https://my.oschina.net/feichexia/blog/196575#comment-list
A、 jps(Java Virtual Machine Process Status Tool)
jps主要用来输出JVM中运行的进程状态信息。语法格式如下:

如果不指定hostid就默认为当前主机或服务器。
命令行参数选项说明如下:

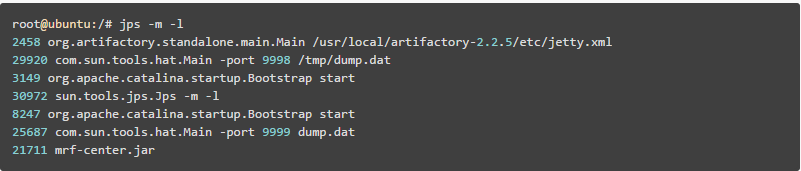
比如下面:
B、 jstack
jstack主要用来查看某个Java进程内的线程堆栈信息。语法格式如下:

命令行参数选项说明如下:

jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。下面我们来一个实例找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
第一步先找出Java进程ID,我部署在服务器上的Java应用名称为mrf-center:

得到进程ID为21711,第二步找出该进程内最耗费CPU的线程,可以使用ps -Lfp pid或者ps -mp pid -o THREAD, tid, time或者top -Hp pid,我这里用第三个,输出如下:
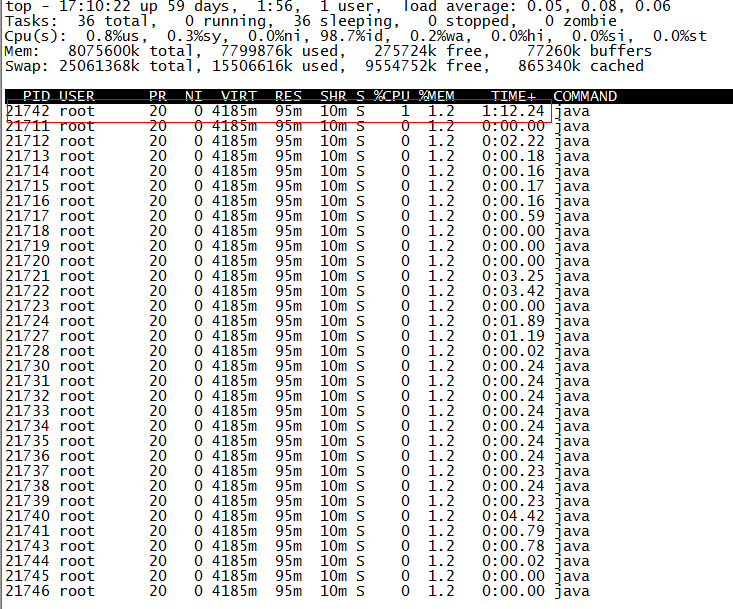
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为21742的线程,用

得到21742的十六进制值为54ee,下面会用到。
OK,下一步终于轮到jstack上场了,它用来输出进程21711的堆栈信息,然后根据线程ID的十六进制值grep,如下:

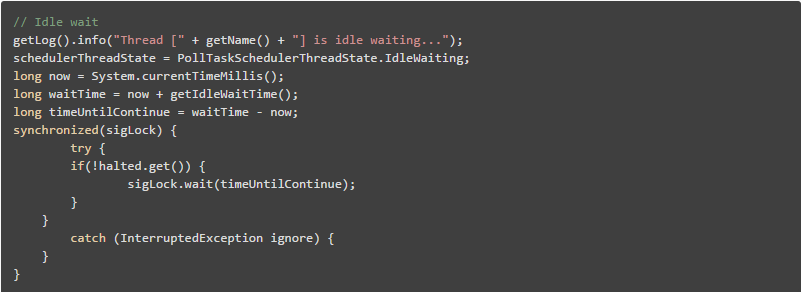
它是轮询任务的空闲等待代码,上面的sigLock.wait(timeUntilContinue)就对应了前面的Object.wait()。
C、 jmap(Memory Map)和jhat(Java Heap Analysis Tool)
jmap用来查看堆内存使用状况,一般结合jhat使用。
jmap语法格式如下:

