十:DDM数据操作(Data Manipulation Language 数据操作语言)
A: 基本数据操作及导入导出
1)向表中加载数据
load data local inpath '/root/itstar.txt' into table hunter;
2)加载hdfs中数据
load data inpath '/hunter,txt' into table hunter;
提示:相当于剪切
3)覆盖原有的数据
load data local inpath '/root/itstar.txt' overwrite into table hunter;
4)创建分区表
create table hunter_partitions(id int,name string) partitioned by (month string) row format
delimited fields terminated by ' ';
5)向分区表插入数据
insert into table hunter_partitions partition(month='201811') values(1,'tongliya');
6)按照条件查询结果存储到新表
create table if not exists hunter_ppp as select * from hunter_partitions
where name='tongliya';
7)创建表时加载数据
> create table db_h(id int,name string)
> row format
> delimited fields
> terminated by " "
> location '';
8)查询结果导出到本地
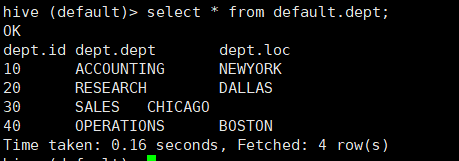
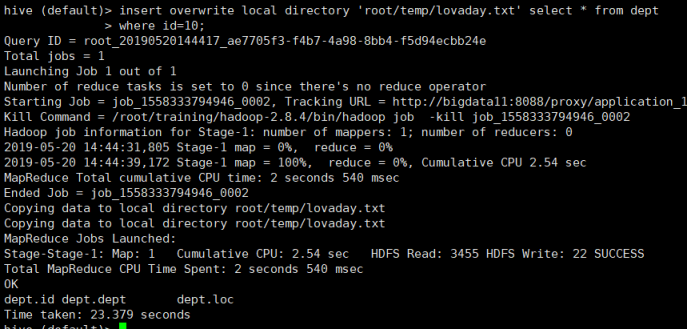
方法1:insert overwrite local directory '/root/temp/lovaday.txt' select * from dept where id=10;
Bug1:不知道为什么导入数据的时候,运行成功但是就是没有直接导入到本地!(后面再解决吧!!)
方法2:bin/hive -e 'select * from hunter' > /root/hunter.txt
方法3:> dfs -get /usr/hive/warehouse/00000 /root;(就是从hdfs上下载到本地了)

B: 查询
1)配置查询头信息
在hive-site.xml
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
这样显示效果更好

2) 基本查询
-》全表查询
select * from empt;
-》查询指定列
select empt.empno,empt.empname from empt;
-》列别名
select ename name,empno from empt;
-》算数运算符
算数运算符 描述
+ 相加
- 相减
* 相乘
/ 相除
% 取余
& 按位取与
| 按位取或
^ 异或
~ 按位取反
》函数
(1)求行数count
select count(*) from empt;
(2)求最大值max
select max(empt.sal) sal_max from empt;
(3)求最小值
select min(empt.sal) sal_min from empt;
(4)求总和
select sum(empt.sal) sal_sum from empt;
(5)求平均值
select avg(empt.sal) sal_avg from empt;
(6)前两条
select * from empt limit 2;
-》where语句
(1)工资大于1700的员工信息
select * from empt where empt.sal > 1700;
(2)工资小于1800的员工信息
select * from empt where empt.sal < 1800;
(3)查询工资在1500到1800区间的员工信息
select * from empt where empt.sal between 1500 and 1800;
(4)查询有奖金的员工信息
select *from empt where empt.comm is not null;
(5)查询无奖金的员工信息
select * from empt where empt.comm is null;
(6)查询工资是1700和1900的员工信息
select * from empt where empt.sal in(1700,1900);
-》Like
使用like运算选择类似的值
选择条件可以包含字母和数字
(1)查找员工薪水第二位为6的员工信息
select * from empt where empt.sal like '_6%';
_代表一个字符, %代表0个或多个字符
(2)查找员工薪水中包含7的员工信息
select * from empt where empt.sal like '%7%';
-》rlike(支持正则表达式,更加强大)
select * from empt where empt.sal rlike '[7]';
-》分组
(1)Group By语句
计算empt表每个部门的平均工资
select avg(empt.sal) avg_sal,deptno from empt group by deptno;select
avg(empt.sal) avg_sal,deptno from empt group by deptno;
(2)计算empt每个部门中最高的薪水
select max(empt.sal) max_sal,deptno from empt group by deptno;
(3)求部门平均薪水大于1700的部门
select deptno,avg(sal) avg_sal from empt group by deptno having avg_sal>1700;
注意:having只用于group by分组统计语句
-》Join操作
(1)等值join
根据员工表和部门表中部门编号相等,查询员工编号、员工名、部门名称
select e.empno,e.ename,d.dept from empt e join dept d on e.deptno=d.deptn
o;
(2)左外连接 left join
null
select e.empno,e.ename,d.dept from empt e left join dept d on e.deptno=d.
deptno;
(3)右外连接 right join
select e.empno,e.ename,d.dept from dept d right join empt e on e.deptno=
d.deptno;
(4)多表连接查询
查询员工名字、部门名称、员工地址
select e.ename,d.dept,l.loc_name from empt e join dept d on e.deptno=d.de
ptno join location l on d.loc = l.loc_no;
(5)笛卡尔积
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员 。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
select ename,dept from empt,dept;对于这个来说按理说就应该是错的,应为没有条件,
查询出来的就是笛卡尔全集,每一种结果都会出现。
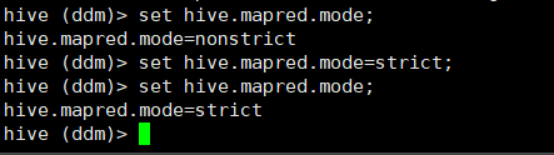
为了避免笛卡尔积采用设置为严格模式
set hive.mapred.mode = strict
-》排序
(1)全局排序 order by
查询员工信息按照工资升序排列
select * from empt order by sal asc;默认
select * from empt order by sal desc;降序
(2)查询员工号与员工薪水按照员工二倍工资排序
select empt.empno,empt.sal*2 two2sal from empt order by two2sal;
(3)分区排序
select * from empt distribute by deptno sort by empno desc;
-》分桶
分区表分的是数据的存储路径
分桶针对数据文件
(1)创建分桶表
create table emp_buck(id int,name string)
clustered by(id) into 4 buckets
row format
delimited fields
terminated by ' ';
(2) 设置属性
我们需要确保reduce 的数量与表中的bucket 数量一致,一个桶要进行一个reduce.task为此有两种做法
方法1 让hive强制分桶,自动按照分桶表的bucket 进行分桶。(推荐):
set hive.enforce.bucketing=true;
方法2 手动指定reduce数量:
set mapreduce.reduce.tasks = num;
(3)导入数据(不能直接将数据导入到桶表中)
如何将数据插入分桶表
将数据导入分桶表主要通过以下步骤
第一步:
从hdfs或本地磁盘中load数据,导入中间表
第二步:
通过从中间表查询的方式的完成数据导入
insert into table dawn_buck select * from transitionbuck;
注意:分区分的是文件夹 分桶是分的文件
抽样测试
关于桶表的详细资料可以参考这个文章,我觉得写的挺好的。我这里写的很简陋
https://www.jianshu.com/p/32011e9146ef