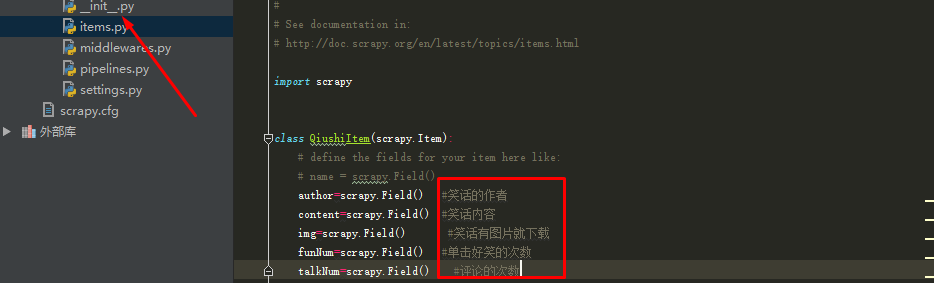
(2)编辑items.py文件:
(3)Scrapy项目中间件----添加Headers:
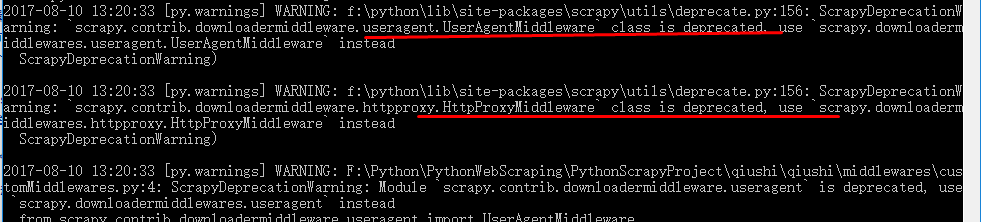
在Scrapy项目中,掌管proxy的中间件是scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware,直接修改这个文件不是不可以,不过为了一个项目就去修改整个环境变量,不值得;
所以,我们自己写一个中间件,让它运行,然后将Scrapy默认的中间件关闭掉就可以了;
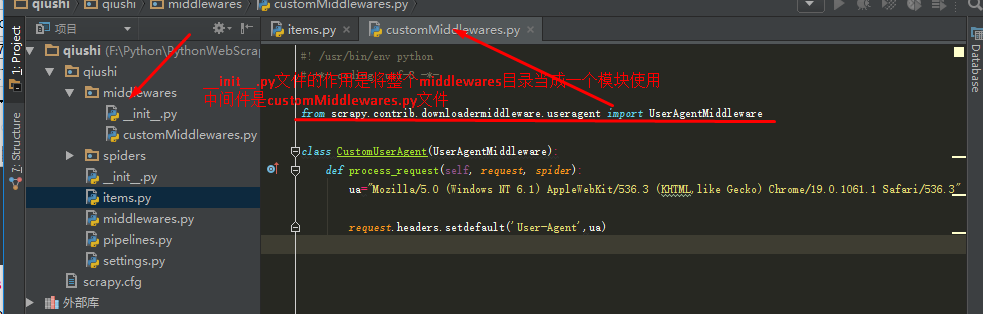
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class CustomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML,like Gecko) Chrome/19.0.1061.1 Safari/536.3"
request.headers.setdefault('User-Agent',ua)
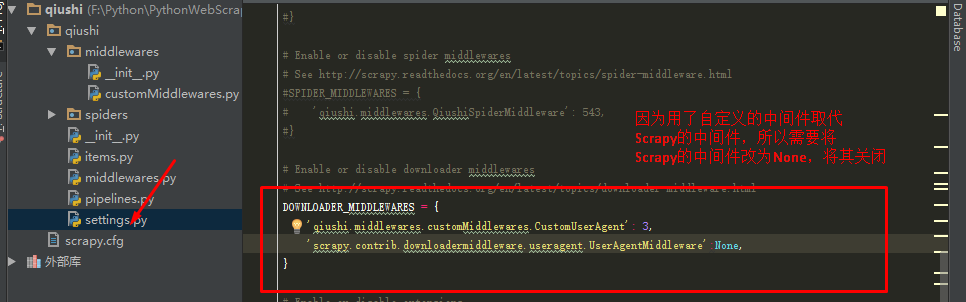
(4)修改settings.py文件,将系统默认的中间件scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware关闭,用自己创建的中间件qiushi.middlewares.customMiddlewares.CustomUserAgent代替:
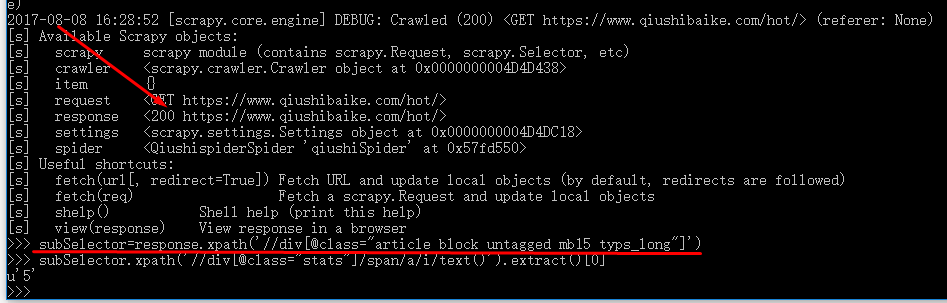
(5)编辑糗事Spider.py文件,获取所需数据:
subSelector=response.xpath('//div[@class="article block untagged mb15 typs_long"]')
subSelector.xpath('.//div[@class="content"]/span/text()').extract()[0] 笑话内容
subSelector.xpath('./div[@class="stats"]/span/i/text()').extract()[0] 好笑次数
subSelector.xpath('.//h2/text()').extract()[0] 发布者名字
subSelector.xpath('//div[@class="thumb"]/a/img/@src').extract()[0] 笑话图片
subSelector.xpath('//div[@class="stats"]/span/a/i/text()').extract()[0] 评论次数
(6)编辑qiushiSpider.py文件:
