1:多余的存储引用导致性能降低;
2:利用局部性提高程序性能;
先来说说引用是怎么降低程序性能,个人认为降低程序性能主要有两个原因,一是数据结构选择不合理,二是多层嵌套循环导致部分代码被多余重复执行。在第二种情况下我们一般都是优化循环最里层的代码,能提出来的尽量往外层提,实在不行的就优化它的运行速度。
1:多余的存储引用导致性能降低。先来看一个关于引用导致性能降低的问题。下面两个方法哪个更快。
static void Test2(ref int sum) { for (int i = 1; i <= timer; i++) { sum += i; } } static void Test3(ref int sum) { int tmpSum = sum; for (int i = 1; i <= timer; i++) { tmpSum += i; } sum = tmpSum; }
大致一看他们的性能应该没有差别,因为这两个方法其实就是利用一个循环求和,而真正能影响方法的性能就是这个循环,且两个方法的循环表面上看可以说是一样的,当,我令timer=10000000时,即求1+2+...+10000000的和,方法Test3的速度比Test2快。是的,Test3比Test2快,在某个区间内timer越大,性能差别越大。运行结构如下:

咱们直接来看反汇编代码,部分反汇编代码如下,我们只用看红线框着的部分。
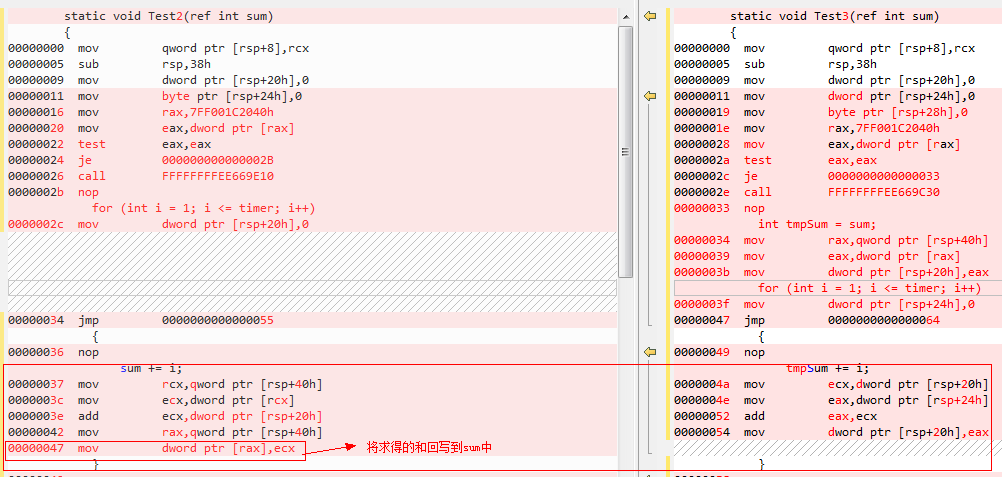
最主要的一句代码:sum+=i;方法Test2比方法Test3多了最后面一行,即将每次循环后求得的和回写到内存中,方法Test3却不用这么麻烦,只用一个寄存器,每次求得的和写到寄存器中,求完和后一次将和写到内存中。在每次循环中,Test2要读两次内存(sum和i都从内存中读),写一次内存(将求得的和写到内存中),而方法Test3只需要读一次内存,即从内存中读i的值,方法Test3的性能比Test2高就不言而喻了。就因为Test2每次都是以引用的方式读sum的值,CPU要得到sum的值,就得通过sum在内存中的地址,所以必读内存,,而Test3不必读内存,用一个寄存器即可。
2:利用局部性提高程序性能。还是直接看一个简单的例子
static int Test4(int[,] arr, int row, int column) { int sum = 0; for (int i = 0; i < row; i++) { for (int j = 0; j < column; j++) { sum += arr[i, j]; } } return sum; } static int Test5(int[,] arr, int row, int column) { int sum = 0; for (int j = 0; j < column; j++) { for (int i = 0; i < row; i++) { sum += arr[i, j]; } } return sum; }
简单一个看,两个方法几乎是完全一样,不同的是Test4是按行求和,而Test5是按列求和。如果多次执行这两个方法进行,对比就会方法Test4的性能高于Test5。运行两个方法100000次,结果如下:

为什么按行求和比按列求和快呢?简单一句话:数组是按行存的。CPU每次从内存读数据,不是要哪个就读哪个就直接读哪个,而是每次读一个高速缓存行,就是每次要多读一些,如,果需要的数据在高速缓存行中,就不用到内存中去读了,而是直接从高速缓存行中取,当然就比再从内存中读取要快一些。而在这里,数组按行存储,也就是说,CPU每次会读多个数组元素导高速缓存行,如果需要的元素在高速缓存行中就不用到内存中去取了,这就是传说中的命中率,按行求和命中率当然就高了。而按列求和,命中率自然低,CPU每次将一行中的多个元素读到高速缓存行中,按列求和每次只需要一个元素,也就是每次只需要一个元素而CPU却读了多个元素,命中率当然低,低到可能出现命中率为0。
程序的局部性包括:空间局部性和时间局部性,这里说的就是空间局部性。
空间局部性就是说一个被使用的到数据其周围的数据很可能会被马上使用。
时间局部性就是说一个被使用的到数据很可能会被再次使用。
更多内容请看《深入理解操作系统》。
作者:陈太汉