新手需掌握技能点
1.谈谈装饰器,迭代器,yield,内存管理等
装饰器可以拓展原来已经存在的一个函数或者类,而不用在函数里面或者在类里面修改,装饰器的本质也是一个函数,但是用到了闭包了这个机制
而闭包就是在外层函数里定义了一个内层函数,外层函数返回内层函数的引用,内层函数里面使用到了外层函数的临时变量
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
迭代器是一种带状态的对象,它会记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素,可迭代对象可以执行__iter__()变成迭代器(Iterator),然后可以使用__next__()从迭代器里取值
含有yield关键字叫做生成器,生成器是一种特殊的迭代器,不过它不需要可迭代对象执行__iter__()这种魔术方法了,只需要一个yield关键字就可以产生一个生成器
python采用"引用计数"和"垃圾回收"两种机制来管理内存。
引用计数通过记录对象被引用的次数来管理对象。
对对象的引用都会使得引用计数加1,移除对对象的引用,引用计数则会减1,
当对象不再需要时,也就是引用计数减为0时,对象所占的内存就会被释放掉。
引用计数可以高效的管理对象的分配和释放,但是有一个缺点,就是无法释放引用循环的对象
这个时候就需要垃圾回收机制(garbage collection),来回收循环应用的对象,
分代回收策略着重于提升垃圾回收的效率。
当对象很多时,垃圾检测将耗费大量的时间而真的垃圾回收花不了多久。
对于这种多对象程序,我们可以把一些进行垃圾回收频率相近的对象称为“同一代”的对象。
垃圾检测的时候可以对频率较高的“代”多检测几次,反之,进行垃圾回收频率较低的“代”
可以少检测几次。这样就可以提高垃圾回收的效率了。至于如何判断一个对象属于什么代,
python中采取的方法是通过其生存时间来判断。如果在好几次垃圾检测中,该变量都是
reachable的话,那就说明这个变量越不是垃圾,就要把这个变量往高的代移动,要减少
对其进行垃圾检测的频率。
垃圾回收机制会根据内存的分配和释放情况的而被调用
2.计算密集型,IO密集型任务怎么办
15.python高并发解决方案?
高并发有两种任务场景:
15.1. IO密集型任务
这种任务场景直接使用多线程库threading即可解决。
更高效:线程有上下文切换开销,使用协程更好,如asyncio、gevent库
15.2. 计算密集型任务
提高这种任务的执行效率只能使用并行,而并行只能通多进程(multiprocessing)来实现。
14. python适合的场景有哪些?当遇到计算密集型任务怎么办?
适合场景:
14.1. web开发,有非常优秀的web开发框架,如django,flask,aiohttp,且文档完善。
14.2. linux运维。有完善的执行shell脚本的库。
14.3. 网络爬虫。是最适合写爬虫的语言,没有之一;有丰富的访问网页和提取HTML文档数据的库。
14.4. 对并发要求不高的场景。GIL使得python只适合应用于对IO密集型任务的并发处理,对计算密集型任务的并发无能为力。
处理计算密集型任务:
使用多进程来执行,进程之间相互独立,各自拥有系统分配的CPU资源和独立内存空间,实现并行
(但CPU必须是多核或多颗CPU,现代计算机均符合此条件)。
3.tcp/udp的区别?tcp粘包有了解吗?


