06.Mapreduce实例——Reduce端join
实验目的
1.了解reduce端join的适用场景
2.准确理解reduce端join的设计原理
3.熟练掌握reduce端join程序代码的编写
实验原理
在Reudce端进行Join连接是MapReduce框架进行表之间Join操作最为常见的模式。
1.Reduce端Join实现原理
(1)Map端的主要工作,为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
(2)Reduce端的主要工作,在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
2.Reduce端Join的使用场景
Reduce端连接比Map端连接更为普遍,因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,但是Reduce端连接效率比较低,因为所有数据都必须经过Shuffle过程。
3.本实验的Reduce端Join代码执行流程:
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在Reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同的key值进行Join连接操作,求出结果并直接输出。
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
hadoop-2.6.0-eclipse-cdh5.4.5.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
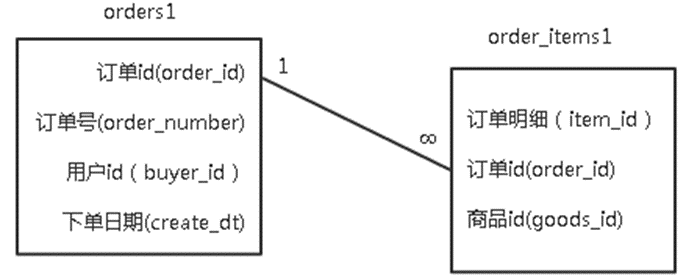
现有某电商网站两张信息表,分别为订单表orders1和订单明细表order_items1,orders1表记录了用户购买商品的下单日期以及订单编号,order_items1表记录了商品id,订单id以及明细id,它们的表结构以及关系如下图所示。
两表的数据内容如下:
orders1表
- 订单ID 订单号 用户ID 下单日期
- 52304 111215052630 176474 2011-12-15 04:58:21
- 52303 111215052629 178350 2011-12-15 04:45:31
- 52302 111215052628 172296 2011-12-15 03:12:23
- 52301 111215052627 178348 2011-12-15 02:37:32
- 52300 111215052626 174893 2011-12-15 02:18:56
- 52299 111215052625 169471 2011-12-15 01:33:46
- 52298 111215052624 178345 2011-12-15 01:04:41
- 52297 111215052623 176369 2011-12-15 01:02:20
- 52296 111215052622 178343 2011-12-15 00:38:02
- 52295 111215052621 178342 2011-12-15 00:18:43
- 52294 111215052620 178341 2011-12-15 00:14:37
- 52293 111215052619 178338 2011-12-15 00:13:07
order_items1表
- 明细ID 订单ID 商品ID
- 252578 52293 1016840
- 252579 52293 1014040
- 252580 52294 1014200
- 252581 52294 1001012
- 252582 52294 1022245
- 252583 52294 1014724
- 252584 52294 1010731
- 252586 52295 1023399
- 252587 52295 1016840
- 252592 52296 1021134
- 252593 52296 1021133
- 252585 52295 1021840
- 252588 52295 1014040
- 252589 52296 1014040
- 252590 52296 1019043
要求查询在2011-12-15日该电商都有哪些用户购买了什么商品。
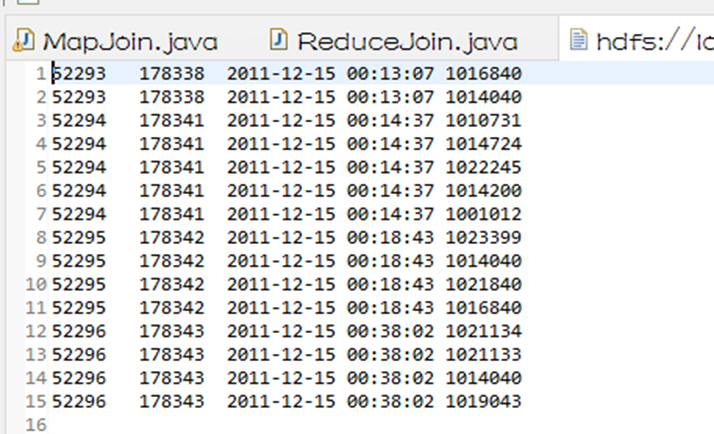
结果数据如下:
- 订单ID 用户ID 下单日期 商品ID
- 52293 178338 2011-12-15 00:13:07 1016840
- 52293 178338 2011-12-15 00:13:07 1014040
- 52294 178341 2011-12-15 00:14:37 1010731
- 52294 178341 2011-12-15 00:14:37 1014724
- 52294 178341 2011-12-15 00:14:37 1022245
- 52294 178341 2011-12-15 00:14:37 1014200
- 52294 178341 2011-12-15 00:14:37 1001012
- 52295 178342 2011-12-15 00:18:43 1023399
- 52295 178342 2011-12-15 00:18:43 1014040
- 52295 178342 2011-12-15 00:18:43 1021840
- 52295 178342 2011-12-15 00:18:43 1016840
- 52296 178343 2011-12-15 00:38:02 1021134
- 52296 178343 2011-12-15 00:38:02 1021133
- 52296 178343 2011-12-15 00:38:02 1014040
- 52296 178343 2011-12-15 00:38:02 1019043
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/mapreduce6目录。
- mkdir -p /data/mapreduce6
3.在Linux中切换到/data/mapreduce6目录下,用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/orders1和http://192.168.1.100:60000/allfiles/mapreduce6/order_items1网址上下载文本文件orders1,order_items1。
- cd /data/mapreduce6
- wget http://192.168.1.100:60000/allfiles/mapreduce6/orders1
- wget http://192.168.1.100:60000/allfiles/mapreduce6/order_items1
然后在当前目录下用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
- wget http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz
将hadoop2lib.tar.gz解压到当前目录下。
- tar zxvf hadoop2lib.tar.gz
4.首先在HDFS上新建/mymapreduce6/in目录,然后将Linux本地/data/mapreduce6目录下的orders1和order_items1文件导入到HDFS的/mymapreduce6/in目录中。
- hadoop fs -mkdir -p /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/orders1 /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/order_items1 /mymapreduce6/in
