前言:最近博主买了台Kindle,感觉亚马逊上的图书资源质量挺好,还时不时地会有价格低但质量高的书出售,但限于亚马逊并没有很好的优惠提醒功能,自己天天盯着又很累。于是,我自己写了一个基于Java的亚马逊图书监控的简单爬虫,只要出现特别优惠的书便会自动给指定的邮箱发邮件。
实现思路
简单地说一下实现的思路,本文只说明思路,需要完整项目的童鞋请移步文末
- 简单封装JavaMail,使发送邮件更加方便
- 读取配置文件,用于配置邮件发送及监控设置
- 利用
URL类返回的URLConnection对象对网站进行访问,抓取数据。(这里有个小技巧,在访问亚马逊的时候如果没有在请求头上加入Accept-Encoding:gzip, deflate, br这个参数,则不出几次便会被拒绝访问(返回503),加上之后返回的数据是经GZIP压缩过的,此时需要用GZIPInputStream这个流去读取,否则读到的是乱码) - 利用正则表达式分析获取到的数据,提取有用信息。
- 发送通知邮件。
基本功能
- 监控销量排行榜前50名的图书价格,若出现价格低于设定值的图书,则发送邮件通知。
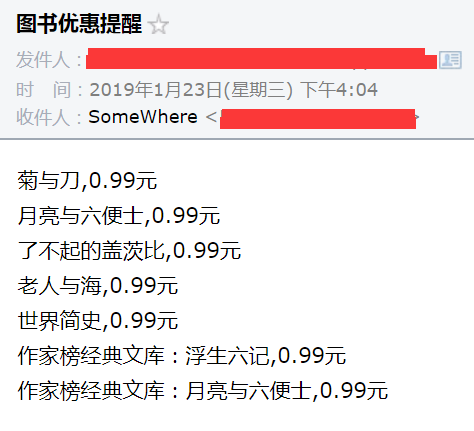
- 带有数据缓存功能,比如持续几天的优惠只会在一开始时通知一次,并不会在每次抓取时都通知。
- 可以通过配置文件(setting.conf)动态更改邮件和监控的设置。
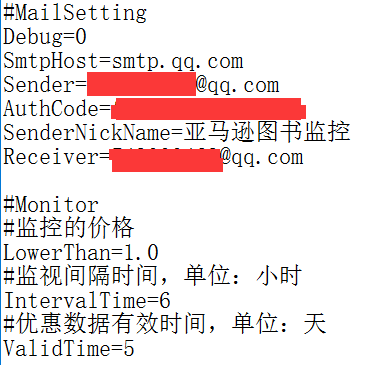
- 报错信息会保存在ErrLog.txt中,一般的日志会保存在Log.txt中。
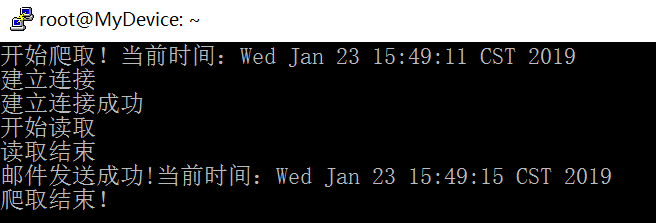
核心代码
因为只截取了部分代码,内容有所缺失,思路能看明白即可
抓取亚马逊信息
this.url = new URL("https://www.amazon.cn/gp/bestsellers/digital-text");
//打开一个连接
URLConnection connection = this.url.openConnection();
//设置请求头,防止被503
connection.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8");
connection.setRequestProperty("Accept-Encoding", "gzip, deflate, br");
connection.setRequestProperty("Accept-Language", "zh-CN,zh;q=0.9");
connection.setRequestProperty("Host", "www.amazon.cn");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36");
//发起连接
connection.connect();
//获取数据,因为服务器发过来的数据经过GZIP压缩,要用对应的流进行读取
BufferedInputStream bis = new BufferedInputStream(new GZIPInputStream(connection.getInputStream()));
ByteArrayOutputStream baos = new ByteArrayOutputStream();
//读数据
while ((len = bis.read(tmp)) != -1) {
baos.write(tmp, 0, len);
}
this.rawData = new String(baos.toByteArray(), "utf8");
bis.close();
用正则分析数据
//先用正则表达式去取单个li标签
Pattern p1 = Pattern.compile("<li class="zg-item-immersion"[\s\S]+?</li>");
Matcher m1 = p1.matcher(this.rawData == null ? "" : this.rawData);
while (m1.find()) {
//取出单个li标签的名字和价格
Pattern p2 = Pattern.compile("alt="([\u4E00-\u9FA5:—,0-9a-zA-Z]+)[\s\S]+?¥(\d{1,2}\.\d{2})");
Matcher m2 = p2.matcher(m1.group());
while (m2.find()) {
//先取出名字
String name = m2.group(1);
//再取出价格
double price = Double.parseDouble(m2.group(2));
//若有相同名字的书籍只记录价格低的
if (this.destData.containsKey(name)) {
double oldPrice = this.destData.get(name).getPrice();
price = oldPrice > price ? price : oldPrice;
}
//将数据放入Map中
this.destData.put(name, new Price(price, new Date()));
}
}
完整项目
我把完整的项目放在了我的Github上,更多详细情况(怎么配置、怎么用),有兴趣的童鞋可以去捧个场!
仓库地址:https://github.com/horvey/Amazon-BookMonitor