- NoSQL的引言
- Redis数据库相关指令
- Redis持久化相关机制
- SpringBoot操作Redis
- Redis分布式缓存实现
- Resis中主从复制架构和哨兵机制
- Redis集群搭建
- Redis实现分布式Session管理
一、NoSQL的引言
1、定义:
NoSQL(not only sql),意即不仅仅是sql,泛指非关系型数据库。
RDMS:关系型数据库
NoSQL:泛指非关系数据库
2、为什么是NoSQL
随着互联网的兴起,传统的关系数据库在应付动态网站,特别是超大规模和高并发的纯动态网站已经显得力不从心,暴露了很多难以克服的问题。如商城网站中对商品数据频繁查询、对热搜商品的排行统计等相关使用传统的关系型数据库实现就显得非常复杂,虽然能实现相应功能但是在性能上却不是那么乐观。nosql技术门类的出现,更好的解决了这个问题。
3、NoSQL的四大分类
1)键值(key-value)存储数据库
(1)说明:这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
(2)特点:key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,key/value就显得效率低下了。
(3)相关产品:Redis、SSDB、oracle BDB、Voldemort等
2)列存储数据库
(1)说明:这部分数据库通常是用来应对分布式存储的海量数据。
(2)特点:键仍然存在,但是它们的特点是指向了多个列,这些列是由列家族来安排的
(3)相关产品:cassandra、Hbase、Riak
3)文档型数据库
(1)说明:文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一中键值存储相类似,该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看做键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
(2)特点:以文档形式存储
(3)相关产品:MonoDB、CouchDB、SequoidDB
4)图形(Graph)数据库
(1)说明:图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。
(2)特点:NoSQL数据库没有标准的查询语言(SQL)因此进行数据库查询需要制定数据库模型。许多NoSQL数据库都有REST式的数据接口或者查询API。
(3)相关产品:Neo4J、InfoGrid、Infinite Graph
4、NoSQL应用场景
1)数据模型比较简单
2)需要灵活性更强的IT系统
3)对数据库性能要求比较高
4)不需要高度的数据一致性
5、什么是Redis
1)定义:是一个开源的遵循BSD协议的,基于内存数据存储的被用于作为数据库缓存的消息中间件。
2)特点:是一个高性能key/value内存型数据库;支持丰富的数据结构;支持持久化;单线程、单进程;
4)缓存击穿:客户端查询了一个数据库中没有的数据记录导致缓存在这种情况下无法利用,称之为缓存穿透或者缓存击穿(解决方案:mybatis中cache解决了缓存穿透:将数据库中没有查询到结果也进行缓存)。
5)缓存雪崩:在系统运行的某一时刻,突然系统中缓存全部失效,恰好在这一时刻涌来大量客户端请求,导致所有模块缓存无法利用,大量请求涌向数据库的极端情况,数据库阻塞或挂起。(解决方案:针对于不同业务数据设置不同超时时间)
二、Redis数据库相关指令
1、数据库操作指令
1)数据库操作指令
(1)Redis中库说明:使用redis的默认配置器启动redis服务后,默认会存在16个库,编号从0~15;可以使用select 库的编号 来选择一个redis库。
(2)Redis中操作库的指令:清空当前的库:FLUSHDB 清空所有的库:FLUSHALL
2、操作key相关指令
1)操作key相关指令
(1)DEL指令:删除指定的一个或多个key。不存在的key会被忽略,返回被删除key的数量。
(2)EXISTS指令:检查给定key是否存在。如果key存在,返回1,否则返回0。
(3)EXPIRE指令:为给定key设置生存时间(单位秒),当key过期时(生存时间为0),它会被自动删除。设置成功返回1。
(4)KEYS指令:查找所有符合给定模式pattern的key。返回符合给定模式的key列表。
(5)MOVE指令:将当前数据库的key移动到给定的数据库db当中。移动成功返回1,失败则返回0。