如果运行在64位JVM上,可能需要指定-J-d64命令选项参数。

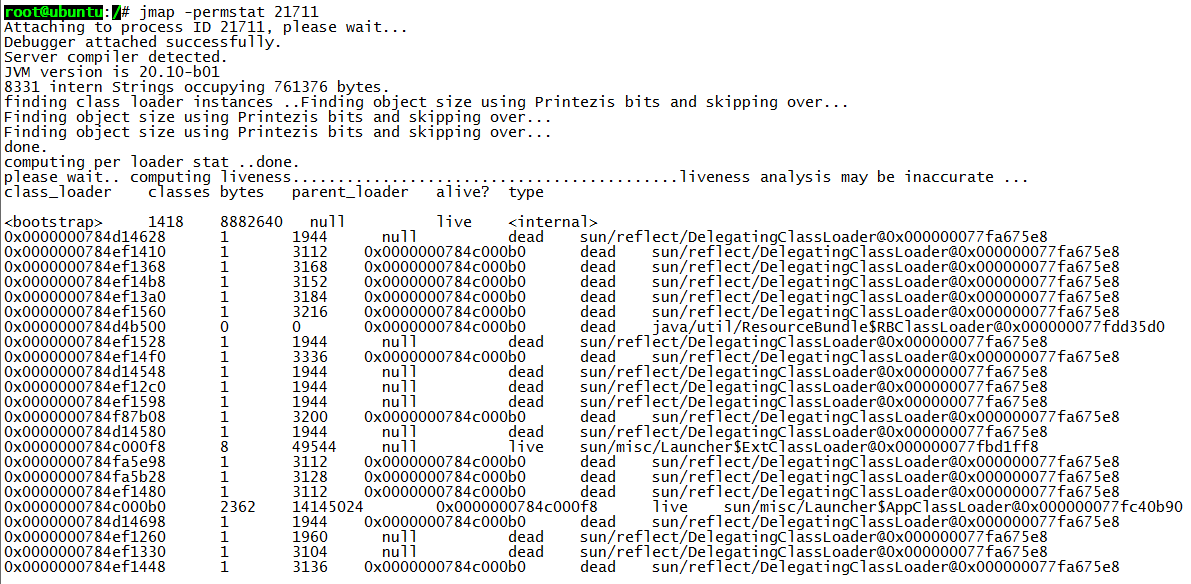
打印进程的类加载器和类加载器加载的持久代对象信息,输出:类加载器名称、对象是否存活(不可靠)、对象地址、父类加载器、已加载的类大小等信息,如下图:
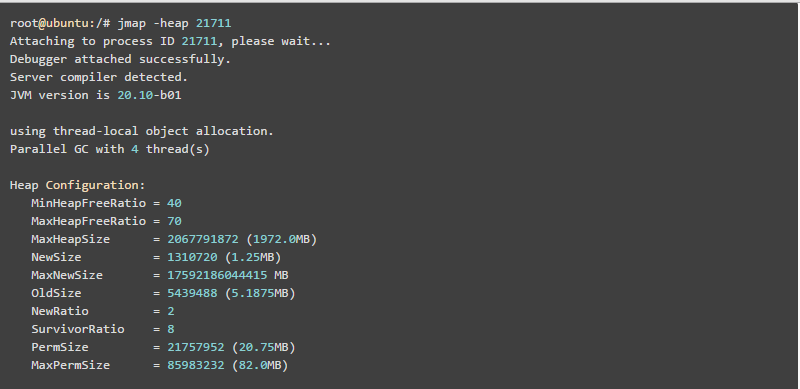
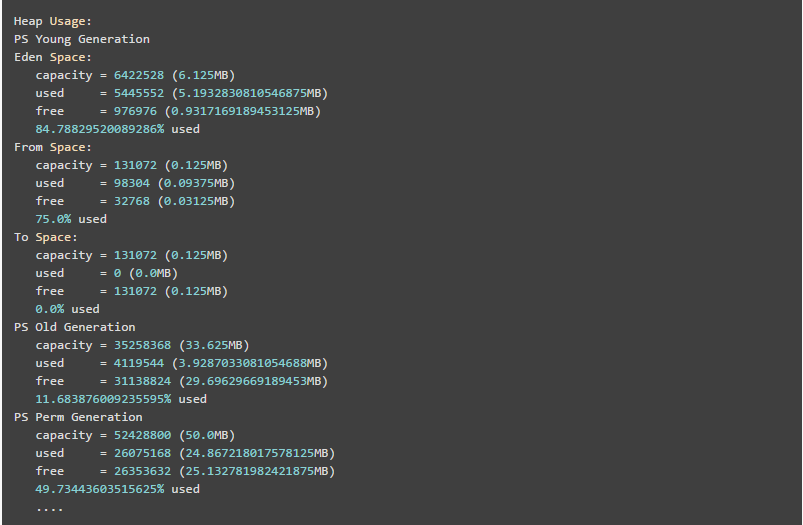
