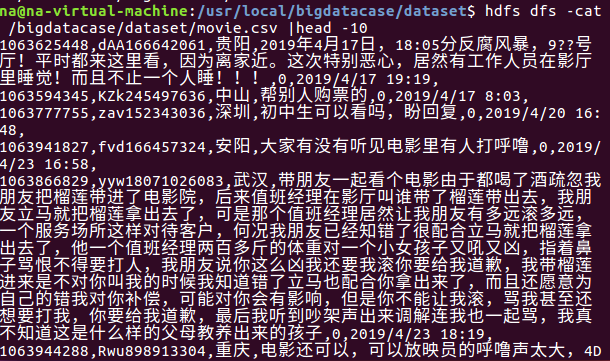
一:将爬虫大作业产生的csv文件上传到HDFS

查看文件中前10条信息,即可证明是否上传成功。
二.对CSV文件进行预处理生成无标题文本文件
创建一个deal.sh,主要实现数据分割成什么样的意思
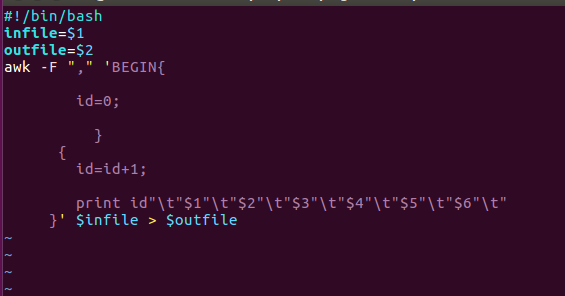
执行deal.sh 对数据进行分割预处理并输出形成movie.txt

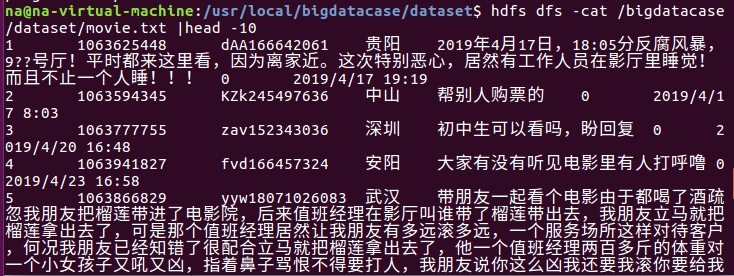
三.把hdfs中的文本文件最终导入到数据仓库Hive中

同样的,查看数据前10显示出来,和前面的csv对面显得很整齐,这就是处理数据后的样子。
四.在Hive中查看并分析数据
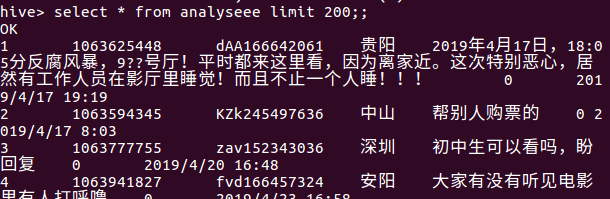
首先启动hive之后进行创建数据库再创表,语句如图下:

然后再查看一下数据,显示的数据格式正确即正确。
五.用Hive对爬虫大作业产生的进行数据分析
1.用户满意度分析:
在数据中分别获取评分为5,4,3,2,1的数量,然后进行分析,获取的数据如图所示:
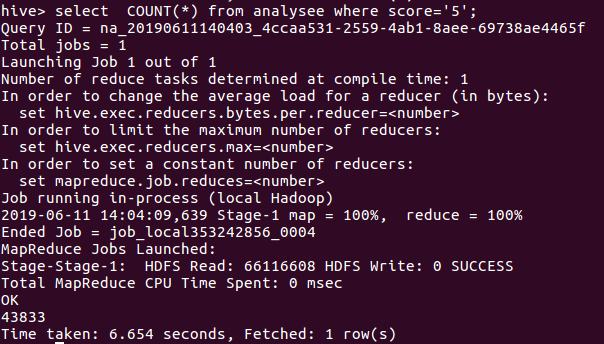
评分为5的数量