TCP三次握手:
1. client发送SYN(seq=x)报文 => server(client状态变为SYN_SENT)
2. server发送ACK(seq=x+1)以及SYN(seq=y)报文 =>client (server状态变为SYN_RECV)
3. client发送ACK(seq=y+1) => server (client变为ESTABLISHED,服务器收到后也变为ESTABLISHED)
四次挥手:
这和三次握手不一样,三次握手是客户端发起的SYN请求,在四次挥手中客户端和服务端都能发起断开连接请求。一般来说是客户端主动发起断开的请求。
1. client发送FIN(seq=x) =>server (client变为FIN_WAIT_1)
2. server先回复ACK(seq=x+1) => client (server只要收到FIN报文就会变为CLOSE_WAIT, client变为FIN_WAIT_2)
3. server发送完剩余的数据报文后,再发送FIN(seq=y) =>client (server变为LAST_CHECK)
4. client发送ACK(seq=y+1) => server (client变为TIME_WAIT)
server收到ACK后直接就关闭closed状态,但client要等2MSL(最大报文生存时间)才会变为closed。
client的状态转变顺序:established-->fin_wait_1->fin_wait_2->time_wait->closed
server的状态转变顺序: established-->close_wait->last_ack->closed
特殊状态
在三次回收四次握手中有两个特殊的状态,一个是ESTABLISHED和TIME_WAIT状态,并且是必不可少的。
ESTABLISHED:是建立三次握手之后的客户端和服务端的状态,只有两边同时处于ESTABLISHED状态才能进行数据通信
TIME_WAIT(主动关闭方才有)
(1)如果没有TIME_WAIT状态的话在四次挥手中加入客户端发送的ACK丢失的话服务端不能关闭,但是客户端已经关闭了,当收不到ACK的时候服务端会重新发送一个FIN包请求,这时候客户端已经关闭,假如一个新的客户端建立之后使用先前的端口信息,会直接将FIN包发送给新的客户端,这回对新的连接造成影响
(2)若新客户端使用相同端口信息,向服务端发送FIN请求,但是服务端因为没有收到最后一个ACK请求处于LAST_ACK状态,在收到SYN后判定状态错误,回复RST报文重置连接,也对新的连接造成影响。
(3)TIME_WAIT一般持续时间是2MSL(报文最长生命周期)因为在ACK丢失的时候,导致对方重传的时候需要2*MSK,也是等待网络中所有双方延迟的报文消失在网络中,不会对后序的操作造成影响。
4.TIME_WAIT,CLOSE_WAIT,ESTABLISHED是什么?出现过多的CLOSE_WAIT可能是什么原因?
关于time_wait和close_wait是什么见下图
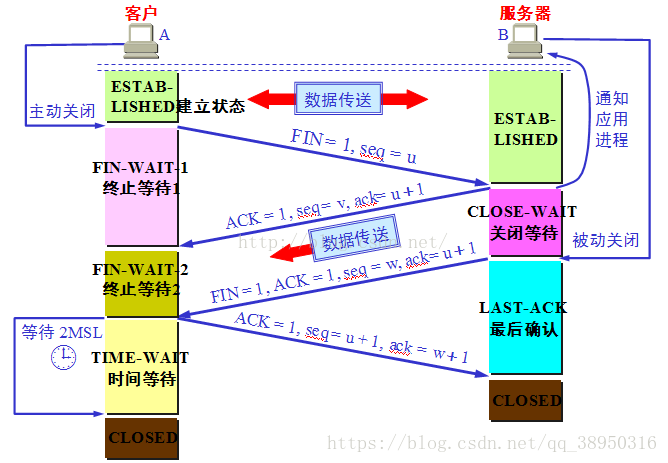
过多的CLOSE_WAIT可能是什么原因:服务器端的代码,没有写 close 函数关闭 socket 连接,也就不会发出 FIN 报文段;或者出现死循环,服务器端的代码永远执行不到 close。
5.epoll,select的区别?边缘触发,水平触发区别?
select和epoll这两个机制都IO多路复用的解决方案
IO多路复用定义:同时监控多个IO事件,当哪个IO事件准备就绪就执行哪个IO事件,形成并发的效果
以此形成可以同时操作多个IO的行为,避免一个IO阻塞造成其他的都无法运行,提高了执行效率
epoll
* 效率上比poll和select稍微高
* 只能用于linux unix,select还可用于Windows
* 支持边缘触发,select poll只支持水平触发
水平触发:如果文件描述符已经就绪可以非阻塞的执行IO操作了,此时会直接触发通知。select,poll就属于水平触发。
边缘触发:如果文件描述符自上次状态改变后有新的IO活动到来,此时会触发通知,在收到一个IO事件通知后要尽可能多的执行IO操作。如果在一次通知中没有执行完IO那么就需要等到下一次新的IO活动到来才能获取到就绪的描述符,epoll既可以采用水平触发,也可以采用边缘触发。
举例说明:一个管道收到了1kb的数据,此时读了512字节数据,然后再次调用epoll。这时如果是水平触发的,epoll会立即返回,因为有数据准备好了。如果是边缘触发的,不会立即返回。因为此时虽然有数据可读但是已经触发了一次通知。在这次通知后,直到有新的数据到来epoll才会返回,此时老的数据和新的数据都可以读取到(当然是需要这次你尽可能的多读取)。
python基础:
1. 可变与不可变类型
不可变类型:变量对应的值中的数据是不能被修改,如果修改就会生成一个新的值从而分配新的内存空间。
不可变类型:
数字(int,long,float)
布尔(bool)
字符串(string)
元组(tuple)
可变类型:变量对应的值中的数据可以被修改,但内存地址保持不变。
可变类型:
列表(list)
字典(dict)
2. 谈谈浅拷贝与深拷贝
https://www.cnblogs.com/hooo-1102/p/12108164.html
3. __new__和__init__的区别
1 new在init之前执行,前者可决定是否调用后者
2 在OOP中,实例化遵循 创建x,初始化x,返回x (x=实例对象)这么个顺序,new是创建,init是初始化
https://www.cnblogs.com/hooo-1102/p/12131870.html
4. 谈谈设计模式
解释一下什么是设计模式
简述:是经过总结、优化后的可重用解决方案。它是一种代码设计思想,不同的模式解决不同的问题,跟编程语言不相关。
你知道哪些设计模式,代码如何实现
b. 单例模式:
意图:保证程序运行时全局环境中只有一个该类的实例
适用性:无论何时何处调用该类,都能使用同一个该类的实例对象的时候。
代码实现:https://www.cnblogs.com/hooo-1102/p/12131870.html
5. 列表推导式和生成器的优劣
推导式:它将所有元素一次性加载到内存中,适合数量小的元素集合表示
生成器:只能遍历使用,每次返回一个元素,没有下一个元素时抛出异常。适合大数据量的处理。