# -*- coding: utf-8 -*-
import scrapy
from qiushi.items import QiushiItem
class QiushispiderSpider(scrapy.Spider):
name = 'qiushiSpider'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/hot']
def parse(self, response):
subSelector=response.xpath('.//div[@class="article block untagged mb15 typs_hot" or @class="article block untagged mb15 typs_old" ]')
items=[ ]
for sub in subSelector:
item=QiushiItem()
item['author']=sub.xpath('.//h2/text()').extract()[0]
item['content']=sub.xpath('.//div[@class="content"]/span/text()').extract()[0]
item['img']=sub.xpath('//div[@class="thumb"]/a/img/@src').extract()
item['funNum']=sub.xpath('./div[@class="stats"]/span/i/text()').extract()[0]
item['talkNum']=sub.xpath('//div[@class="stats"]/span/a/i/text()').extract()[0]
items.append(item)
return items
注意这个图片的路径:是//div[@class="thumb"]/a/img/@src,不是.//div[@class="thumb"]/a/img/@src
而且是extract(),不是extract()[0],加上[0]意味着只有第一张图片的URL被爬取下来
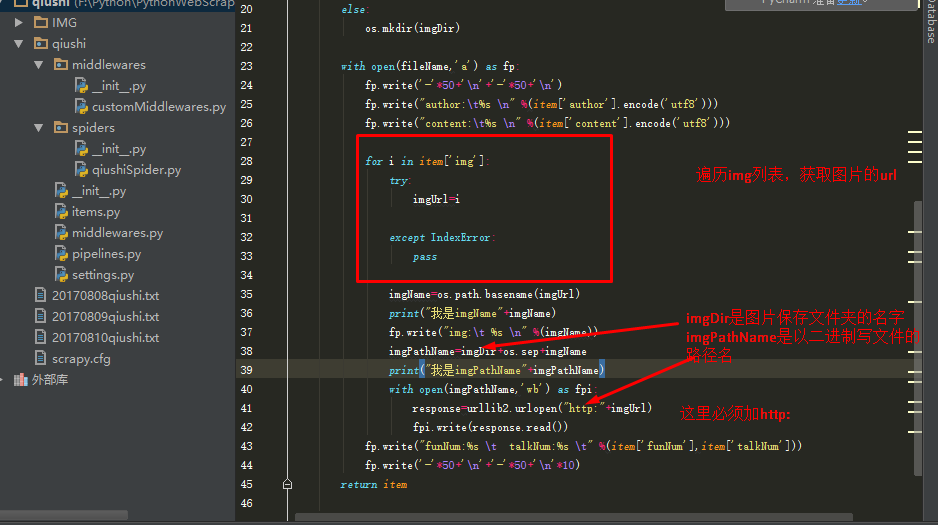
(7)编辑pipelines.py文件,保存图片和数据:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import urllib2
import os
class QiushiPipeline(object):
def process_item(self, item, spider):
today=time.strftime('%Y%m%d',time.localtime())
fileName=today+'qiushi.txt'
imgDir='IMG'
if os.path.isdir(imgDir):
pass
else:
os.mkdir(imgDir)
