HashMap 1.8之后的解读
加入了红黑树,并且对hash函数加以改进
b).每个对象都有一个hashcode,但是hashmap并没有直接使用它,而是使用hash函数进行了一次处理,处理完之后用indexfor求出所在的位置。
对于1.7的hash,纯粹是数学计算,不用理会,可以看1.8的hash优化
c).1.8的的hash优化
1 static final int hash(Object key) { 2 int h; // 下面是将低16位和高16位做个异或运算,高16位保持不变 3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 4 }
因为key的原始哈希值很大(int类型,32位),而数组很小,所以如果直接用的话,高位信息将会丢失,会增大冲突的可能性。所以java要做一个优化,将key原始的哈希值低16位和高16位做异或运算,不浪费高位资源,使得低位更随机,详细论述参看:
https://www.cnblogs.com/zhengwang/p/8136164.html
https://www.zhihu.com/question/62923854/answer/204445142
d).对于indexfor
1 static int indexFor(int h, int length) {
2 return h & (length-1);
3 }
h%length,当length是2的次幂时,等价于h & (length-1),因为length为2的次幂时,length - 1的低位全是1,高位全是0,位与运算保留hash值的低位,即对应的余数.位运算要比模运算要快
冲突会少,让数据均匀分布,因为16-1的二进制是1111(掩码)低位的四个全部保留,而15-1的二进制1110,只保留了低位的前三位,丢失了哈希值信息,可以参考下面实验
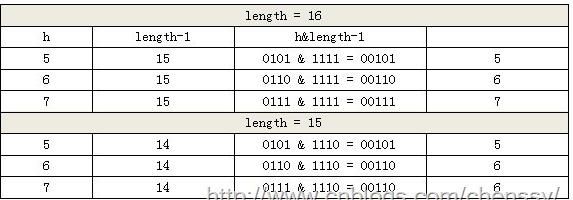
图片来自https://blog.csdn.net/qq_27093465/article/details/52207152
3.常见面试题
https://blog.csdn.net/u012512634/article/details/72735183
好文:http://www.importnew.com/28263.html
1.8详解:https://www.cnblogs.com/yangming1996/p/7997468.html
1.8 hash函数和tableSizeFor的理解:https://blog.csdn.net/fan2012huan/article/details/51097331
理解HashMap:
1.底层结构(数组+ 链表 / 数组+ 链表+ 红黑树 Entry数据结构)
用红黑树可以加快检索速度
2. put方法:
-- 解决冲突的方法(拉链法) 其他方法(开放地址法/再散列法)
-- hashcode()和equals的理解
https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%9F%BA%E7%A1%80.md#hashcode
-- 理解indexfor:
1)HashMap的桶的个数为什么是2的幂
2)为什么要rehash
3.扩容机制以及并发条件下hashmap成环问题
https://blog.csdn.net/u011305680/article/details/80511885
-- jdk7 总结
创建一个新的数组newTable,容量是oldTable的一倍
遍历oldTable,拿到每个链表
遍历链表,头插法插入newTable
-- jdk8 高低位链表
hash值h二进制为 0010 1100 1111 0001 1110 1110
旧容量为length=16,二进制为 0001 0000
两个相与,可以计算出低位第五位的二进制数是否是1,从而确定高低链
-- 成环问题 因为1.7是头插法,而头插法会导致成环 https://coolshell.cn/articles/9606.html hashmap1.8不会成环,因为尾插,但并发条件下还是用concurrenthashmap的好
4.键值允许为null,默认index=0
5.hashtable,hashmap,concurrenthashmap简要对比https://www.cnblogs.com/heyonggang/p/9112731.html
6.concurrenthashmap好文https://www.cnblogs.com/shan1393/p/9020564.html
7. 1.7和1.8的不同
-- 底层结构
1.7 数组加链表; 1.8 是数组加链表,再加红黑树(数量为8转成红黑树,数量为6转成链表)
-- hash方法
1.8的更加简单,高位右移十六位再做异或
-- 扩容机制的不同
1.8 不会成环(尾插)
· 1.8 不用再次求index(高低链表)
-------以上是优化
-- 扩容的条件
1.7 :size > threshold && bucket[hashIndex] != null
1.8:size > threshold
-- 1.8中的扩容包含了初始化
-- 为什么不用AVL https://blog.csdn.net/hustyangju/article/details/27214251?utm_source=tuicool
8 concurrenthashmap:
1.8相当于放弃了segment结构,直接使用数组的第一个对象作为该链表的锁。