5.新建Java Project项目,项目名mapreduce6。
在mapreduce6下新建包,包名为mapreduce。
在mapreduce包下新建类,类名为ReduceJoin。
6.添加项目所需依赖的jar包,右键单击项目,新建一个目录,用于存放项目所需的jar包。
将/data/mapreduce6目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce6项目的hadoop2lib目录下。
选中hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码,并描述其设计思路。
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同key值进行join连接操作,求出结果并直接输出。
Mapreduce中join连接分为Map端Join与Reduce端Join,这里是一个Reduce端Join连接。程序主要包括两部分:Map部分和Reduce部分。
Map代码
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- //获取行文本内容
- String line = value.toString();
- //对行文本内容进行切分
- String[] arr = line.split("\t");
- ///把结果写出去
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
Map处理的是一个纯文本文件,Mapper处理的数据是由InputFormat将数据集切分成小的数据集InputSplit,并用RecordReader解析成<key,value>对提供给map函数使用。在map函数中,首先用getPath()方法获取分片InputSplit的路径并赋值给filePath,if判断filePath中如果包含goods.txt文件名,则将map函数输入的value值通过Split("\t")方法进行切分,与goods_visit文件里相同的商品id字段作为key,其他字段前加"1+"作为value。如果if判断filePath包含goods_visit.txt文件名,步骤与上面相同,只是把其他字段前加"2+"作为value。最后把<key,value>通过Context的write方法输出。
Reduce代码
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>(); //用来存放左表的数据
- Vector<String> right = new Vector<String>(); //用来存放右表的数据
- //迭代集合数据
- for (Text val : values) {
- String str = val.toString();
- //将集合中的数据添加到对应的left和right中
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- //获取left和right集合的长度
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- //遍历两个向量将结果写进去
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
map函数输出的<key,value>经过shuffle将key相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数。reduce函数中,首先新建两个Vector集合,用于存放输入的values中以"1+"开头和"2+"开头的数据。然后用增强版for循环遍历并嵌套if判断,若判断values里的元素以1+开头,则通过substring(2)方法切分元素,结果存放到left集合中,若values里元素以2+开头,则仍利用substring(2)方法切分元素,结果存放到right集合中。最后再用两个嵌套for循环,遍历输出<key,value>,其中输入的key直接赋值给输出的key,输出的value为left +"\t"+right。
完整代码
- package mapreduce;
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Vector;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class ReduceJoin {
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- //System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- //System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>();
- Vector<String> right = new Vector<String>();
- for (Text val : values) {
- String str = val.toString();
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- Job job = Job.getInstance();
- job.setJobName("reducejoin");
- job.setJarByClass(ReduceJoin.class);
- job.setMapperClass(mymapper.class);
- job.setReducerClass(myreducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- Path left = new Path("hdfs://localhost:9000/mymapreduce6/in/orders1");
- Path right = new Path("hdfs://localhost:9000/mymapreduce6/in/order_items1");
- Path out = new Path("hdfs://localhost:9000/mymapreduce6/out");
- FileInputFormat.addInputPath(job, left);
- FileInputFormat.addInputPath(job, right);
- FileOutputFormat.setOutputPath(job, out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
8.在ReduceJoin类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
9.待执行完毕后,进入命令模式下,在hdfs上从Java代码指定的路径中查看实验结果。
- hadoop fs -ls /mymapreduce6/out
- hadoop fs -cat /mymapreduce6/out/part-r-00000
06.Mapreduce实例——Reduce端join
实验目的
1.了解reduce端join的适用场景
2.准确理解reduce端join的设计原理
3.熟练掌握reduce端join程序代码的编写
实验原理
在Reudce端进行Join连接是MapReduce框架进行表之间Join操作最为常见的模式。
1.Reduce端Join实现原理
(1)Map端的主要工作,为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
(2)Reduce端的主要工作,在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