使用jmap -heap pid查看进程堆内存使用情况,包括使用的GC算法、堆配置参数和各代中堆内存使用情况。比如下面的例子:
使用jmap -histo[:live] pid查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象,如下:
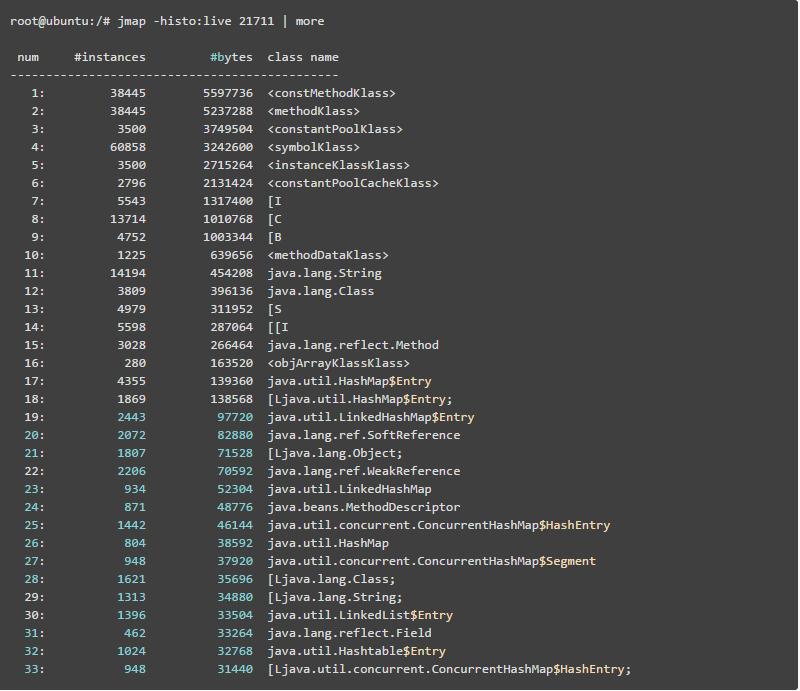 class name是对象类型,说明如下:
class name是对象类型,说明如下:

