
1. 关键名词
1.1 Producer
1.消息的生产者,向Kafka Broker发送消息的客户端
1.2. Consumer
1.消息的消费者,向Kafka Broker接受消息的客户端
2.Consumer Group: 单个或多个consumer可以组成一个consumer group;这是Kafka用来实现消息的广播(发送给所有的consumer)的单播(发给任意一个consumer)。一个topic可以有多个Consumer Group.
1.3. Topic
topic
1.数据的逻辑分类。可以理解为数据库中“表”的概念。
partition
1.topic中数据的具体管理单元;一个topic可以划分为多个partition,分布到多个broker上管理。
2.每个partition由一个kafka broker服务器管理
3.partition中的每条消息被分配一个递增的ID(offset)
4.每个partition都是一个有序的队列,kafka只能保证一个partition中的消息的顺序,不能保证一个topic(多个partition间)的整体顺序
5.每个partition可以有多个副本
broker
1.一台kafka服务器就是一个broker。一个kafka集群由多个broker组成
2.一个broker服务器可以容纳多个topic的多个partition
3.分区对于kafka集群的好处是:实现topic数据的负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
offset
1.消息在底层存储中的索引位置,kafka的底层存储文件就是以文件中第一条消息的offset来命名的,通过offset可以快速定位到消息的具体存储位置。
1.4. Leader
1.partition replica中的一种角色。procucer和consumer只跟leader交互。(负责读写)
1.5. Replica
1.partition中的副本。保证partition的高可用。replica的副本数量不能大于kafka broker的节点数量,否则报错。
2.每个partition所在的副本中,必须包括一个leader副本,其他就是follower副本。
1.6. Follower
1.partition replica中一个角色,从leader中拉取复制数据(只负责备份数据)
2.如果leader所在节点宕机,follower会选举出新的leader
1.7. Offset
1.每条数据都有一个offset,是数据在该partition中的唯一标识(消息的索引号)。
2.各个consumer会保存其消费到的offset位置,这样下次可以从该offset位置继续消费;consumer消费的offset保存在一个专门的topic中(—consumer_offsets)
1.8. Message
1.在客户端编程代码中,消息的类叫做: ProducerReord, ConsumerRecord. 简单来说kafka每一个message由一对key-value组成。
关于Kafka消息格式的演变,可以查看:一文看懂Kafka消息格式的演变
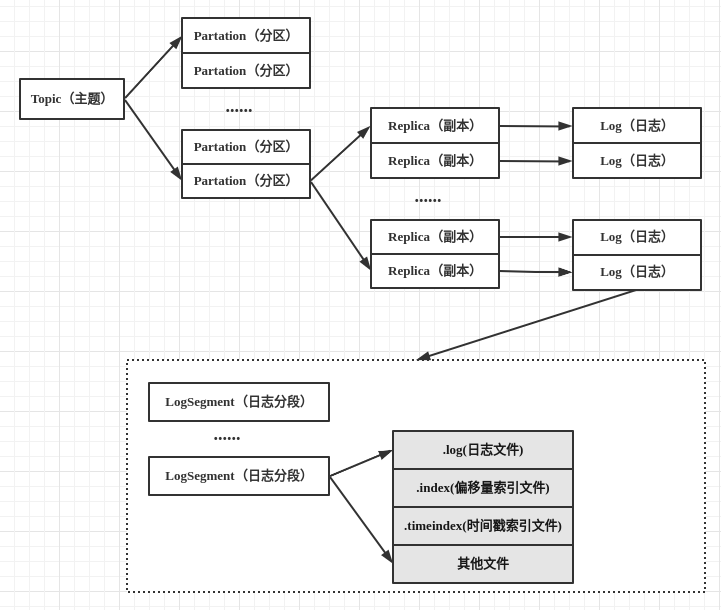
一个Topic可以有多个Partation,每个分区内的消息可以保证顺序性(如果要保证消息被顺序消费可以一个topic只配置一个partation),每个分区可以有多个Replica,每个副本在不同的Broker上(Broker对应一台服务器),每个log就是对应一个文件夹
2. Kafka命令行工具
Kafka提供了许多命令行工具(默认位于/opt/${kafka}/bin目录下)用于管理集群
kafka-console-producer.sh kafka-console-producer.sh 脚本是一个简易的生产者控制台。(https://blog.csdn.net/qq_29116427/article/details/105912397) kafka-consumer-groups.sh kafka查看消费组 kafka-consumer-perf-test.sh kafka消费者性能测试脚本 kafka-delegation-tokens.sh kafka-delegation-tokens.sh 用于管理Delegation Token。基于Delegation Token的认证是一种轻量级的认证机制,是对SASL认证机制的补充。 kafka-delete-records.sh kafka-delete-records.sh用于删除Kafka的分区消息,由于Kafka有自己的自动消息删除策略,使用率不高。 kafka-dump-log.sh kafka-dump-log.sh用于查看Kafka消息文件的内容,包括消息的各种元数据信息、消息体数据。 kafka-features.sh kafka-features.sh用于特性版本控制 (2.7 新增:https://github.com/apache/kafka/pull/9409) kafka-leader-election.sh kafka-leader-election.sh命令行工具进行分区领导选举 kafka-log-dirs.sh kafka-log-dirs.sh用于查询各个Broker上的各个日志路径的磁盘占用情况 kafka-mirror-maker.sh kafka-mirror-maker.sh用于在Kafka集群间实现数据镜像。 kafka-preferred-replica-election.sh kafka-preferred-replica-election.sh用于执行Preferred Leader选举,可以为指定的主题执行更换Leader的操作。 kafka-producer-perf-test.sh kafka-producer-perf-test.sh用于生产者性能测试。 kafka-reassign-partitions.sh kafka-reassign-partitions.sh用于执行分区副本迁移以及副本文件路径迁移。 kafka-replica-verification.sh kafka-replica-verification.sh用来验证所指定的一个或多个Topic下每个Partition对应的所有Replica是否都同步。可通过topic-white-list这一参数指定所需要验证的所有Topic,支持正则表达式。 kafka-run-class.sh kafka-run-class.sh用于执行任何带main方法的Kafka类。 kafka-server-start.sh kafka-server-start.sh用于启动Broker进程。 kafka-server-stop.sh kafka-server-stop.sh用于停止Broker进程。 kafka-streams-application-reset.sh kafka-streams-application-reset.sh用于给Kafka Streams应用程序重设位移,以便重新消费数据。 kafka-topics.sh kafka-topics.sh用于创建、删除、修改、查看某个Topic,也可用于列出所有Topic。另外,该工具还可修改某个Topic的以下配置。 kafka-verifiable-consumer.sh kafka-verifiable-consumer.sh用于测试验证消费者功能。 kafka-verifiable-producer.sh kafka-verifiable-producer.sh用于测试验证生产者的功能。 trogdor.sh trogdor.sh是Kafka的测试框架,用于执行各种基准测试和负载测试。 zookeeper-security-migration.sh zookeeper-security-migration.sh用于更新kafka数据中的zookeeper的 ACL,执行ACL的迁移 zookeeper-server-start.sh zookeeper-server-start.sh 用于启动zookeeper服务 zookeeper-server-stop.sh zookeeper-server-start.sh 用于停止zookeeper服务 zookeeper-shell.sh zookeeper-shell.sh作用是连接zookeeper,并通过命令查询注册的信息