2.Reduce端Join的使用场景
Reduce端连接比Map端连接更为普遍,因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,但是Reduce端连接效率比较低,因为所有数据都必须经过Shuffle过程。
3.本实验的Reduce端Join代码执行流程:
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在Reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同的key值进行Join连接操作,求出结果并直接输出。
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
hadoop-2.6.0-eclipse-cdh5.4.5.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
现有某电商网站两张信息表,分别为订单表orders1和订单明细表order_items1,orders1表记录了用户购买商品的下单日期以及订单编号,order_items1表记录了商品id,订单id以及明细id,它们的表结构以及关系如下图所示。
两表的数据内容如下:
orders1表
- 订单ID 订单号 用户ID 下单日期
- 52304 111215052630 176474 2011-12-15 04:58:21
- 52303 111215052629 178350 2011-12-15 04:45:31
- 52302 111215052628 172296 2011-12-15 03:12:23
- 52301 111215052627 178348 2011-12-15 02:37:32
- 52300 111215052626 174893 2011-12-15 02:18:56
- 52299 111215052625 169471 2011-12-15 01:33:46
- 52298 111215052624 178345 2011-12-15 01:04:41
- 52297 111215052623 176369 2011-12-15 01:02:20
- 52296 111215052622 178343 2011-12-15 00:38:02
- 52295 111215052621 178342 2011-12-15 00:18:43
- 52294 111215052620 178341 2011-12-15 00:14:37
- 52293 111215052619 178338 2011-12-15 00:13:07
order_items1表
- 明细ID 订单ID 商品ID
- 252578 52293 1016840
- 252579 52293 1014040
- 252580 52294 1014200
- 252581 52294 1001012
- 252582 52294 1022245
- 252583 52294 1014724
- 252584 52294 1010731
- 252586 52295 1023399
- 252587 52295 1016840
- 252592 52296 1021134
- 252593 52296 1021133
- 252585 52295 1021840
- 252588 52295 1014040
- 252589 52296 1014040
- 252590 52296 1019043
要求查询在2011-12-15日该电商都有哪些用户购买了什么商品。
结果数据如下:
- 订单ID 用户ID 下单日期 商品ID
- 52293 178338 2011-12-15 00:13:07 1016840
- 52293 178338 2011-12-15 00:13:07 1014040
- 52294 178341 2011-12-15 00:14:37 1010731
- 52294 178341 2011-12-15 00:14:37 1014724
- 52294 178341 2011-12-15 00:14:37 1022245
- 52294 178341 2011-12-15 00:14:37 1014200
- 52294 178341 2011-12-15 00:14:37 1001012
- 52295 178342 2011-12-15 00:18:43 1023399
- 52295 178342 2011-12-15 00:18:43 1014040
- 52295 178342 2011-12-15 00:18:43 1021840
- 52295 178342 2011-12-15 00:18:43 1016840
- 52296 178343 2011-12-15 00:38:02 1021134
- 52296 178343 2011-12-15 00:38:02 1021133
- 52296 178343 2011-12-15 00:38:02 1014040
- 52296 178343 2011-12-15 00:38:02 1019043
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/mapreduce6目录。
- mkdir -p /data/mapreduce6
3.在Linux中切换到/data/mapreduce6目录下,用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/orders1和http://192.168.1.100:60000/allfiles/mapreduce6/order_items1网址上下载文本文件orders1,order_items1。
- cd /data/mapreduce6
- wget http://192.168.1.100:60000/allfiles/mapreduce6/orders1
- wget http://192.168.1.100:60000/allfiles/mapreduce6/order_items1
然后在当前目录下用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
- wget http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz
将hadoop2lib.tar.gz解压到当前目录下。
- tar zxvf hadoop2lib.tar.gz
4.首先在HDFS上新建/mymapreduce6/in目录,然后将Linux本地/data/mapreduce6目录下的orders1和order_items1文件导入到HDFS的/mymapreduce6/in目录中。
- hadoop fs -mkdir -p /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/orders1 /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/order_items1 /mymapreduce6/in
5.新建Java Project项目,项目名mapreduce6。
在mapreduce6下新建包,包名为mapreduce。
在mapreduce包下新建类,类名为ReduceJoin。
6.添加项目所需依赖的jar包,右键单击项目,新建一个目录,用于存放项目所需的jar包。
将/data/mapreduce6目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce6项目的hadoop2lib目录下。
选中hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码,并描述其设计思路。
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同key值进行join连接操作,求出结果并直接输出。
