本文的文字及图片过滤网络,可以学习,交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于法纳斯特 ,作者法纳斯特

Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
1.概述
美团网的爬虫整体其实比较简单,通过开发者模式找到真实数据请求地址后,用requests请求的数据格式是标准的json字符串,非常好处理。

在本文我们将介绍两种常见的获取数据的方式,其一是通过搜索获取结果,其二是通过筛选获取结果。两种方式在获取真实数据请求地址的方法上稍有差异,具体我们见下面章节。
2.搜索结果数据采集
如果想在PC网页端搜索结果,需要先进行账号登录,然后方可进行搜索操作。
2.1. 获取真实数据请求地址
如下图,我们先在搜索框 输入 搜索关键字如“火锅”。然后进行以下步骤:(以谷歌浏览器为例)
- 按 F12 进入到开发者模式
- 在右侧开发者模式页面最上方点击Network—>XHR
- 在左侧搜索结果页拖到最下方,点击下一页(如 2)
- 然后在右侧的开发者模式页面左侧靠上的Name,点击第二个uuid开头的即可出现我们需要的信息
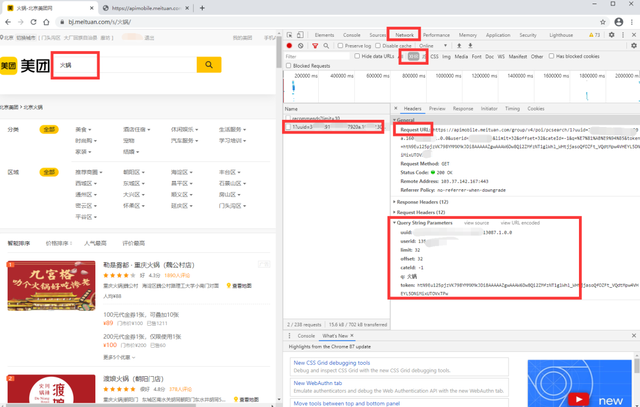
获取真实数据请求地址
我们可以发现Request URL即为真实数据请求地址,其基础部分长这样(北京)https://apimobile.meituan.com/group/v4/poi/pcsearch/1?...
最终链接地址还需要有以下参数:在 Query String Parameters 中可以看到哈
uuid: # 你的uuid,登录后在开发者模式获取
userid: # 你的userid,登录后在开发者模式获取
limit: 32 # 每页的 店铺信息数
offset: 32 # 当前 偏移量,第1页为0,第2页为 (2-1)*limit
cateId: -1 # 类型
q: 火锅 # 搜索的关键字
token: htN9Eu125pjzVK798YMMXMkJDi8AAAAAZgwAAAW6Dw8Qi2ZMfzNT1glWhl_WHtjjasoQfOZFt_VQdtMpw4VHEYL5DNiMixUTOVxTPw # token,经过测试发现可以不需要
如果你在其他筛选项进行选择时,会发现对应参数可能增加或减少,这个时候根据自己需求进行参数设定即可。
2.2. 请求数据(requests)
这里只需要用到两个库,requests请求数据,json解析json数据字符串。
import requests
import json
# 以北京为例,其基础链接如下:
base_url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/1?'
