代码
import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM import marksix_1 import talib as ta lt = marksix_1.Marksix() lt.load_data(period=500) # 指标序列 m = 2 series = lt.adapter(loc='0000001', zb_name='mod', args=(m, lt.get_mod_list(m)), tf_n=0) # 实时线 close = np.cumsum(series).astype(float) # 布林线 timeperiod = 5 upper, middle, lower = ta.BBANDS(close, timeperiod=timeperiod, nbdevup=2, nbdevdn=2, matype=0) # 趋势 qushi1 = np.where(close-middle < 0, 0, 1)# 实时线在均线上、下方 qushi2 = np.where(middle[1:] - middle[:-1] < 0, 0, 1) # 均线上、下行(长度少了1) # 标签转化为0,1 y = np.where(series==-1, 0, 1) # 构造特征(注意,已经归一化,全部为非负数) f = upper-lower f = f[timeperiod:] # 去掉了前面timeperiod个nan数据!!! f = (f - f.min()) / (f.max() - f.min()) # 归一化 y = y[timeperiod:] qushi1 = qushi1[timeperiod:] qushi2 = qushi2[timeperiod-1:] features = np.column_stack([y, qushi1, qushi2, f]) # 特征:[标签、趋势1、趋势2、布林宽度] # data_len = len(series) time_steps = 3 # 将数据转化为[样本数, 时间步数, 特征数]的形式 X = [features[i:i+time_steps] for i in range(data_len-time_steps-timeperiod)] # [samples, time steps * features] X = np.reshape(X, (data_len - time_steps-timeperiod, time_steps, -1)) # [samples, time steps, features] # 标签长度一致 y = y[time_steps:] # one-hot编码 y = np.eye(2)[y] # 划分训练数据、测试数据 train_X, test_X = X[:-20], X[-20:] train_y, test_y = y[:-20], y[-20:] # ================================= model = Sequential() model.add(LSTM(64, input_shape=(X.shape[1], X.shape[2]))) model.add(Dense(y.shape[1], activation='softmax')) # 输出各类的概率(softmax) model.compile(loss='categorical_crossentropy', # 单标签,多分类(categorical_crossentropy) optimizer='adam', metrics=['accuracy']) model.fit(train_X, train_y, epochs=500, batch_size=1, verbose=2) #检查模型在测试集上的表现是否良好 test_loss, test_acc = model.evaluate(test_X, test_y) print('test_acc:', test_acc)
效果图
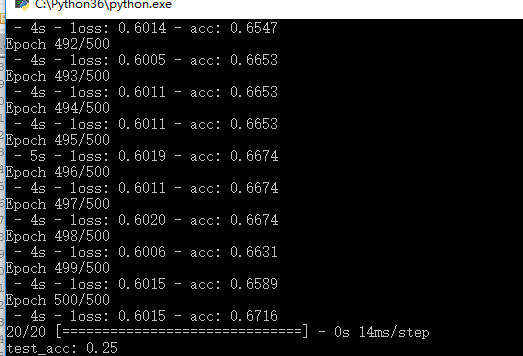

结论
只测试了mod 2的情况,效果不好.
训练数据精度可以达到三分之二左右,测试数据的精度只有四分之一。头脑风暴,几乎可以反其道而行之!可能不失为可行之策。
下一步:
1.画出后20个数据k线图,看是否是震荡区间,亦或是趋势区间
2.换别的指标看看