(6)PEXPIRE指令:这个命令和EXPIRE命令相似,但是它是以毫秒为单位设置key的生存时间。设置成功返回1,key不存在或设置失败返回0。
(7)PEXPIREAT指令:这个命令和EXPIREAT命令相似,但它以毫秒为单位设置key的过期unix时间戳,而不是像EXPIREAT那样,以秒为单位。如果生存时间设置成功,返回1,当key不存在或者没有办法设置生存时间时,返回0。
(8)TTL指令:以秒为单位,返回给定key的剩余生存时间。当key不存在时,返回-2,当key存在但没有设置生存时间时,返回-1,否则,以秒为单位,返回key的生存时间。
(9)PTTL指令:这个命令类似于TTL,但它以毫秒为单位返回key的剩余生存时间,而不是像TTL命令那样,以秒为单位。
(10)RANDOMKEY指令:从当前数据库中随机返回(不删除)一个key。当数据库不为空时,返回一个key,当数据库为空时,返回nil。
(11)RENAME指令:将key改名为newkey。当key和newkey相同,或者key不存在时,返回一个错误。当newkey已经存在时,RENAME将覆盖旧值。改名成功时提示ok,失败时候返回一个错误。
(12)TYPE指令:返回key所存储的值的类型。返回值:none(key不存在),string(字符串),list(列表),set(集合),zset(有序集),hash(哈希表)。
3、redis数据类型
1)操作String类型
常用命令set/get key value等
2)操作List类型
常用命令lpush/lpop key value、rpush/rpop key value、lrange key 0 -1等
3)操作Set类型(无序,不可以重复)
常用命令sadd key member、smembers key、srem key member等
4)操作ZSet类型(有序,不可以重复)
常用命令zadd key 5member、zscore key member、zrange key 0 -1、zrem key member等
5)操作hash类型(key/value是一个map,并且value也是一个map结构,存在key/value,无序)
常用命令hset key field value、hget key field、hgetall key、hdel key field、hkeys key、hvals key等
4、可视化工具
redis-desktop-manage.rar
三、Redis持久化机制
redis官方提供了两种不同的持久化方法来将数据存储到硬盘里面,分别是:快照(snapshot),AOF(append only file)只追加日志文件。
1、快照持久化
1)特点
这种方式可以将某一时刻的所有数据都写入硬盘中,当然这也是redis的默认开启的持久化方式,保存的文件是以.rdb形式结尾的文件,因此,这种方式也称之为RDB方式。
2)快照生成方式
(1)客户端方式-BGSAVE
客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork来创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求。
fork的意思:当一个进程创建子进程的时候,底层的操作系统会创建该进程的一个副本,在类unix系统中创建子进程的操作会进行优化:在刚开始的时候,父子进程共享相同内存,直到父进程或子进程对内存进行了写之后,对被写入的内存的共享才会结束服务。
(2)客户端方式-SAVE
客户端还可以使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器再快照创建完毕之前不再响应任何其他的命令。
注意:SAVE命令并不常用,使用该命令在创建快照的时候,redis处理阻塞状态,无法对外服务。
(3)服务器配置自动触发
如果用户在redis.conf中设置了save配置选项,redis会在save选项条件满足之后自动触发一次BGSAVE命令,如果设置多个save配置选项,当任意一个save配置选项条件满足,redis也会触发一次BGSAVE命令。
save 900 1
(4)服务器接收客户端shutdown命令
当redis通过shutdown指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有的客户端,不再执行客户端执行发送的任何命令,并且在save命令执行完毕之后关闭服务器器。
2、AOF持久化