# 上海为如下,差异就在最后面问号前面的数字,上海为10,北京为1
# https://apimobile.meituan.com/group/v4/poi/pcsearch/10?
uuid = xxxx # 你的uuid,登录后在开发者模式获取
userid = xxx # 你的userid,登录后在开发者模式获取
key = '火锅'
# 这里演示请求第一页的数据
page = 1
# 设置请求参数
parameters = {
'uuid': uuid, # 你的uuid,登录后在开发者模式获取
'userid': userid, # 你的userid,登录后在开发者模式获取
'limit':32, # 每页的 店铺信息数
'offset':32*(page - 1), # 当前 偏移量,第1页为0,第2页为 (2-1)*limit
'cateId':-1, #
'q': key, # 搜索的关键字
}
# 设置请求头
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法请求网页数据
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我们需要的数据
text = re.text
# 由于是json格式的字符串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的数据在 js['data']中
data = js['data']
searchResult = data['searchResult'] # 结果列表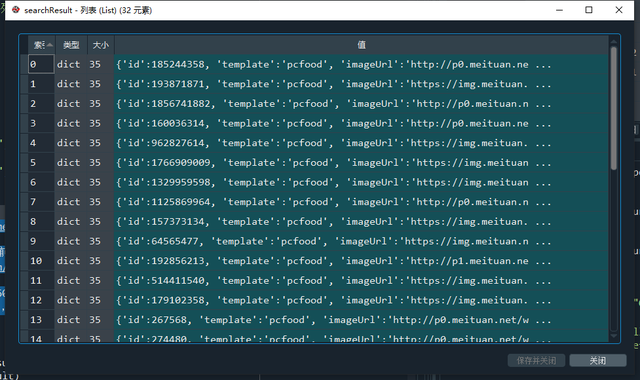
结果其实是很结构化的
2.3. 解析获取需要的数据
由于单页存在32组数据,且每组数据字段较多,我们用列表来存储单页数据,用字典存储单个店铺的信息。
考虑到我想记录每个店铺的优惠券销售量信息,又因为优惠券存储的是列表形式,这里我单独处理了优惠券的记录信息,组合其他基础信息后形成一条数据。因此在最终的数据中同一个店铺会存在多条,不过其优惠券信息是存在差异的。
# 接2.2.中结果
shops = []
for dic in searchResult:
shop = {}
shop['id'] = dic['id']
shop['店铺名称'] = dic['title']
shop['地址'] = dic['address']
shop['地区'] = dic['areaname']
shop['平均消费'] = dic['avgprice']
shop['评分'] = dic['avgscore']
shop['评价数'] = dic['comments']
shop['类型'] = dic['backCateName']
# shop['优惠'] = dic['deals']
shop['经度'] = dic['longitude']
shop['纬度'] = dic['latitude']
shop['最低消费'] = dic['lowestprice']
if dic['deals'] == None:
shops.append(shop)
else:
for deal in dic['deals']:
# deal = dic['deals'][1]
shop_info = shop.copy()
shop_info['优化id'] = deal['id']
shop_info['优惠券名称'] = deal['title']
shop_info['优惠券原价值'] = deal['value']
shop_info['优惠券价格'] = deal['price']
shop_info['优惠券销量'] = deal['sales']
shops.append(shop_info) 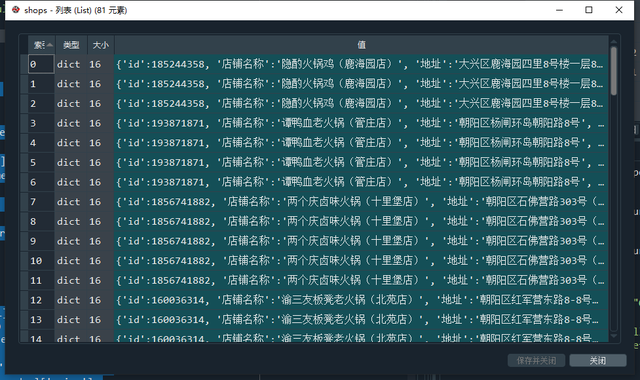
店铺数据列表
2.4. 存储结果到本地(csv文件)
我们每获取一页数据之后,立刻写入本地,因为每页的数据最后是由字典组成的列表,我们可以直接使用pandas的Dataframe.to_csv()方法来进行追加写入。
# 接 2.3. 中的结果
import pandas as pd
df = pd.DataFrame(shops)
# 需要存储表头,所以对于第一页的数据我们连表头一起存储
if page == 1:
df.to_csv('火锅店铺数据.csv',index=False, mode='a+', )
# 非第一页的数据,我们之存数据不存表头,mode='a+'是追加模式
else:
df.to_csv('火锅店铺数据.csv',header=False,index=False, mode='a+', )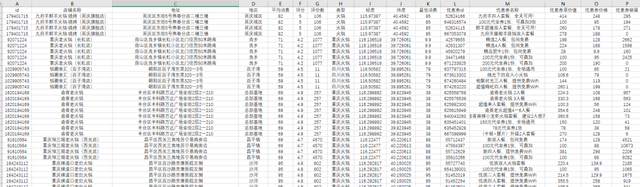
导出的数据表
3.分类筛选结果数据采集
