当我们得到数据模型后,该如何评价模型的优劣呢?之前看到过这样一句话 :“尽管这些模型都是错误的,但是有的模型是有用的”,想想这句话也是挺有道理的!评价和比较分类模型时,关注的是其泛化能力,因此不能仅关注模型在某个验证集上的表现。事实上,如果有足够多的样本作为验证集来测试模型的表现是再好不过的,但即使是这样也存在一个难点,比如难界定多大的样本才能足够表现出模型的泛化能力。因此,一般的做法是借助统计学的方法,评估模型在某个验证集分类表现的显著性。
评价及比较分类模型的过程,涉及到三个问题,一个是如何获取验证集,另一个是用什么度量指标表示分类表现,最后一个则是如何评估分类表现的显著性。
1. 验证集获取
数据样本的数量总是有限的,这就导致在选择训练集和验证集时出现了诸多方法,常用的方法有留出法、交叉验证法、bootstrap方法,下面分别介绍。
1.1 留出法
留出法一般用在样本数据量较大的情况。在使用留出法时,将样本数据分为两部分,一部分为训练集
,另一部分为验证集
,训练集
用来生成模型,验证集
用来评估其测试误差,将其作为对泛化误差的估计,这个思路比较简单,但是数据集
的划分过程需要注意两点:
与
的划分比例、
与
中样本的抽样方式。
与
的划分比例偏大时,由于
中数据样本量及包含的样本信息较少(糟糕的情况是其中还包含了较多噪声,这或许直接导致非常离谱的评估结果),因此其评估结果可能不够准确。即使
中包含了比较准确的样本信息,在换一个同等数量新的验证集时,可能包含的信息就不那么准确,评估结果也可能会有较大差别,故其评估结果不稳定;
与
的划分比例偏小时,由于训练数据包含较少的样本信息,这样得到的模型本身就不可取,这种情况比“
与
的划分比例偏大”更糟糕,之后用
得到的评估结果,已经是失真的了。那该如何选取训练集
与验证集
的划分比例呢?一般选用样本数据集
的2/3~4/5用来训练模型,剩余数据用来测试,验证集
应至少包含30个样本。
选择合适的划分比例后,还有(在
个样本中选取
个)的问题,因为此时样本选择仍有多种情况,单次使用留出法得到的评估结果往往不够可靠,一般采用多次随机划分、取评估结果的平均值的方式得到最终的评估结果。
1.2 交叉验证法
交叉验证法中,将样本数据集均分为
等份(注意,这个均分过程仍然要考虑1.1节中提到的信息均匀问题),前
份作为训练集,剩余一份作为测试集,得到测试结果。由于测试集的选择方式有
种,因此在数据集
的一次划分过程中可以得到
个测试结果,将这
个测试结果的平均值返回作为最终结果,这个过程通常称为“
折交叉验证”。当
=10时,交叉验证的过程示意图如下
![]()
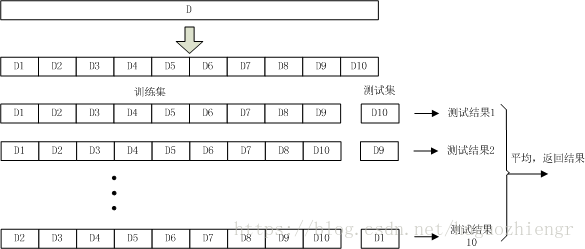
在交叉验证过程中,在确定样本数据集划分份数
时需要考虑1.1节中提到的训练集与测试集比例问题,除此之外,从数据集
中抽样得到每份数据时同样存在
问题,因此一般也会进行多次随机抽样(抽样次数为
),这样在使用交叉验证法时一共会进行
次测试,最终的评估结果是这
次
折交叉验证的结果的平均。
分析交叉验证法和留出法的过程来看,本质上是一样的。折交叉验证的过程可以视作
次留出法的过程,不过要求在这
次留出时,留出的数据间不能有重和,并且
次留出的数据并起来就是样本数据集
。
1.3 bootstrap方法
留出法和交叉验证法都在数据样本中单独划分出了验证集,这样在模型训练时并没有使用全部的样本数据,这在样本数据量充足时并不会产生多大问题,但是在样本数据量较小时可能会导致模型包含信息不充分,产生估计偏差,在这种情况下,bootstrap方法可能是一个比较好的选择。
在实施bootstrap方法时,为了得到训练集(包含
个样本),每次从样本数据集
中随机抽样一个样本放入训练集
中,然后将该抽取的样本放回
中重新进行抽样,重复该过程
次后就得到训练集
,然后将数据集
中除去训练集
后剩下的数据作为验证集,得到测试结果。重复进行多次这样的过程,将所有结果的平均值作为最终结果。
很明显,在bootstrap方法中抽样得到训练集的过程十分关键,抽样过程改变了训练集
及验证集
的分布,这很有可能带来估计偏差,因此在样本数据量充足时,还是选取前两种方法比较合适。
以上三种获取训练集、验证集的方法,都涉及到样本抽样的问题,抽样过程中也是有许多问题需要注意的,这里我不再多说明,可以参考我转载的博文《统计学中抽样调查和一些常用的方法》中的方法进行抽样。
2. 度量指标选择
在不同的任务中,应该选择合适的性能指标来衡量模型的优劣。在预测任务中,给定样本集,
是
的真实标记,评估模型
的性能就是要比较
的预测结果与真实标记
之间的差异。
2.1 错误率与精度
错误率及精度是分类任务中最常用的性能指标,适合于二分类及多分类任务,其定义也比较简单,错误率指错误分类的样本数占总样本数的比例,精度则为1-
。
2.2 查准率、查全率