7. 使用装饰器的单例模式和其他方法(如new方法,或者单文件实现的单例)相比,有何区别?
使用装饰器实现不会重新初始化对象,它是直接返回之前的对象;
而其他方法均会再执行一次init方法,这也是装饰器实现单例的好处。
#使用__new__方法在创造实例时进行干预,达到实现单例模式的目的 #这里使用了_instance属性来存放实例 class Singleton: #一个通用的单例超类,其他类继承即可(也可通过装饰器实现) def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): cls._instance = object.__new__(cls) return cls._instance def Singleton(cls): d = {} def _Singleton(*args, **kwargs): if cls not in d: d[cls] = cls(*args,*kwargs) return d[cls] return _Singleton @Singleton class SingleSpam(): def __init__(self, s): self.s = s def __str__(self): return self.s s1 = SingleSpam('spam') print(id(s1), s1) s2 = SingleSpam('spa') print(id(s2), s2)
使用装饰器:(第二次实例化直接返回第一个,所以连实例化时传的参数都没有应用,返回跟第一个一模一样的实例)
32307128 spam
32307128 spam
使用__new__:(第二次实例化也执行了子类的__init__方法)
32176000 spam
32176000 spa
8. 谈谈线程与进程的区别
调度方不同:进程是操作系统调度的基本单位,而线程是cpu调度的基本单位。
开销不同:创建一个进程需要系统单独分配新的地址空间,代价昂贵;而创建新的线程可以直接使用进程的内存空间,所以进程开销大于线程。
通信方式不同:进程间通信一般通过HTTP或RPC方式;而同一进程下的不同线程间是共享全局变量的,通信更简便。
健壮性不同:单个进程死掉不会影响其他进程,而单个线程死掉会导致整个进程死掉。
python里多线程也是并发执行的,即同一时刻,Python 主程序只允许有一个线程执行,这和全局解释器锁有关系
11. *args and **kwargs如何使用?
*args代表位置参数,它会接收任意多个参数并把这些参数作为元组传递给函数。
**kwargs代表的关键字参数,允许你使用没有事先定义的参数名,kwargs是一个dict;
另外,位置参数一定要放在关键字参数的前面。
12. with语句应用场景是?有什么好处?能否简述实现原理
场景:with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
好处:不需要人为释放资源。
原理:with 主要用到一个概念:上下文管理器。吧啦吧啦__exit__()
13. 标准库线程安全的队列是哪一个?不安全的是哪一个?logging是线程安全的吗?

