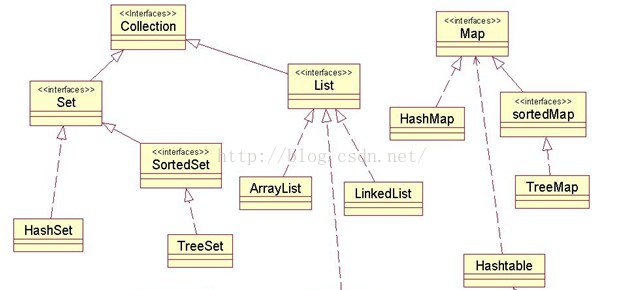
List 和 Set 都实现了Collection 接口,而 Map 则没有。
(1) List(有序可重复)
List 采用线性方式存储,可存放重复的数据。它有两个子类:ArrayList、LinkedList。
ArrayList 底层是一个Object[]数组,意味着它有数组的特性,但是它比数组更灵活,无需设置长度,可以动态增长,并且是有序的,可以进行随机访问,所以查找快。所以 ArrayList 代表长度可以改变的数组,可以对元素进行随机访问。
ArrayList 有一个兄弟 Vector,Vector 和 ArrayList 不一样的是:Vector 的方法之间是线程同步的,是线程安全的,效率较低;而 ArrayList 是异步的,是非线程安全的,效率较高。相比之下,建议使用 ArrayList。
LinkedList 的底层是采用链表方式进行排序的,执行增删操作时,只需更改被更新元素前后的关联即可。所以建议查询用 ArrayList,而增删用 LinkedList。
(2) Set(无序不可重复)
Set存放的是对象的引用,没有重复的对象。
无序不可重复,指的是重复的元素会被覆盖掉;这里的无序是针对放入顺序而言的,并不是绝对的无序。
Set 集合有两个子类,HashSet、TreeSet。
HashSet 是基于Hash算法实现的,它的底层是 HashMap,有着HashMap中键的无序和不可重复的特性。
TreeSet 实现了SortedSet接口,SortedSet 有排序的能力,意味着TreeSet 也有排序的能力,它是使用二叉树进行排序的,不允许放入 null 值。
①HashSet:按照Hash算法来存取集合中的对象,存取速度比较快。
②TreeSet:实现了SortedSet 接口,能对集合中的对象进行排序。
③LinkedHashSet:内部使用链表维护元素顺序,因此遍历时返回的是插入顺序。具有HashMap 的查询速度。
(3) HashMap(以键值对形式存储)
Map 存在的意义就是为了快速查找,因为键是不可重复的,因此可以通过键直接找到值。
实现Map 接口的子类有三个,HashMap、HashTable、TreeMap。
HashMap 和 HashTable 底层都是Hash 表结构,不一样的是:HashMap 的线程是不安全的,允许键值对为null,而HashTable 是线程安全的,不允许键值对为null,两者的使用要看具体情况而定。
TreeMap 实现了SortedMap 接口,底层是二叉树,可用于给 Map 集合中的键值进行排序。且TreeMap的线程是不同步的。
Map中元素,可以将key序列和value序列单独抽取出来。
使用 keySet() 抽取 key 序列,将 map 中的所有 keys 生成一个 Set。
使用 values() 抽取 value 序列,将 map 中的所有values 生成一个 Collection。
为什么一个生成Set,而一个生成 Collection?
因为 key 总是独一无二的,而 value 允许重复。
①HashMap:基于散列表的实现,插入和查询键值对的开销是固定的。
②TreeMap:基于红黑树的数据结构,遍历时取得的数据是经过内部排序的,同时也是唯一一个带有 subMap 方法的 Map。
③LinkedHashMap:内部使用链表维护元素顺序,因此遍历时返回的是插入次序。
ArrayList、HashSet、HashMap都在 java.util 包下
ArrayList
构造方法-----如果不传参数,默认底层数组的长度是10;如果传了参数,则底层数组的长度和参数相同。
size方法-----返回集合的长度(添加才算)。
add方法-----向集合中添加元素,每添加一个,长度就加1,size++。
添加元素时,一旦长度超过底层数组长度则自动扩容,每次扩展远长度*1.5 ------oldCapacity+(oldCapacity>>1)
使用add方法向指定的 List 索引中添加元素,如果当前元素有内容,则该位置的元素及其后续元素的索引会自动加1
get方法-----传下标,取元素。
remove-----传下标,删除元素。
contains-----传一个元素,返回元素是否存在于集合中。
HashSet
不能通过 get方法来取出元素,需要通过增强 for循环来遍历输出。
HashMap-----映射,键值对
put方法-----存放,过程中键的值不可重复,重复会覆盖掉原来的值。
get方法-----传key,取value。
HashMap不支持增强 for循环,要输出集合中的元素,可通过keySet()方法,转换为Set,然后输出。
containsKey方法,判断key是否存在。
containsValue方法,判断value是否存在。
Iterator 是集合类的通用遍历方式
若有错误之处,欢迎指正。谢谢!