在进行分类筛选的时候,我们不需要进行账号登录即可获取数据。不过通过分析发现这种情况下真实数据请求地址有别的搜索结果下的真实数据请求地址,且稍微麻烦一点,具体我们见后面的分析。
3.1. 获取真实数据请求地址
和2.搜索结果数据采集中的过程一样,进行以下步骤:(以谷歌浏览器为例)
- 按 F12 进入到开发者模式
- 在右侧开发者模式页面最上方点击Network—>XHR
- 刷新页面或者点击下一页(如2)
- 然后在右侧的开发者模式页面左侧靠上的Name,点击getPolist?即可获得我们需要的信息
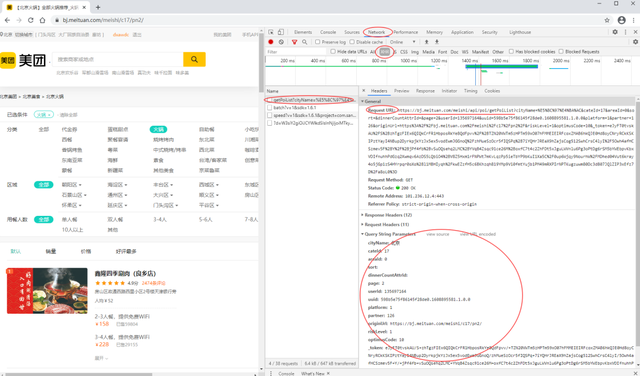
获取真实数据请求地址
我们可以发现Request URL即为真实数据请求地址,其基础部分长这样(北京)https://bj.meituan.com/meishi/api/poi/getPoiList?
最终链接地址还需要有以下参数:在 **Query String Parameters **中可以看到哈
cityName: 北京 # 城市
cateId: 17 # 分类
areaId: 0 # 区域
sort: # 排序类型
dinnerCountAttrId: # 就餐人数
page: 2
userId:
uuid:
platform: 1 # 平台
partner: 126
originUrl: https://bj.meituan.com/meishi/c17/pn2/
riskLevel: 1
optimusCode: 10
_token:
我们发现在上面参数中,随着翻页,page、originUrl会规律性变化,同时_token也会有所改变,而该值需要特殊处理获取,其他参数在你确定页面筛选项后都是固定的。
3.2. _token解析与生成
我刷新三次,获取三个token如下,我们试着介绍一下里面分别含有啥参数信息。
token = [
'eJx1T01vqkAU/S+zhTjDlzDusOLriLYqKkrTBTMgwyCKQBFt+t/fNGkXb/GSm5yPe3Jy7yeoSQJGGkIYIRV0aQ1GQBugwRCooG3kZogcjGyMho4lA+xfDxvSo/VuAkZvtm6p2MLv38Za6jcN60jVkIPe1V9uSq6bcr5TRIYAb9uqGUFIxaBM8/YjPg/YpYSSNzyHTLOhPOQ/ISBbyo1skVj8YPyD7a9eyIdkRZNnZ8nS2S0RTGtd4a34vuOm/wK3874mXbFih8uWbZtxJNDcw1SPRf8nyBSruhXXy9i+EC16tfFyo+DCyzo37dbR5vDKs7Xw+LHHT24HHWVvMHqf5Y9iYiPhw8VuscwpuVcnaswOxAj55slTomXY3aM01ruA6zBy58W09llw8pNhf95F3uGknSfXKrC9YxJTO5iEs+OY+c8hbaamYrrV3NKupAuzHRSY3hTRPjhqxXOkZ0bZOziaohey0OsyaZlFiL3flg9IDJTr4OsvJZyVbQ==',
'eJyFT8luo0AQ/Ze+GrkXzNKWcrABB/DYBLPYTJSDWYJpDGZYTMJo/j0dKTnkNFJJb6mnp6q/oLVSsMQIUYQEcM9asAR4juYyEEDf8Y2MVIoUKhKJYgEkPz1ZpgKI21AHy2eFSAKV6MunceD6GVOCBIxU9CJ88wXnZMHnM2XxELj0fdMtIYzZvMqKfjjX8+RWQc67SwETrMCmJpAf8/8g4KWVz0s5ll94/sL+W+/4f7ytK/Kas8we08nvnbVuuOu9psSO7tZvj5nq2TjXf2tu5Sajfh/IERNom+lhsBxp864Z4iobVskxiEkemqdx84rZSsPHabrkm9bw7hNUiiddUV/rCXqB1kQ+vpr3Yj2LZK+wTk3P4q2bGDd0HNKtiYI6W+yalLTUl8IgKhWm2PsgweJWLsPWuZVFdC1aNfe13R9GyhG9T1ulrn/tI+twTdteS+loElna3VimPs3EdGxyNpO6JH6MK5WkohedAqObzrPMwezGWHrwTLhYqSS0af7wAP59AGUUnIY=',