还有一个很常用的情况是:用jmap把进程内存使用情况dump到文件中,再用jhat分析查看。jmap进行dump命令格式如下:

我一样地对上面进程ID为21711进行Dump:

dump出来的文件可以用MAT、VisualVM等工具查看,这里用jhat查看:
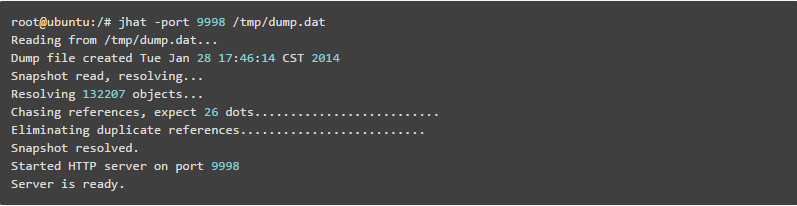
注意如果Dump文件太大,可能需要加上-J-Xmx512m这种参数指定最大堆内存,即jhat -J-Xmx512m -port 9998 /tmp/dump.dat。然后就可以在浏览器中输入主机地址:9998查看了:
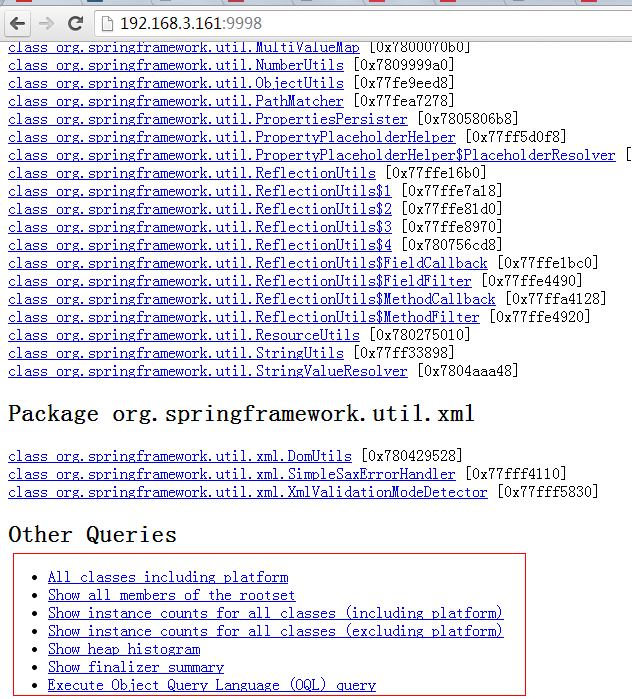
上面红线框出来的部分大家可以自己去摸索下,最后一项支持OQL(对象查询语言)。
D、jstat(JVM统计监测工具)
语法格式如下:

vmid是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。比如下面输出的是GC信息,采样时间间隔为250ms,采样数为4:

要明白上面各列的意义,先看JVM堆内存布局:
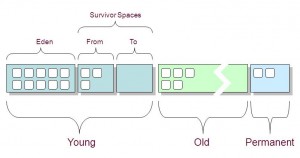
可以看出:

现在来解释各列含义:

E、hprof(Heap/CPU Profiling Tool)
hprof能够展现CPU使用率,统计堆内存使用情况。
语法格式如下:

完整的命令选项如下:
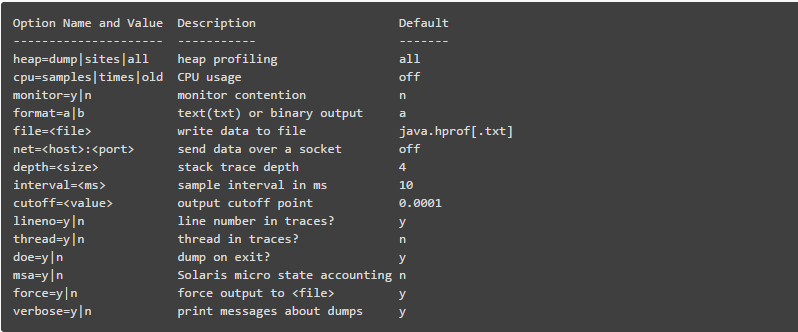
来几个官方指南上的实例。
CPU Usage Sampling Profiling(cpu=samples)的例子:

上面每隔20毫秒采样CPU消耗信息,堆栈深度为3,生成的profile文件名称是java.hprof.txt,在当前目录。
CPU Usage Times Profiling(cpu=times)的例子,它相对于CPU Usage Sampling Profile能够获得更加细粒度的CPU消耗信息,能够细到每个方法调用的开始和结束,它的实现使用了字节码注入技术(BCI):

Heap Allocation Profiling(heap=sites)的例子:

Heap Dump(heap=dump)的例子,它比上面的Heap Allocation Profiling能生成更详细的Heap Dump信息:

虽然在JVM启动参数中加入-Xrunprof:heap=sites参数可以生成CPU/Heap Profile文件,但对JVM性能影响非常大,不建议在线上服务器环境使用。