评分为4的数量
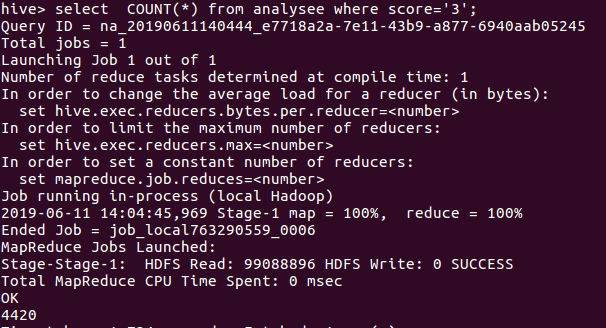
评分为3的数量

评分为2的数量

评分为1的数量
根据统计数据,做出了饼图,如图所示:
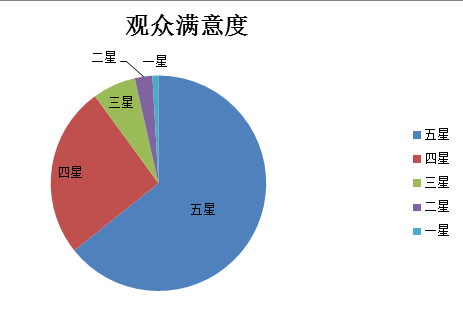
由图可以看出四星以上占据了大部分,于是我在计算一下影片的平均数,如图所示
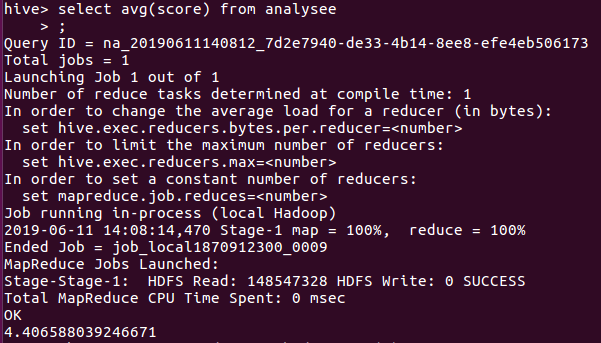
平均数为4.4左右,更加能够证明用户对该影片的满意度较高!
2.用户所在城市分析
统计出粉丝所在城市数量最多的20个城市

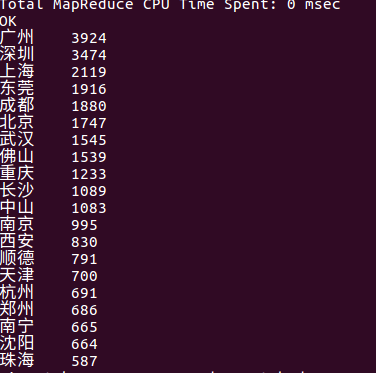
评分星级大于4的粉丝集中所在的排名前20的城市。


从数据我们可以看出,观众所在最多的20个城市都是属于比较经济发达的城市,基本都是一线,二线城市,他们在影视方面为贡献了一些GDP,同时从一些方面上可以体会为当地居民的生活恩格尔系数是不低的。
3.观众对影片的关注度
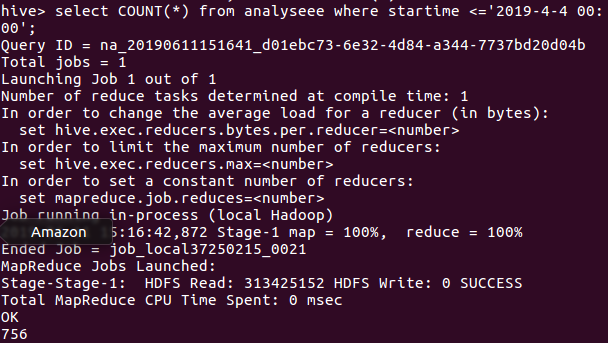
一部热门的影片在还没开始上映时就可以受到观众的关注,关注度的大小在一定程度上看出了观众对观看该影片的渴望度。
遇上统计了一下还没开始上映就有评论的数量,该影片的上映日期是2019-4-4,故我们可以看出在该日期之前的评论是756条,说明该片的关注度还是OK的。
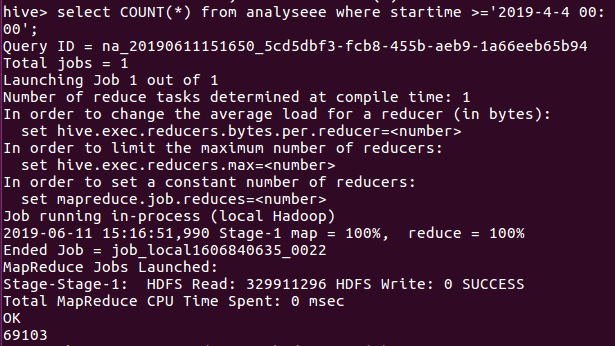
剩下的数量就是看完之后才会有的评论,69103条,说明该影片给观众多少留下一些印象。
4.观众观看时间分析
统计一下观众在某个时间片刻评论的数量多,证明着用户在评论时间的差不多时间就观看了电影,统计如下图所示:

因此我们可以推断出观众在观看该影片大多时间都是在傍晚场至晚上场。
于是接着统计一下上映7天每天的数量,由于数据中的日期数据类型比较特殊,如果直接统计需要进行数据类型转化有点麻烦,故我各自统计了每天的数量
由图下的语句进行统计4月4日的数量,类推得到7天每天的数量。
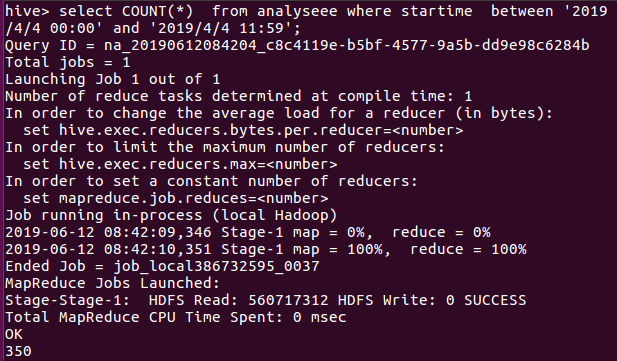
一直到4月11号,同样的语句就不放太多图了。。。
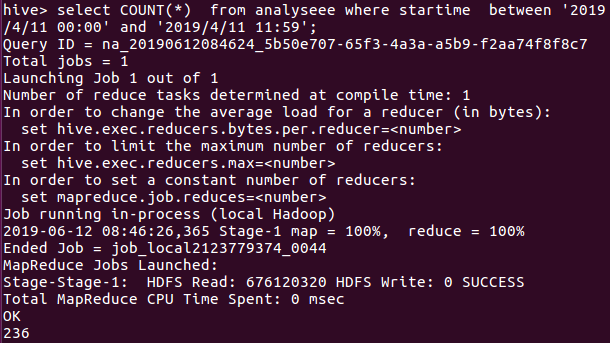
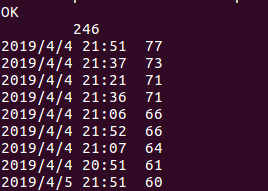
于是整理了一下,4月4日-4月11日的数量分别是350,699,949,714,485,342,275,236
从数据中可以看出6日的观众评论数是最多的,再弄一个折线波动图就更直观了。
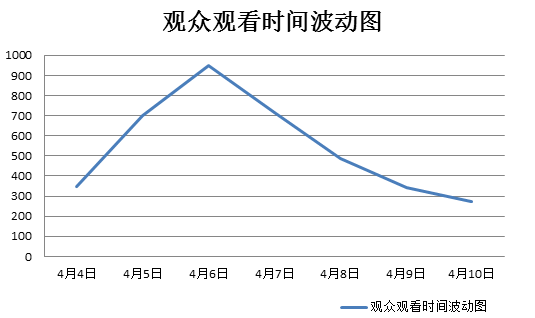
从图中我们很直观地看出了在影片在开播7日之内,6日的观看数(评论数)是最多的!
5.出现的问题解决:
1.在做这个过程中,数据在导入到hive时有分数列和时间列的数据出现NULL,如图所示:
通过查找资料,解决方案为:重新建立表,然后把日期列和分数列的数据类型写成STRING就可以了,然后就会发现数据格式是正确的!
2.当我统计7天内的总数据量使用语句select * from analysee(表) where startime between ''2019/4/4 11:11‘ and '2019/4/10 11:11'时一直显示为0.
解决方案:由于我这里的数据格式为:2019/4/4 11:11,数据不是为date,故直接使用
故有两种解决方案,一:把日期列的数据进行格式化为’2019-1-2’,这样的话容易比较,就是有点复杂而已
二:简单思路多重复是记录每一天是数据量(我使用的是此方案,若数据天数太多则不建议)
三:在导入之前先用excel设计好自己想要的格式再重新上传到hdfs和hive中,结果会很方便