[NOI2015]品酒大会
题目描述
一年一度的“幻影阁夏日品酒大会”隆重开幕了。大会包含品尝和趣味挑战 两个环节,分别向优胜者颁发“首席品酒家”和“首席猎手”两个奖项,吸引了众多品酒师参加。
在大会的晚餐上,调酒师 Rainbow 调制了 n 杯鸡尾酒。这 n 杯鸡尾酒排成一行,其中第 n 杯酒 (1 ≤ i ≤ n) 被贴上了一个标签si,每个标签都是 26 个小写 英文字母之一。设 str(l, r)表示第 l 杯酒到第 r 杯酒的 r − l + 1 个标签顺次连接构成的字符串。若 str(p, po) = str(q, qo),其中 1 ≤ p ≤ po ≤ n, 1 ≤ q ≤ qo ≤ n, p ≠ q, po − p + 1 = qo − q + 1 = r ,则称第 p 杯酒与第 q 杯酒是“ r 相似” 的。当然两杯“ r 相似”(r > 1)的酒同时也是“ 1 相似”、“ 2 相似”、……、“ (r − 1) 相似”的。特别地,对于任意的 1 ≤ p , q ≤ n , p ≠ q ,第 p 杯酒和第 q 杯酒都 是“ 0 相似”的。
在品尝环节上,品酒师 Freda 轻松地评定了每一杯酒的美味度,凭借其专业的水准和经验成功夺取了“首席品酒家”的称号,其中第 i 杯酒 (1 ≤ i ≤ n) 的 美味度为 ai 。现在 Rainbow 公布了挑战环节的问题:本次大会调制的鸡尾酒有一个特点,如果把第 p 杯酒与第 q 杯酒调兑在一起,将得到一杯美味度为 ap*aq 的 酒。现在请各位品酒师分别对于 r = 0,1,2, ⋯ , n − 1 ,统计出有多少种方法可以 选出 2 杯“ r 相似”的酒,并回答选择 2 杯“ r 相似”的酒调兑可以得到的美味度的最大值。
输入输出格式
输入格式:
第 1 行包含 1 个正整数 n ,表示鸡尾酒的杯数。
第 2 行包含一个长度为 n 的字符串 S,其中第 i 个字符表示第 i 杯酒的标签。
第 3 行包含 n 个整数,相邻整数之间用单个空格隔开,其中第 i 个整数表示第 i 杯酒的美味度 ai 。
输出格式:
包括 n 行。第 i 行输出 2 个整数,中间用单个空格隔开。第 1 个整 数表示选出两杯“ (i − 1) 相似”的酒的方案数,第 2 个整数表示选出两杯 “ (i − 1) 相似”的酒调兑可以得到的最大美味度。若不存在两杯“ (i − 1) 相似” 的酒,这两个数均为 0 。
输入输出样例
输入样例#1: 复制
10
ponoiiipoi
2 1 4 7 4 8 3 6 4 7
输出样例#1: 复制
45 56
10 56
3 32
0 0
0 0
0 0
0 0
0 0
0 0
0 0
输入样例#2: 复制
12
abaabaabaaba
1 -2 3 -4 5 -6 7 -8 9 -10 11 -12
输出样例#2: 复制
66 120
34 120
15 55
12 40
9 27
7 16
5 7
3 -4
2 -4
1 -4
0 0
0 0
说明
【样例说明 1】
用二元组 (p, q) 表示第 p 杯酒与第 q 杯酒。
0 相似:所有 45 对二元组都是 0 相似的,美味度最大的是 8 × 7 = 56 。
1 相似: (1,8) (2,4) (2,9) (4,9) (5,6) (5,7) (5,10) (6,7) (6,10) (7,10) ,最大的 8 × 7 = 56 。
2 相似: (1,8) (4,9) (5,6) ,最大的 4 × 8 = 32 。
没有 3,4,5, ⋯ ,9 相似的两杯酒,故均输出 0 。
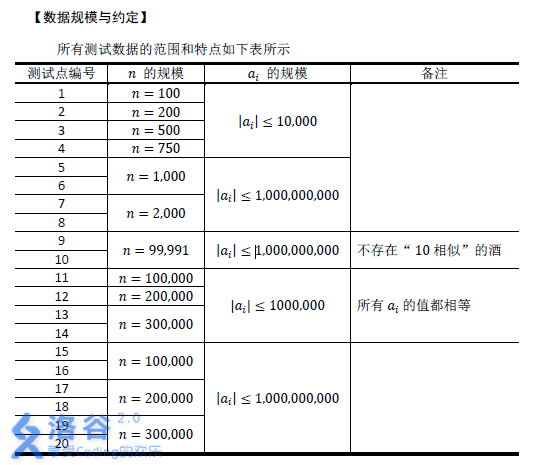
【时限1s,内存512M】
题解
不得不说我觉得noi两道经典的后缀例题里面,
这一道要比优秀的拆分要友善的多。
对于这一道题,我们要维护的是相同的子串。
这个跑一遍后缀数组求出(lcp)就好维护了
我之前的思路是,每一次(H[i]==0)时就维护一下当前的p和q,(O(n^2))的复杂度维护一下当前这一堆酒的贡献。
没想到正解就是多加了一个并查集+贪心维护了一下,转成了O(n)。
也不是贪心吧,就是H[]值大的数的贡献更大,即1到H[]都能得到贡献,那么我们只需要把H[]从大到小排就好了
从小到大的话,小的先进并查集里会影响大的size的大小。
细节:负数相乘可能会比正数相称更大,所以我们这两个值都要维护
代码
#include<cstdio>
#include<cmath>
#include<cstring>
