1大数据解决的问题?
海量数据的存储:hadoop->分布式文件系统HDFS
海量数据的计算:hadoop->分布式计算框架MapReduce
2什么是MapReduce?
分布式程序的编程框架,java->ssh ssm ,目的:简化开发!
是基于hadoop的数据分析应用的核心框架。
mapreduce的功能:将用户编写的业务逻辑代码和自带默认组件整合成一个完整的
分布式运算程序,并发的运行在hadoop集群上。
3 MapReduce的优缺点
优点:
(1)易于编程
(2)良好的拓展性
(3)高容错性
(4)适合处理PB级别以上的离线处理
缺点:
(1)不擅长做实时计算
(2)不擅长做流式计算(mr的数据源是静态的)
(3)不支持DAG(有向图)计算(spark)
MapReduce核心编程思想图:
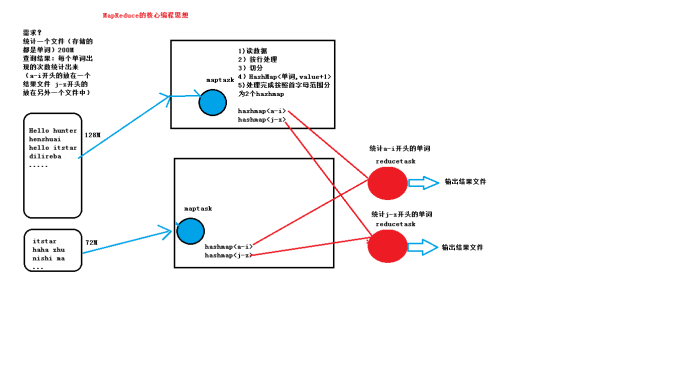
4自动化调度平台yarn(mr程序的运行平台)
mr程序应该在多台机器上运行启动,而且要先执行maptask,等待每个maptask都处理完成后
还要启动很多个reducetask,这个过程要用户手动调用任务不太现实,
需要一个自动化的任务调度平台->hadoop当中2.x中提供了一个分布式调度平台-YARN
Yarn任务提交流程图
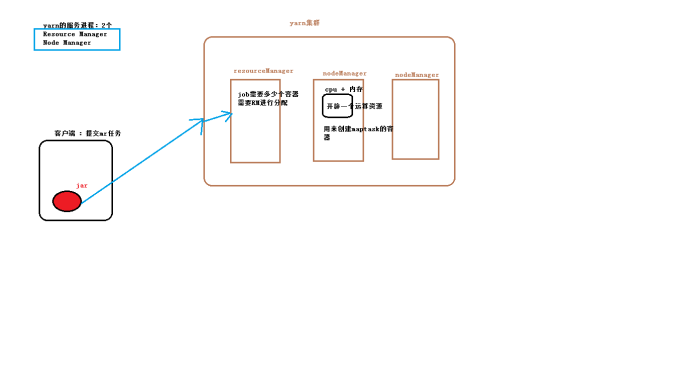
5搭建yarn集群
(1)修改配置文件 yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata11</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(2)然后复制到每台机器 $PWD 当前目录
scp yarn-site.xml root@bigdata12:$PWD
scp yarn-site.xml root@bigdata13:$PWD
(3)修改slaves文件(之前配置了就不用再配了)
然后在bigdata11上,修改hadoop的slaves文件,列入要启动nodemanager的机器
然后将bigdata11到所有机器的免密登陆配置好
(4)脚本启动yarn集群:
启动:
sbin/start-yarn.sh
停止:
sbin/stop-yarn.sh
(5)访问web端口
启动完成后,可以在windows上用浏览器访问resourcemanager的web端口:
http://bigdata11:8088