14.gevent
总结:gevent是基于协程的网络库,通过事件循环机制来实现并发编程(区别于并行)。
当某个协程遇到IO事件时,会将控制权转让给主线程,主线程再将控制权
交给IO事件已经完成的协程,若都没完成,主线程将一直持有控制权。
需注意:不管是threading还是gevent都不能利用多核优势,都只适合处理IO密集型的任务。
MYSQL:
1.了解mysql字符集和排序规则吗?

2. varchar与char的区别是什么?大小限制?utf8字符集下varchar最多能存多少个字符?
char定义的是固定长度,长度最大255字符,存储时,如果字符数没有达到定义的位数,会在后面用空格补全存入数据库中
varchar定义的是变长长度,长度最大为65535字节,存储时,如果字符没有达到定义的位数,也不会在后面补空格,当然还有一或两个字节来描述该字节长度
取数据时的区别
数据库取char的数据时,会把后面的空格全部丢弃掉,也就是说,在char中的尾部存入空格时,最后取出来都会被丢弃.而数据库在取varchar数据时,尾部空格会保留.
3. primary key 和 unique 区别?

4.外键有什么用,是否该用外键?外键一定需要索引吗?
外键的作用:让当前表字段的值在另一个表的范围内选择

5.myisam与innodb的区别与选择?

总结
读操作多用MyISAM
写操作多用InnoDB
6.索引有什么用,大致原理是什么?设计索引有什么注意点?

redis:
1.什么场景用redis,为什么mysql不适合?


2.谈谈redis的事务?可以处理分布式事务吗?怎么解决?
1. 单独的隔离操作:事务中的所有命令会被序列化、按顺序执行,在执行的过程中不会被其他客户端发送来的命令打断
2. 不保证原子性:redis中的一个事务中如果存在命令执行失败,那么其他命令依然会被执行,没有回滚机制
redis本身不处理分布式事务或者说它的事务非常弱,因为redis本身是单线程的.