1)特点
这种方式可以将所有客户端执行的写命令记录到日志文件中,AOF持久化会将被执行的写命令写到AOF的文件末尾,以此来记录数据发生的变化,因此只要redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集。
2)开启AOF持久化(默认不开启)
#redis.conf中开启aoff持久化 appendonly yes #指定生成文件名称 appendfilename "appendonly.aof"
3)日志追加频率
appendfsync everysec|always|no
(1)always(谨慎使用):每个redis写命令都要同步写入硬盘,严重降低redis速度。
(2)everysec(推荐):每秒执行一次同步,显式的将多个命令同步到磁盘。
(3)no(不推荐):由操作系统决定何时同步。
3、AOF文件的重写
1)AOF带来的问题
AOF的方式也同时带来了另一个问题,持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件,redis提供了aof重写机制。
2)AOF重写
用来在一定程度上减小AOF文件的体积。
3)触发重写方式
(1)客户端方式触发重写
执行BGREWRITEAOF命令(不会阻塞redis服务)
(2)服务器配置方式自动触发
配置redis.conf中的auto-rewrite-percentage选项:
如果设置auto-aof-rewrite-percentage值为100和auto-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64M时,并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percent设置为更大。
四、springboot操作redis
1、Java操作Redis服务
1)环境准备
(1)引入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.3</version>
</dependency>
(2)创建jedis对象(redis必须关闭防火墙,redis服务必须开启远程连接)
public class RedisDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.select(0);
//执行相关操作
System.out.println(jedis.get("sname"));
jedis.close();
}
}
2、springboot整合redis
SpringBoot Data Redis中提供了RedisTemplate和StringRedisTemplate,其中,StringRedisTemplate是RedisTemplate的子类。两个方法基本一致,不同之处主要体现在操作的数据类型不同,RedisTemplate中的两个泛型都是Object,意味着存储的key和value都可以是一个对象,而StringRedisTemplate的两个泛型都是String,意味着StringRedisTemplate的key和value都只能是字符串。
1)环境准备
(1)引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
(2)配置application.properties
spring.redis.host=127.0.0.1 spring.redis.port=6379 spring.redis.database=0
(3)使用
@SpringBootTest(classes = RedisApplication.class)
class RedisApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void contextLoads() {
stringRedisTemplate.opsForValue().set("sname","zhangsan");
System.out.println(stringRedisTemplate.opsForValue().get("sname"));
}
}
3、redis应用场景
1)利用redis中字符串类型完成项目中手机验证码存储的实现
2)利用redis中字符串类型完成具有时效性业务功能
3)利用redis分布式集群系统中Session共享等
4)利用redis的zset类型,完成排行榜之类功能
