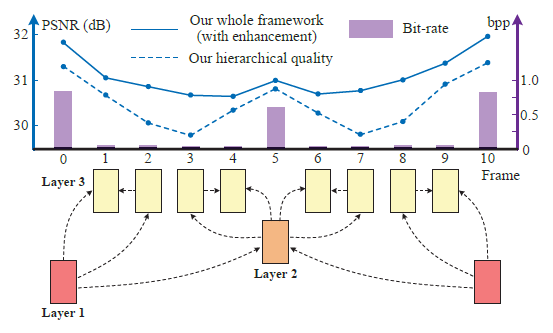
用三层分层的网络来逐步压缩,第一层得到的帧质量最高,第二层其次,第三层质量最低。再通过循环增强网络来从质量高的图像中提取信息去增强质量低的图像。(插值?)
First layer: compress by an image compression method with the highest quality(libbpq)
Second layer: Bi-Directional Deep Compression(BDDC) network
Third layer: Single Motion Deep Compression(SMDC) network
Code: https://github.com/RenYang-home/HLVC
Overview:
Bi-Directional Deep Compresion, BDDC:
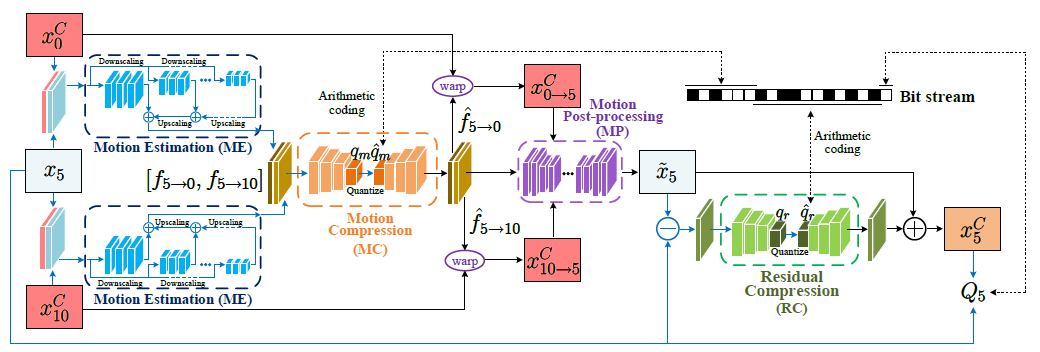
(x_0^C)和(x_10^C)表示第0帧和第10帧压缩后的图像,先经过Motion Estimation,估计运动信息([ f_{5 o 0}, f_{5 o 10} ]),经过Motion Compression后分别将(x_0^C)和(x_10^C)用这两个运动信息扭曲(Motion Compensation),然后送进Motion Post-processing,合并这两帧warped frames,得到预测帧,再将预测帧和原始图像作差得到residual,压缩residual再加上预测帧得到重构帧(压缩后的帧)(x_5^C)
Single Motion Deep Compression, SMDC:
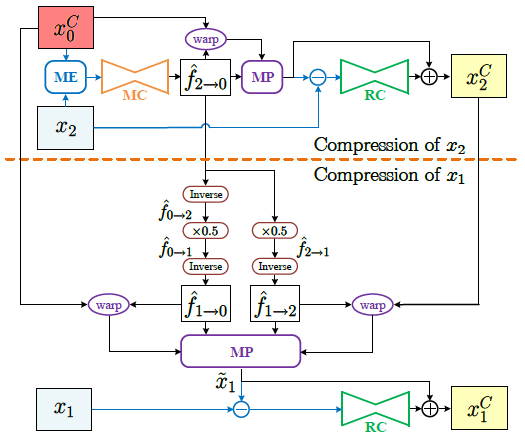
上图中举得例子是用第0帧来增强第1帧和第2帧的质量。先压缩第2帧得到(x_2^C),用的方法类似于BDDC,只是不是Bi-Directional ,只有一个运动信息。然后下面是将(hat{f}_{2 o 0})直接变成(hat{f}_{1 o 0})和(hat{f}_{1 o 2}),因为连续帧之间的运动信息相似。再通过Motion Post-processing合并扭曲后的帧,计算residual,压缩residual,再重构得到重构帧(x_1^C)
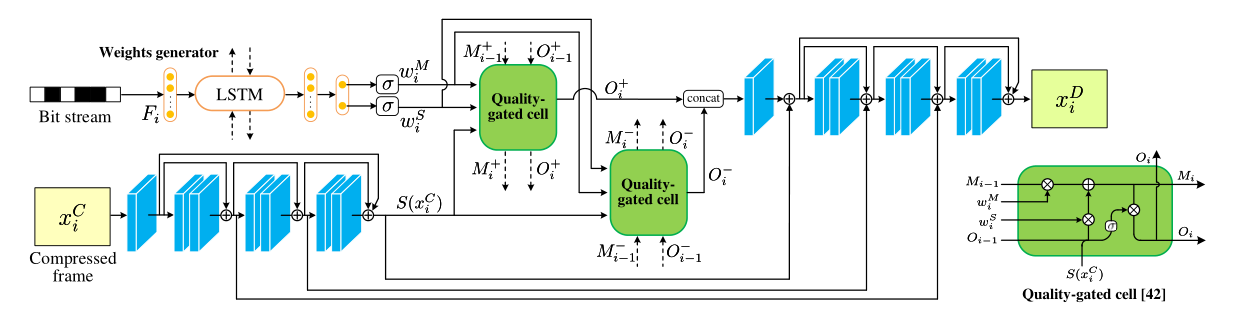
Weighted Recurrent Enhancement, WRQE:
编码端在后面用WRQE增强图像质量,based on QG-ConvLSTM Quality-gated convolutional LSTM for enhancing compressed video
代码里没有这段emmmmmm