#include<iostream>
#include<algorithm>
#define ll long long
using namespace std;
const int N=300001;
int H[N],num[N],rak[N],sa[N],tp[N];
ll ch[N],n,m,id[N];
ll size[N],mx[N],mi[N],f[N],mul[N];
ll ans1[N],ans[N],ans2[N];
char s[N];
ll read(){
ll x=0,w=1;char ch=getchar();
while(ch>'9'||ch<'0'){if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9')x=x*10+ch-'0',ch=getchar();
return x*w;
}
void Sort(){
for(int i=0;i<=m;i++)num[i]=0;
for(int i=1;i<=n;i++)num[rak[i]]++;
for(int i=1;i<=m;i++)num[i]+=num[i-1];
for(int i=n;i>=1;i--)sa[num[rak[tp[i]]]--]=tp[i];
}
void SA_sort(){
m=10001;
for(int i=1;i<=n;i++)tp[i]=i,rak[i]=s[i]-'a'+1;Sort();
int w=1,p=0,cnt=0;
while(p<n){
for(int i=1;i<=w;i++)tp[++cnt]=n-w+i;
for(int i=1;i<=n;i++)if(sa[i]>w)tp[++cnt]=sa[i]-w;
Sort();swap(rak,tp);rak[sa[1]]=p=1;
for(int i=2;i<=n;i++)
if(tp[sa[i]]==tp[sa[i-1]]&&tp[sa[i]+w]==tp[sa[i-1]+w])
rak[sa[i]]=p;else rak[sa[i]]=++p;
w<<=1;m=p;cnt=0;
}
for(int i=1;i<=n;i++)rak[sa[i]]=i;
int k=0;
for(int i=1;i<=n;i++){
if(k)k--;
while(s[i+k]==s[sa[rak[i]-1]+k])k++;
H[rak[i]]=k;
}
}
bool cmp(int x,int y){
return H[x]>H[y];
}
int find(int x){
return f[x]==x?x:f[x]=find(f[x]);
}
void work(){
n=strlen(s+1);
for(int i=1;i<=n;i++)
ch[i]=read();
for(int i=1;i<=n;i++){
id[i]=f[i]=i;mi[i]=mx[i]=ch[i];
size[i]=1;ans2[i]=ans[i]=-1e18;
}
sort(id+1,id+n+1,cmp);
for(int i=1;i<=n;i++){
int x=sa[id[i]],y=sa[id[i]-1];
x=find(x),y=find(y);
f[y]=x;ans1[H[id[i]]]+=1ll*size[x]*size[y];
size[x]+=size[y];ans[x]=max(ans[x],ans[y]);
ans[x]=max(ans[x],1ll*mx[x]*mx[y]);ans[x]=max(ans[x],1ll*mx[x]*mi[y]);
ans[x]=max(ans[x],1ll*mi[x]*mx[y]);ans[x]=max(ans[x],1ll*mi[x]*mi[y]);
ans2[H[id[i]]]=max(ans2[H[id[i]]],ans[x]);
mx[x]=max(mx[x],mx[y]);mi[x]=min(mi[x],mi[y]);
}
for(int i=n-1;i>=0;i--)ans1[i]+=ans1[i+1],ans2[i]=max(ans2[i],ans2[i+1]);
for(int i=0;i<n;i++)
printf("%lld %lld
",ans1[i],ans1[i]==0?0:ans2[i]);
}
int main(){
n=read();
scanf("%s",s+1);
SA_sort();
work();
return 0;
}