5)利用redis分布式缓存
6)利用redis存储认证之后token信息
7)利用redis解决分布式集群系统中分布式锁问题
五、redis分布式缓存实现
1、基本概念
2、利用mybatis自身本地缓存结合redis实现分布式缓存
<!--开启mybatis二级缓存--> <cache/>
(2)实体类实现Serializable接口
@Data
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private Integer id;
private String name;
private Integer age;
private String email;
}
2)redis实现分布式缓存
mybatis底层默认使用的是org.apache.ibatis.cache.impl.PerpetualCache实现。新建自定义类RedisCache实现Cache接口,并对接口里面的方法进行实现。
(1)因为新建的RedisCache不是由工厂管理所有不能直接注入redis的bean,要新建一个类ApplicationContextUtils来获取springboot创建好的工厂来获取redis的bean。
//用来获取springboot创建好的工厂
@Configuration
public class ApplicationContextUtils implements ApplicationContextAware {
//保留下来工厂
private static ApplicationContext applicationContext;
//将创建好的工厂以参数的形式传递给这个类
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
//提供在工厂中获取对象的方法
public static Object getBean(String beanName){
return applicationContext.getBean(beanName);
}
}
(2)新建自定义类RedisCache实现Cache接口
public class RedisCache implements Cache {
//必须存在的id mapper的namespace
private final String id;
//必须存在构造方法
public RedisCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public void putObject(Object key, Object value) {
getRedisTemplate().opsForHash().put(id.toString(), key.toString(), value);
}
@Override
public Object getObject(Object key) {
return getRedisTemplate().opsForHash().get(id.toString(), key.toString());
}
@Override
public Object removeObject(Object key) {
return null;
}
@Override
public void clear() {
getRedisTemplate().delete(id.toString());
}
@Override
public int getSize() {
return getRedisTemplate().opsForHash().size(id.toString()).intValue();
}
private RedisTemplate getRedisTemplate(){
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtils.getBean("redisTemplate");
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
(3)开启mybatis二级缓存,并使用自定义的cache类RedisCache
<!--开启mybatis二级缓存 使用自定义的cache类--> <cache type="com.icucoder.learn.cache.RedisCache"/>
(4)使用
3、redis分布式缓存优化策略