3.redis为什么这么快

4.redis持久化
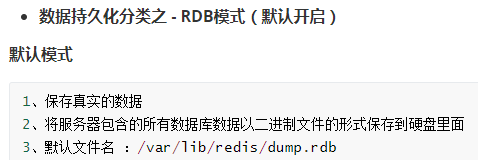

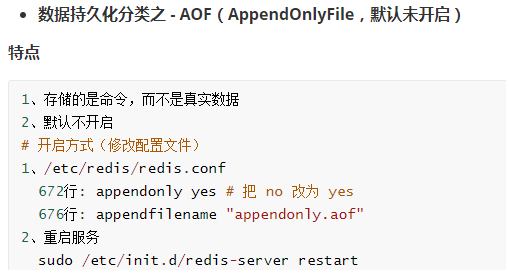

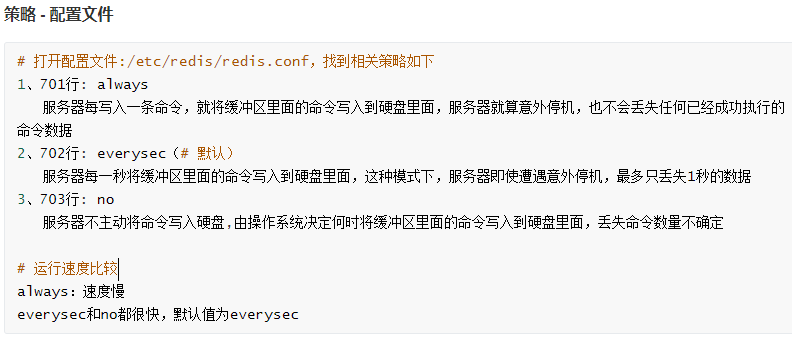

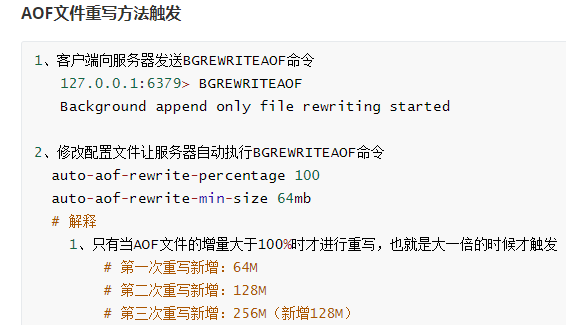
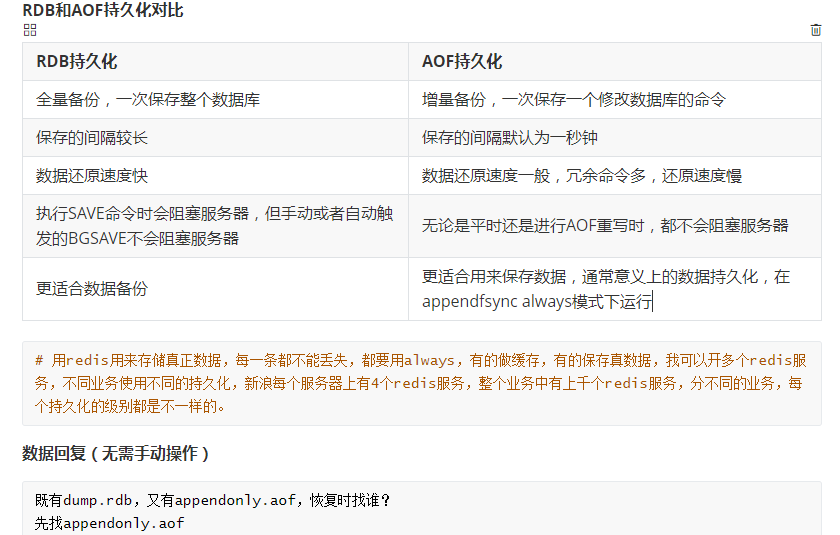
5.redis主从复制以及哨兵
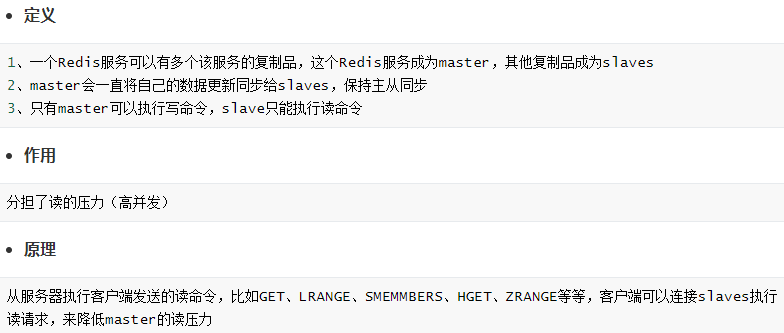
万一mster挂了,再来手动设置master效率低而且浪费时间,这就需要sentinel哨兵,实现故障转移Failover操作

安全:
1.csrf,xss,SQL注入:
https://www.cnblogs.com/hooo-1102/p/12074462.html
2.简单说说https的工作原理与http的区别?

3.说说https有什么缺点?

4.对称加密与非对称加密区别?