'eJyNT8tugkAU/ZfZQpwBxGFMuqhPQOUhYgpNFwgUUWAsDGBp+u+dJu2iuyY3OY97cnLvB6iNBEwlhAhCIujSGkyBNEKjCRABa/hmgjSCMFEnElFFEP/1ZCyJ4FQfF2D6jGVVJCp5+Tb2XD9LREaihDT0Iv7yMefymM93yuAhcGbs1kwhPF1GZZqzNqpGMS0h5805h7GE4a1SID/mP0EZAl5cHngxx+sPRj/IfvWO/8gbmzyrOEvNPhkOkv04LN1ZOsc38+I5fZUm4Symq72RG+OFbXfhfa0TCpdBfujcuC/sXq8yvTj7+L1NFcZUt9OCytiudj2m6/BkYE0T6GtHBGdQITXcGAWTIsRqFhbruV8XpU5xEczszXvmb4c1RHbUDtunxFNKIQ+8fauRfONfbSa3fq6qxeDGpnSEru4H7kUuK3J3/OHVijaLq7WyunqJ8dli/aYJnFRzBIXc89hO3oY+KZuEmUrIlFO2rKl3LLC1C99o4HtRF+tkXpjC48MD+PwC/5KgHA=='
]对于这三个token,加密算法比较简单,其采用的是二进制压缩与base64编码。
3.2.1. 解析
我们在解析token时的操作步骤是先进行base64解码再进行二进制解压,这里需要用到base64库和zlib库。
import base64
import zlib
for s in token:
temp = base64.b64decode(s)
result = zlib.decompress(temp)
print(result)b'{"rId":100900,"ver":"1.0.6","ts":1608907906850,"cts":1608907906930,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/","https://bj.meituan.com/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2"}'
b'{"rId":100900,"ver":"1.0.6","ts":1608907932591,"cts":1608907932669,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/pn2/","https://bj.meituan.com/meishi/c17/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdzTtOBDEQBNC7bODQnxGe8SJ1gDZCQmQcwDvu2W12/JHdRuIO5FyCE3AeuAcWUb2gVHXwFf1jAC1WzzhgFrESvz/7iPD78fnz/SUCpYT1lHviB+Y6SiIXptjbKQcEo0WudKH0Une4Mpd2r9T5VUYk7j7JNUc13K6kVrOokiYlir8gTCMqj2kw0yzK7nnLNYIRldrtCd9wH265Moje8P+3dwpgj+5scbGbm82d3SYXUEsza+eO1jojjdRSH/4A82VJ9g=="}'
b'{"rId":100900,"ver":"1.0.6","ts":1608907956195,"cts":1608907956271,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/pn3/","https://bj.meituan.com/meishi/c17/pn2/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdzT1OAzEQBeC7pJjSPwnedZBcoFRIiI4DOOvZxGH9o/EYiTvQcwlOwHngHlhU7yue3tt5Qv8YnILFMw7oGZbI788+ofv9+Pz5/oIQc0Y6lZ75gZlGCUrlmHo7lYBOKygULzG/0OauzLXdS3m+iYSRu89iKUkOt2uUi55lzQcJ1V/QHUYQj2mn9xPUzfNaKDkNFNvrE77hNtwKsYPe8P+39xicOdqzwdmsdtJ3Zt3bgEroSVl7NMZqoYUSavcH9ClJ+A=="}'根据三个token解析结果,我们发现其带有的参数较多,但是变化的只有部分,其中ts、cts是时间戳,以第一个为例:
ts = 1608907906850

ts
cts = 1608907906930

cts
由于2个都是毫秒级的时间戳,其实都是同一个时间点,相差90毫秒左右,因此我们可以在进行请求的时候获取当前时间然后即可获取ts和cts参数值。
另外有变化的就是BI,其是当前网页和前序网页的原始地址,亦可有规律生成。
最后,我们发现sign也是变化的,而且和token很像,我们用同样的解析方式可以发现其规律:
s = 'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'
temp = base64.b64decode(s)
result = zlib.decompress(temp)