Mapreduce中join连接分为Map端Join与Reduce端Join,这里是一个Reduce端Join连接。程序主要包括两部分:Map部分和Reduce部分。
Map代码
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- //获取行文本内容
- String line = value.toString();
- //对行文本内容进行切分
- String[] arr = line.split("\t");
- ///把结果写出去
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
Map处理的是一个纯文本文件,Mapper处理的数据是由InputFormat将数据集切分成小的数据集InputSplit,并用RecordReader解析成<key,value>对提供给map函数使用。在map函数中,首先用getPath()方法获取分片InputSplit的路径并赋值给filePath,if判断filePath中如果包含goods.txt文件名,则将map函数输入的value值通过Split("\t")方法进行切分,与goods_visit文件里相同的商品id字段作为key,其他字段前加"1+"作为value。如果if判断filePath包含goods_visit.txt文件名,步骤与上面相同,只是把其他字段前加"2+"作为value。最后把<key,value>通过Context的write方法输出。
Reduce代码
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>(); //用来存放左表的数据
- Vector<String> right = new Vector<String>(); //用来存放右表的数据
- //迭代集合数据
- for (Text val : values) {
- String str = val.toString();
- //将集合中的数据添加到对应的left和right中
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- //获取left和right集合的长度
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- //遍历两个向量将结果写进去
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
map函数输出的<key,value>经过shuffle将key相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数。reduce函数中,首先新建两个Vector集合,用于存放输入的values中以"1+"开头和"2+"开头的数据。然后用增强版for循环遍历并嵌套if判断,若判断values里的元素以1+开头,则通过substring(2)方法切分元素,结果存放到left集合中,若values里元素以2+开头,则仍利用substring(2)方法切分元素,结果存放到right集合中。最后再用两个嵌套for循环,遍历输出<key,value>,其中输入的key直接赋值给输出的key,输出的value为left +"\t"+right。
完整代码
- package mapreduce;
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Vector;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class ReduceJoin {
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- //System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- //System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>();
- Vector<String> right = new Vector<String>();
- for (Text val : values) {
- String str = val.toString();
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- Job job = Job.getInstance();
- job.setJobName("reducejoin");
- job.setJarByClass(ReduceJoin.class);
- job.setMapperClass(mymapper.class);
- job.setReducerClass(myreducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- Path left = new Path("hdfs://localhost:9000/mymapreduce6/in/orders1");
- Path right = new Path("hdfs://localhost:9000/mymapreduce6/in/order_items1");
- Path out = new Path("hdfs://localhost:9000/mymapreduce6/out");
- FileInputFormat.addInputPath(job, left);
- FileInputFormat.addInputPath(job, right);
- FileOutputFormat.setOutputPath(job, out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
8.在ReduceJoin类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
9.待执行完毕后,进入命令模式下,在hdfs上从Java代码指定的路径中查看实验结果。
- hadoop fs -ls /mymapreduce6/out
- hadoop fs -cat /mymapreduce6/out/part-r-00000
06.Mapreduce实例——Reduce端join
实验目的
1.了解reduce端join的适用场景
2.准确理解reduce端join的设计原理
3.熟练掌握reduce端join程序代码的编写
实验原理
在Reudce端进行Join连接是MapReduce框架进行表之间Join操作最为常见的模式。
1.Reduce端Join实现原理
(1)Map端的主要工作,为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
(2)Reduce端的主要工作,在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
2.Reduce端Join的使用场景
Reduce端连接比Map端连接更为普遍,因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,但是Reduce端连接效率比较低,因为所有数据都必须经过Shuffle过程。
3.本实验的Reduce端Join代码执行流程:
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在Reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同的key值进行Join连接操作,求出结果并直接输出。
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
hadoop-2.6.0-eclipse-cdh5.4.5.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