1)对放入redis中key进行优化:key的长度不能太长,尽可能将key设计简短一些。在redis整合mybatis过程中建议将key进行md5优化处理。
六、redis中主从复制架构和哨兵机制
1、主从复制
主从复制架构仅仅用来解决数据的冗余备份,从节点仅仅用来同步数据。
1)配置从节点在从节点的redis.conf配置从节点的端口,并配置slaveof
slaveof <masterip> <masterport>
注意: 无法解决master节点出现故障的自动故障转移
2、哨兵机制
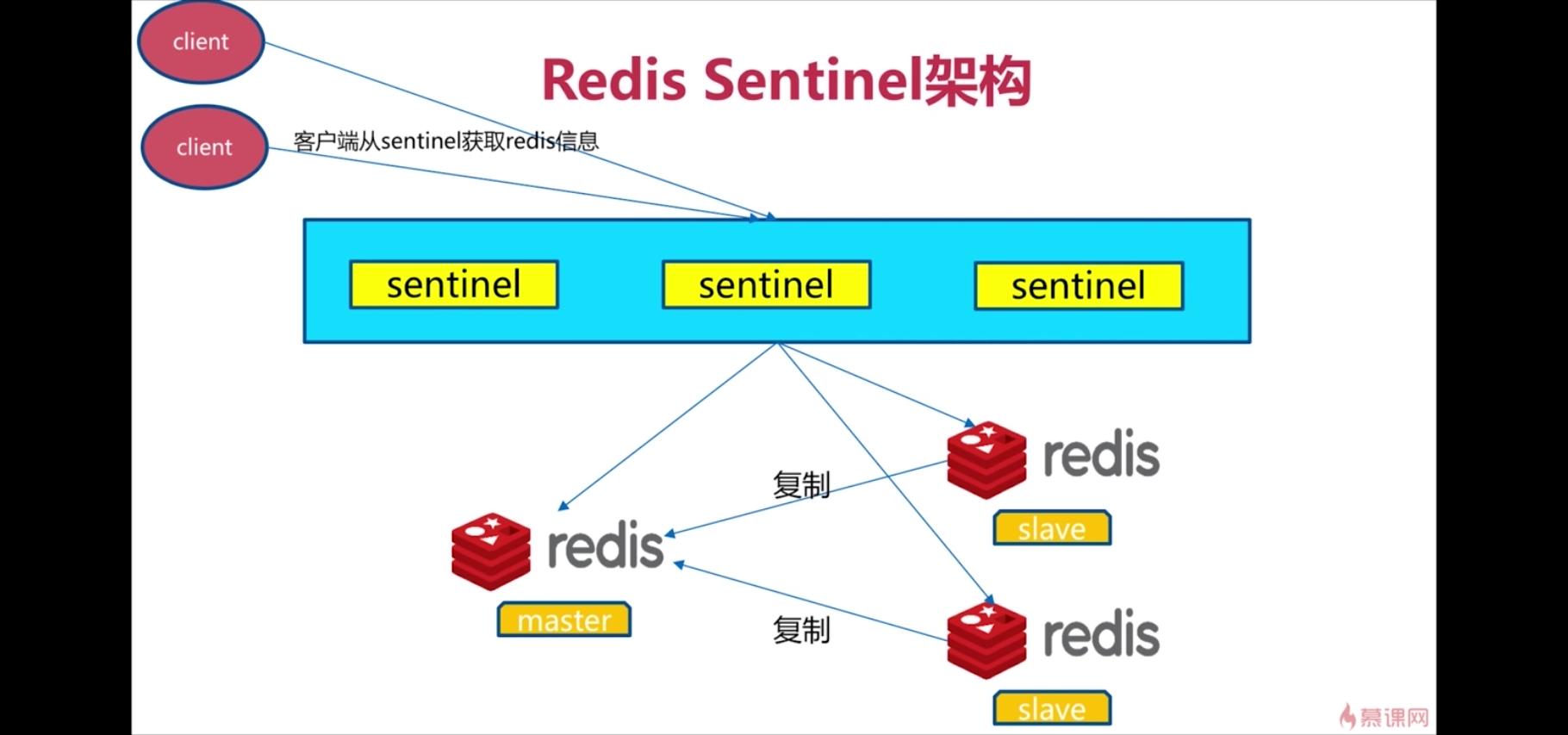
sentinel monitor 被监控主从架构名字(自己起名字) ip port 1
(3)启动哨兵模式进行测试
redis-sentinel /myredis/sentinel.conf
说明:这个后面的数字2,是指当有两个及以上的sentinel服务检测到master宕机,才会去执行主从切换的功能。
注意:无法解决单节点并发压力和单节点内存/磁盘物理上限。
3、springboot操作Redis哨兵集群
1)配置application.properties(原来的redis配置要注释掉)
#redis sentinel mymaster:被监控主从架构名字(自己起名字) spring.redis.sentinel.master=mymaster #连接哨兵 spring.redis.sentinel.nodes=127.0.0.1:26379
七、redis中集群
Redis在3.0后开始支持Cluster(集群)模式,目前redis的集群支持节点的自动发现,支持slave-master选举和容错,支持在线分片(sharding shard)等特性。
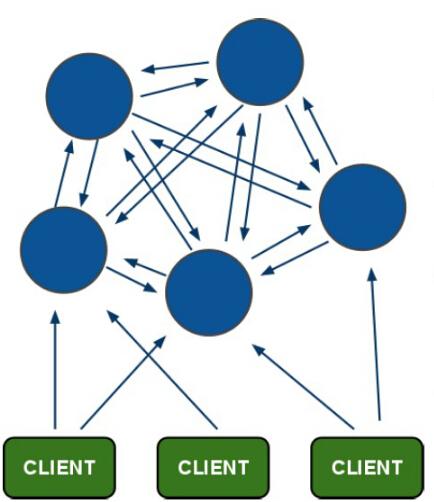
1、集群说明
1)集群细节
(1)所有redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效。
(3)客户端与redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
(4)redis-cluster把所有的物理节点映射[0-16383]slot上,cluster负责维护node<->slot<->value
2)集群搭建
判断一个集群中的节点是否可用,是集群中的所用主节点选举过程,如果半数以上的节点认为当前节点挂掉,那么当前节点就是挂掉了,所以搭建redis集群时建议节点数量最好为奇数,搭建集群至少需要三个主节点,三个从节点,至少需要6个节点。
八、redis实现分布式Session管理
redis的session管理是利用spring提供的session管理解决方案,将一个应用session交给redis存储,整个应用中所有session的请求都会去redis中获取对应的session数据。
1、Memcached与redis的session管理对比
1)MSM(memcached session manager):
整合:tomcat lib目录引入memcached整合jar,然后tomcat的配置文件配置tomcat整合memcached
原理:通过memcached整合tomcat应用服务,将应用服务中所有部署应用的session全部交给memcached进行管理
2)RSM(redis session manager):
整合:基于某个应用的整合
原理:基于应用方式session管理
2、开发Session管理
1)引入依赖
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2)开发session管理配置类
@Configuration
@EnableRedisHttpSession
public class RedisSessionManager {
}
3)打包测试(每次session变化都要同步session)
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
UserService userService;
@RequestMapping("/all")
public List<User> all(HttpServletRequest request) {
List<User> users = userService.getAll();
request.getSession().setAttribute("users", users);
return users;
}
}