print(result)b'"areaId=0&cateId=17&cityName=xe5x8cx97xe4xbaxac&dinnerCountAttrId=&optimusCode=10&originUrl=https://bj.meituan.com/meishi/c17/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'很巧,我们发现其实他就是一些参数组合,其中有变化的就是originUrl和page参数,和当前访问页关联。
3.2.2. 生成
我们知道token解析过程之后,逆向过程即可生成token。我们选取一个解析后的token格式化,然后构建生成方式。
# 解析后的token格式化
{'rId': 100900,
'ver': '1.0.6',
'ts': 1608907906850,
'cts': 1608907906930,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': ['https://bj.meituan.com/meishi/c17/', 'https://bj.meituan.com/'],
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign': 'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'}对于sign,我们也看下其解析后的结果:
b'"areaId=0&cateId=17&cityName=xe5x8cx97xe4xbaxac&dinnerCountAttrId=&optimusCode=10&originUrl=https://bj.meituan.com/meishi/c17/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'因此,我们在构造token之前先构造sign:
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'在选定城市后,sign可变参数为originUrl和page。
再生成sign:
# 构造sign
Url = 'https://bj.meituan.com/meishi/c17/'
page = 1
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二进制编码
encode = s_sign.encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
sign = str(b_encode, encoding='utf-8')
得到可以用于构造token的sign如下:
'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'再构造token:
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二进制编码
encode = str(dic_token).encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
token = str(b_encode, encoding='utf-8')得到token如下:
'eJx1j01zqjAARf+KOxZ0TMKHMd1hxTairRUVpdMFBASCKAKNaKf//ZEufDNv5i0yc+7JnTvJt1LRSHnsIQgJhA89RcRVFxXUh/2B0uWmlrcDOCRdAcOBiTrJ/rHYkDasNuNOf2DNfOgRk3z+uqVUH4ho3TqCQ9jZezJk0gx5fstUdpW0acr6EYCQ94s4a76CY5+dCtBxnWaAIQzkw/7TUuRQsZJDkvI7BXdq/rq5/Ktcq7PkKDmeXiLOUGNx+z3ditRwXsF61lZU5O9sd1qzdT3yOZzZJNQC3j67iWqWl/x8GuETRf4bJouVSnI7EVYslv5q95YmS26n+5Y8WQIM1a3Owus0u+VjDLkD5pv5IgvptTyE+nRHdS9dPdmqv/DE1Y8DTbipBnxrlk8qh7kHJxq0x41v7w7oOD6XLrb3URBid+xN9yPmvHhhPTFUwypnJjpT4SUbwEl4UXlzS2HDX3wt0Yt2SPwJfKVzrSqihpmU4u26uAGqw0xTfv4AOoWaFA=='3.3. 请求数据(requests)
和搜索结果数据采集一样,用requests请求数据,json解析json数据字符串。
import requests
import json
import base64
import zlib
# 以北京为例,其基础链接如下:
base_url = 'https://bj.meituan.com/meishi/api/poi/getPoiList?'