现有某电商网站两张信息表,分别为订单表orders1和订单明细表order_items1,orders1表记录了用户购买商品的下单日期以及订单编号,order_items1表记录了商品id,订单id以及明细id,它们的表结构以及关系如下图所示。
两表的数据内容如下:
orders1表
- 订单ID 订单号 用户ID 下单日期
- 52304 111215052630 176474 2011-12-15 04:58:21
- 52303 111215052629 178350 2011-12-15 04:45:31
- 52302 111215052628 172296 2011-12-15 03:12:23
- 52301 111215052627 178348 2011-12-15 02:37:32
- 52300 111215052626 174893 2011-12-15 02:18:56
- 52299 111215052625 169471 2011-12-15 01:33:46
- 52298 111215052624 178345 2011-12-15 01:04:41
- 52297 111215052623 176369 2011-12-15 01:02:20
- 52296 111215052622 178343 2011-12-15 00:38:02
- 52295 111215052621 178342 2011-12-15 00:18:43
- 52294 111215052620 178341 2011-12-15 00:14:37
- 52293 111215052619 178338 2011-12-15 00:13:07
order_items1表
- 明细ID 订单ID 商品ID
- 252578 52293 1016840
- 252579 52293 1014040
- 252580 52294 1014200
- 252581 52294 1001012
- 252582 52294 1022245
- 252583 52294 1014724
- 252584 52294 1010731
- 252586 52295 1023399
- 252587 52295 1016840
- 252592 52296 1021134
- 252593 52296 1021133
- 252585 52295 1021840
- 252588 52295 1014040
- 252589 52296 1014040
- 252590 52296 1019043
要求查询在2011-12-15日该电商都有哪些用户购买了什么商品。
结果数据如下:
- 订单ID 用户ID 下单日期 商品ID
- 52293 178338 2011-12-15 00:13:07 1016840
- 52293 178338 2011-12-15 00:13:07 1014040
- 52294 178341 2011-12-15 00:14:37 1010731
- 52294 178341 2011-12-15 00:14:37 1014724
- 52294 178341 2011-12-15 00:14:37 1022245
- 52294 178341 2011-12-15 00:14:37 1014200
- 52294 178341 2011-12-15 00:14:37 1001012
- 52295 178342 2011-12-15 00:18:43 1023399
- 52295 178342 2011-12-15 00:18:43 1014040
- 52295 178342 2011-12-15 00:18:43 1021840
- 52295 178342 2011-12-15 00:18:43 1016840
- 52296 178343 2011-12-15 00:38:02 1021134
- 52296 178343 2011-12-15 00:38:02 1021133
- 52296 178343 2011-12-15 00:38:02 1014040
- 52296 178343 2011-12-15 00:38:02 1019043
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/mapreduce6目录。
- mkdir -p /data/mapreduce6
3.在Linux中切换到/data/mapreduce6目录下,用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/orders1和http://192.168.1.100:60000/allfiles/mapreduce6/order_items1网址上下载文本文件orders1,order_items1。
- cd /data/mapreduce6
- wget http://192.168.1.100:60000/allfiles/mapreduce6/orders1
- wget http://192.168.1.100:60000/allfiles/mapreduce6/order_items1
然后在当前目录下用wget命令从http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
- wget http://192.168.1.100:60000/allfiles/mapreduce6/hadoop2lib.tar.gz
将hadoop2lib.tar.gz解压到当前目录下。
- tar zxvf hadoop2lib.tar.gz
4.首先在HDFS上新建/mymapreduce6/in目录,然后将Linux本地/data/mapreduce6目录下的orders1和order_items1文件导入到HDFS的/mymapreduce6/in目录中。
- hadoop fs -mkdir -p /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/orders1 /mymapreduce6/in
- hadoop fs -put /data/mapreduce6/order_items1 /mymapreduce6/in
5.新建Java Project项目,项目名mapreduce6。
在mapreduce6下新建包,包名为mapreduce。
在mapreduce包下新建类,类名为ReduceJoin。
6.添加项目所需依赖的jar包,右键单击项目,新建一个目录,用于存放项目所需的jar包。
将/data/mapreduce6目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce6项目的hadoop2lib目录下。
选中hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码,并描述其设计思路。
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同key值进行join连接操作,求出结果并直接输出。
Mapreduce中join连接分为Map端Join与Reduce端Join,这里是一个Reduce端Join连接。程序主要包括两部分:Map部分和Reduce部分。
Map代码
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- //获取行文本内容
- String line = value.toString();
- //对行文本内容进行切分
- String[] arr = line.split("\t");
- ///把结果写出去
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
