打开mr管理页面
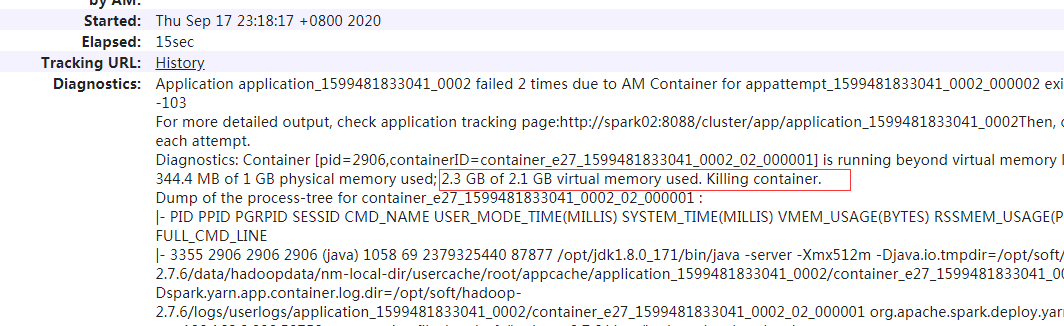
重点在红框处,2.3g的虚拟内存实际值,超过了2.1g的上限。也就是说虚拟内存超限,所以contrainer被干掉了,活都是在容器干的,容器被干掉了
解决方案
yarn-site.xml 增加配置:
2个配置2选一即可
<!--以下为解决spark-shell 以yarn client模式运行报错问题而增加的配置,估计spark-summit也会有这个问题。2个配置只用配置一个即可解决问题,当然都配置也没问题-->
<!--虚拟内存设置是否生效,若实际虚拟内存大于设置值 ,spark 以client模式运行可能会报错,"Yarn application has already ended! It might have been killed or unable to l"-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<!--配置虚拟内存/物理内存的值,默认为2.1,物理内存默认应该是1g,所以虚拟内存是2.1g-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
重新启动hadoop、spark集群
有可能有新的问题
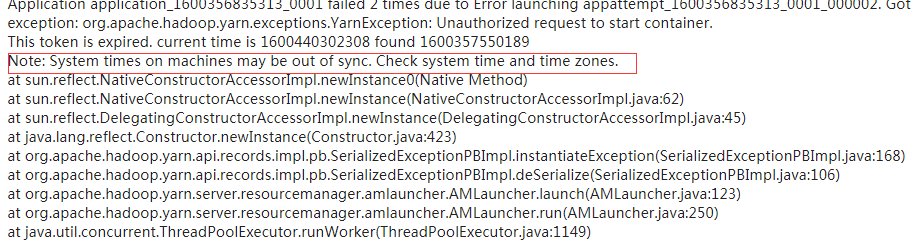
时间不同步
解决方案:
第一步:安装 ntpdate
sudo yum -y install ntp ntpdate
第二步:设置系统时间与网络时间同步
ntpdate cn.pool.ntp.org