在一些场合下,错误率及精度不足以衡量模型的性能,我们还关心查准率和查全率。比如在建立疾病预测模型时,需要依据人的体温、呼吸等条件预测其是否患有某种疾病,那么我们可能更关心这个模型的查准率,将真正患有疾病的人都预测出来,而不是简单的知道精度是多少,因为这存在健康被诊为患病、患病诊为健康的情况。对于二分类问题,先简单定义一下查准率与查全率
查准率:在所有被标为“正例”的样本中,真正为“正例”的样本比例
查全率:在所有真正为“正例”的样本,被标记为“正例”的样本比例
建立分类结果的混淆矩阵
![]()

查准率与查全率
的计算公式为
然而查准率和查全率是一对矛盾的度量,对于很多模型来说二者很难同时达到完美,在对比模型的时候会出现一方查准率高而另一方查全率高的情况,此时该如何抉择呢?在实际应用中一般使用度量指标,它是基于查准率
与查全率
计算出来的,其定义如下
(1)
为样例总数
在一些分类任务中,对查准率与查全率的侧重会有所不同。在商品推荐领域中,会侧重查准率以减少不准确信息对用户的干扰,而在逃犯信息检索领域,会侧重查全率一些,避免有漏网之鱼,为此有了的改进形式——
,其定义形式为
(2)
(3)
从公式(2)容易看出,当时,查全率R的变换对
的影响较大,此时更侧重查全率;当
时,查全率R的变换对
的影响较小,查准率影响相对较大,此时更侧重查准率;当
时,也就没有权重,变成了
的形式。正如第1节中提到的,实际测试过程一般会有多次,此时可以计算多次测试的查准率、查全率结果,然后取其平均值代入公式(1)和公式(3)中计算。
在多分类任务中,假设分类数为,那么我们得到一个
的混淆矩阵,
表示第
类样本被预测为第
类的数量,多分类的混淆矩阵如下所示
![]()
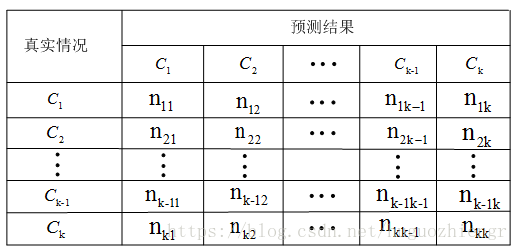
第类的查准率
为
第i类查全率为
那么对于整个模型来说,其查准率与查全率该如何定义呢?我还没有查到相关比较权威的定义,先提一点个人的想法,如果对每一类的分类查准率与查全率没有权重的话,可以各类的查准率与查全率相加,然后计算平均值,再代入公式(1)和公式(3)中计算;如果有权重的话,则将各类的查准率与查全率加以相应权重,然后计算平均值,再代入公式(1)和公式(3)中计算,注意这种情况下会有两次加权,一次是对不同类的加权,一次是对查准率与查全率的加权。
3. 模型评价
现在考虑这样一个问题,假设一个分类模型在大小为30的验证集上分类准确率为85%,能否说这个模型的分类正确率就是85%?再来一个大小为100的验证集,是否一定有约85个左右的样本能被正确分类呢?应该说不是这样的,对于这种情况,我们需要计算该模型分类准确率的置信区间,这是评估该模型的比较准确的做法。
一个样本的分类过程可以视为一次概率为 的伯努利过程,其中
为模型真实的分类正确率,那么一个样本集的分类则可以看作概率为
的二项分布实验,期望为
,方差为
。设
是在一次测试过程中、样本中被正确分类的个数,
表示本次的分类正确率,则依据中心极限定理可知,当样本数量
足够大时,则以下统计量
服从标准正态分布,在选定置信度 后,可以计算
的置信区间为
即
将其转化为等式、利用一元二次多项式根的公式
求解,得到p的置信区间为
例如,现有一个分类模型在100个样本上有80%的正确率,则其在95%的置信水平下,真实准确率的置信区间为多少?首先查阅标准正态分布概率表,95%的置信度对应的为1.96,将
,
代入到上式中,计算得到置信区间为
。
4. 模型比较
现在考虑这样一个问题,分类模型1在100个样本上的正确率为85%,分类模型2在5000个样本上的正确率为75%,那么模型1的真实分类准确率一定比模型2高吗?我们还是从模型分类正确率的显著性上出发来比较二者。
依据中心极限定理可知,但样本数量足够大时,模型1和模型2上样本分类正确率的分布是两个相互独立的正态分布,模型1上分类正确率,模型上2分类正确率
,为了比较模型1与模型2的分类正确率的差异,现在建立二者正确率观测差统计量
依据中心极限定理,统计量也服从正态分布
,其均值
为
方差可以估计为
这样可以计算在置信度
下的置信区间
一旦计算出的置信区间你跨过了零值,表示在选定的置信度下,观测的正确率差值可能为负,也即是我们不能认为模型1比模型2的真实分类正确率更高。
在实际应用中,更常见的可能是这样一种比较情况:在一个样本集上采用 交叉验证法去比较两个模型的分类效果。对与模型1和模型2,我们还是构建一个和上面一样计算
,那么在
次交叉实验中,我们可以观测到
个
值,此时可以构建一个双样本的
统计量
其中表示在
次交叉实验中观测到的
的平均值,
表示
的标准差,
表示
的平均值,
表示
的平均值。在
足够大时,可以用
的标准差除以
来估计
的,也即是
在置信度为时,可以算得
的置信区间为
同样的,若计算得到的置信区间跨过零值,则表明不能认为模型1比模型2更优。