Map处理的是一个纯文本文件,Mapper处理的数据是由InputFormat将数据集切分成小的数据集InputSplit,并用RecordReader解析成<key,value>对提供给map函数使用。在map函数中,首先用getPath()方法获取分片InputSplit的路径并赋值给filePath,if判断filePath中如果包含goods.txt文件名,则将map函数输入的value值通过Split("\t")方法进行切分,与goods_visit文件里相同的商品id字段作为key,其他字段前加"1+"作为value。如果if判断filePath包含goods_visit.txt文件名,步骤与上面相同,只是把其他字段前加"2+"作为value。最后把<key,value>通过Context的write方法输出。
Reduce代码
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>(); //用来存放左表的数据
- Vector<String> right = new Vector<String>(); //用来存放右表的数据
- //迭代集合数据
- for (Text val : values) {
- String str = val.toString();
- //将集合中的数据添加到对应的left和right中
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- //获取left和right集合的长度
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- //遍历两个向量将结果写进去
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
map函数输出的<key,value>经过shuffle将key相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数。reduce函数中,首先新建两个Vector集合,用于存放输入的values中以"1+"开头和"2+"开头的数据。然后用增强版for循环遍历并嵌套if判断,若判断values里的元素以1+开头,则通过substring(2)方法切分元素,结果存放到left集合中,若values里元素以2+开头,则仍利用substring(2)方法切分元素,结果存放到right集合中。最后再用两个嵌套for循环,遍历输出<key,value>,其中输入的key直接赋值给输出的key,输出的value为left +"\t"+right。
完整代码
- package mapreduce;
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Vector;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class ReduceJoin {
- public static class mymapper extends Mapper<Object, Text, Text, Text>{
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String filePath = ((FileSplit)context.getInputSplit()).getPath().toString();
- if (filePath.contains("orders1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[0]), new Text( "1+" + arr[2]+"\t"+arr[3]));
- //System.out.println(arr[0] + "_1+" + arr[2]+"\t"+arr[3]);
- }else if(filePath.contains("order_items1")) {
- String line = value.toString();
- String[] arr = line.split("\t");
- context.write(new Text(arr[1]), new Text("2+" + arr[2]));
- //System.out.println(arr[1] + "_2+" + arr[2]);
- }
- }
- }
- public static class myreducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- Vector<String> left = new Vector<String>();
- Vector<String> right = new Vector<String>();
- for (Text val : values) {
- String str = val.toString();
- if (str.startsWith("1+")) {
- left.add(str.substring(2));
- }
- else if (str.startsWith("2+")) {
- right.add(str.substring(2));
- }
- }
- int sizeL = left.size();
- int sizeR = right.size();
- //System.out.println(key + "left:"+left);
- //System.out.println(key + "right:"+right);
- for (int i = 0; i < sizeL; i++) {
- for (int j = 0; j < sizeR; j++) {
- context.write( key, new Text( left.get(i) + "\t" + right.get(j) ) );
- //System.out.println(key + " \t" + left.get(i) + "\t" + right.get(j));
- }
- }
- }
- }
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- Job job = Job.getInstance();
- job.setJobName("reducejoin");
- job.setJarByClass(ReduceJoin.class);
- job.setMapperClass(mymapper.class);
- job.setReducerClass(myreducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- Path left = new Path("hdfs://localhost:9000/mymapreduce6/in/orders1");
- Path right = new Path("hdfs://localhost:9000/mymapreduce6/in/order_items1");
- Path out = new Path("hdfs://localhost:9000/mymapreduce6/out");
- FileInputFormat.addInputPath(job, left);
- FileInputFormat.addInputPath(job, right);
- FileOutputFormat.setOutputPath(job, out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
8.在ReduceJoin类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
9.待执行完毕后,进入命令模式下,在hdfs上从Java代码指定的路径中查看实验结果。
- hadoop fs -ls /mymapreduce6/out
- hadoop fs -cat /mymapreduce6/out/part-r-00000