with open(fileName,'a') as fp:
fp.write('-'*50+' '+'-'*50+' ')
fp.write("author: %s " %(item['author'].encode('utf8')))
fp.write("content: %s " %(item['content'].encode('utf8')))
for i in item['img']:
try:
imgUrl=i
except IndexError:
pass
imgName=os.path.basename(imgUrl)
print("我是imgName"+imgName)
fp.write("img: %s " %(imgName))
imgPathName=imgDir+os.sep+imgName
print("我是imgPathName"+imgPathName)
with open(imgPathName,'wb') as fpi:
response=urllib2.urlopen("http:"+imgUrl)
fpi.write(response.read())
fp.write("funNum:%s talkNum:%s " %(item['funNum'],item['talkNum']))
fp.write('-'*50+' '+'-'*50+' '*10)
return item
3.在qiushi项目的任意目录下,运行命令:scrapy crawl qiushiSpider
爬取结果:
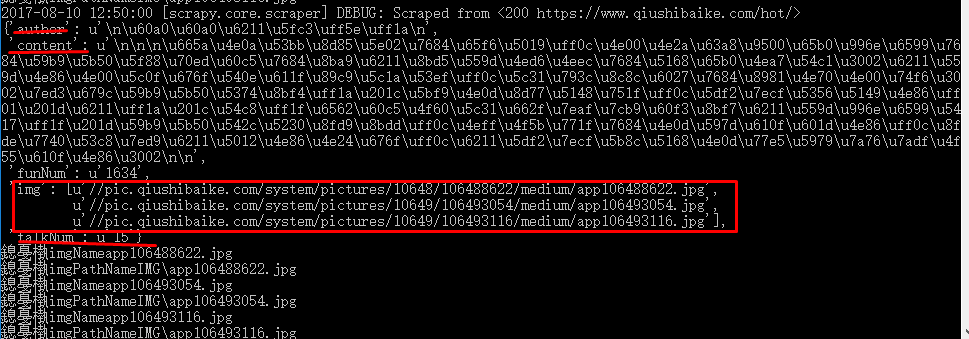
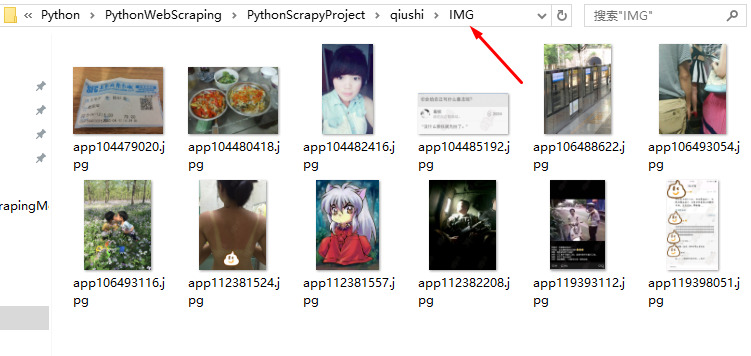

4.Scrapy项目中间件----------添加Proxy
Scrapy默认环境下,proxy的设置是由中间件scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware控制的
我们这里还是自己定义一个中间件取代这个环境变量就好。直接在middleware.customMiddlewares(自己建的模块和文件)中添加一个类就好。
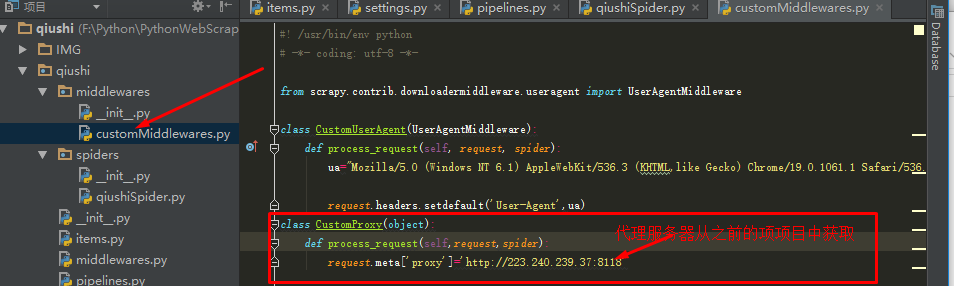
接下来在修改Settings.py文件就好,将新添加的中间件CustomProxy添加到DOWNLOADER_MIDDLEWARES中去,这里与之前的CustomUserAgent不同的是:
CustomUserAgent需要禁止系统的UserAgentMiddleware,而CustomProxy则需要在系统的HttpProxyMiddle之前执行:
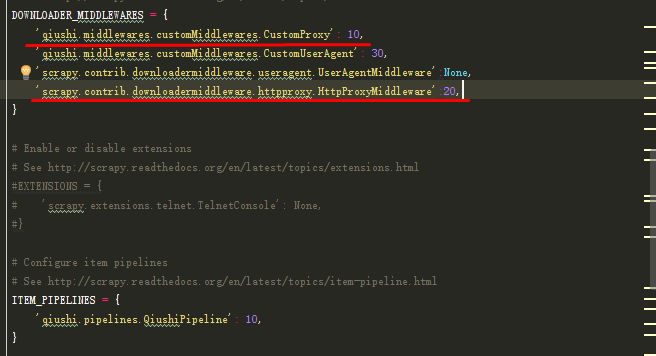
再次执行命令:scrapy crawl qiushiSpider
可以看到两个中间件都启动运行了,如果proxy不行,多试几个代理服务器看看就好