uuid = '598b5e75f86145f28de0.1608895581.1.0.0' # 你的userid,登录后在开发者模式获取
# 这里演示请求第一页的数据
page = 1
# 构造sign
Url = 'https://bj.meituan.com/meishi/c17/'
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二进制编码
encode = s_sign.encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
sign = str(b_encode, encoding='utf-8')
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二进制编码
encode = str(dic_token).encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
token = str(b_encode, encoding='utf-8')
# 设置请求参数
parameters = {
'cityName': '北京' ,# 城市
'cateId': 17 ,# 分类
'areaId': 0 , # 区域
'sort': '',# 排序类型
'dinnerCountAttrId': '' ,# 就餐人数
'page': page,
'userId': '',
'uuid': uuid,
'platform': 1 ,# 平台
'partner': 126,
'originUrl': Url,
'riskLevel': 1,
'optimusCode': 10,
'_token': token,
}
# 设置请求头
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法请求网页数据
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我们需要的数据
text = re.text
# 由于是json格式的字符串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的数据在 js['data']中
data = js['data']
poiInfos = data['poiInfos'] # 结果列表
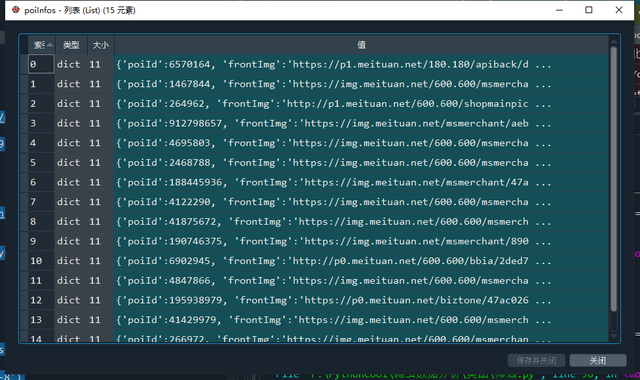
结果列表
3.4. 解析获取需要的结果
到这一步及之后的数据存储过程和 2.搜索结果数据采集的步骤大同小异,大家可以自行处理了。不过我们发现通过这种方式获取的店铺信息好像更少些,哈哈哈!
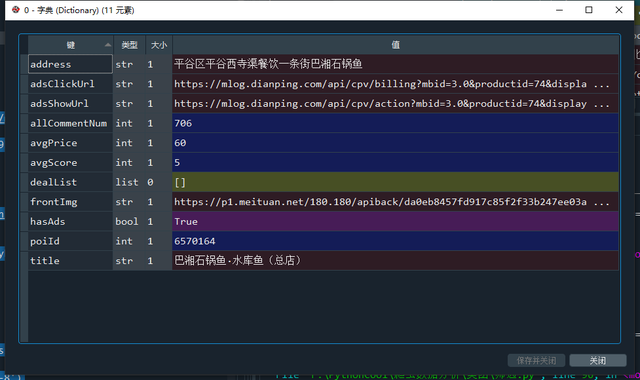
单店铺信息
3.5. 存储结果到本地
同2.4.存储结果到本地(csv文件)
4.总结
对于美团的这两种数据采集方式,我们在进行处理的时候难易度不一样。其中搜索结果数据采集相对简单,在获取到真实数据请求地址后,编写循环脚本就能完成批量爬取;但是对于第二种分类筛选结果数据采集来说,由于其token是时刻在变化的,我们需要进行一定的生成处理后才能爬取到数据,其过程稍微复杂了些。
'cts': ts+90, 'brVD': [725, 959], 'brR': [[1920, 1080], [1920, 1040], 24, 24], 'bI': bI, 'mT': [], 'kT': [], 'aT': [], 'tT': [], 'aM': '', 'sign':sign } # 二进制编码 encode = str(dic_token).encode() # 二进制压缩 compress = zlib.compress(encode) # base64编码 b_encode = base64.b64encode(compress) # 转为字符串 token = str(b_encode, encoding='utf-8')得到token如下:
'eJx1j01zqjAARf+KOxZ0TMKHMd1hxTairRUVpdMFBASCKAKNaKf//ZEufDNv5i0yc+7JnTvJt1LRSHnsIQgJhA89RcRVFxXUh/2B0uWmlrcDOCRdAcOBiTrJ/rHYkDasNuNOf2DNfOgRk3z+uqVUH4ho3TqCQ9jZezJk0gx5fstUdpW0acr6EYCQ94s4a76CY5+dCtBxnWaAIQzkw/7TUuRQsZJDkvI7BXdq/rq5/Ktcq7PkKDmeXiLOUGNx+z3ditRwXsF61lZU5O9sd1qzdT3yOZzZJNQC3j67iWqWl/x8GuETRf4bJouVSnI7EVYslv5q95YmS26n+5Y8WQIM1a3Owus0u+VjDLkD5pv5IgvptTyE+nRHdS9dPdmqv/DE1Y8DTbipBnxrlk8qh7kHJxq0x41v7w7oOD6XLrb3URBid+xN9yPmvHhhPTFUwypnJjpT4SUbwEl4UXlzS2HDX3wt0Yt2SPwJfKVzrSqihpmU4u26uAGqw0xTfv4AOoWaFA=='3.3. 请求数据(requests)
和搜索结果数据采集一样,用requests请求数据,json解析json数据字符串。
import requests
import json
import base64
import zlib
# 以北京为例,其基础链接如下:
base_url = 'https://bj.meituan.com/meishi/api/poi/getPoiList?'
uuid = '598b5e75f86145f28de0.1608895581.1.0.0' # 你的userid,登录后在开发者模式获取
# 这里演示请求第一页的数据
page = 1
# 构造sign
Url = 'https://bj.meituan.com/meishi/c17/'
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二进制编码
encode = s_sign.encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
sign = str(b_encode, encoding='utf-8')
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二进制编码
encode = str(dic_token).encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
token = str(b_encode, encoding='utf-8')
# 设置请求参数
parameters = {
'cityName': '北京' ,# 城市
'cateId': 17 ,# 分类
'areaId': 0 , # 区域
'sort': '',# 排序类型
'dinnerCountAttrId': '' ,# 就餐人数
'page': page,
'userId': '',
'uuid': uuid,
'platform': 1 ,# 平台
'partner': 126,
'originUrl': Url,
'riskLevel': 1,
'optimusCode': 10,
'_token': token,
}
# 设置请求头
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法请求网页数据
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我们需要的数据
text = re.text
# 由于是json格式的字符串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的数据在 js['data']中
data = js['data']
poiInfos = data['poiInfos'] # 结果列表
结果列表
3.4. 解析获取需要的结果
到这一步及之后的数据存储过程和 2.搜索结果数据采集的步骤大同小异,大家可以自行处理了。不过我们发现通过这种方式获取的店铺信息好像更少些,哈哈哈!
单店铺信息
3.5. 存储结果到本地
同2.4.存储结果到本地(csv文件)
4.总结
对于美团的这两种数据采集方式,我们在进行处理的时候难易度不一样。其中搜索结果数据采集相对简单,在获取到真实数据请求地址后,编写循环脚本就能完成批量爬取;但是对于第二种分类筛选结果数据采集来说,由于其token是时刻在变化的,我们需要进行一定的生成处理后才能爬取到数据,其过程稍微复杂了些。