概述
在查找数据库分库分表的资料的时候看到了这一个回答,为什么几乎所有的开源数据库中间件都是国内公司开源的?并且几乎都停止了更新? 知道了当数据量大的时候最直接彻底的解决方案就是分布式数据库了,但是由于技术和运维程度来说,中小公司是无法承载的,所以数据库分库分表这一解决方案就出现了。
分布式数据库的动机
摘自分布式数据库
在互联网领域,规模越大,任务越要分散化,随着业务的成长,架构从最原始的 PHP/Tomcat+MySQL,走到前后端分离,实质是规避服务器的CPU、磁盘I/O、带宽因请求众多而竞争激烈带来的相互影响(导致大量的Web并发请求被堵塞或者变慢,极度影响用户体验),当然体量越来越大,后端的数据库依然需要与性能瓶颈做斗争,数据库本身也逐步走向读写分离,再发展到分布式数据库。
分库分表数据切分
下面描述来自 https://www.cnblogs.com/butterfly100/p/9034281.html ,非原创
垂直分表
表中太多字段了,把一些字段分到新的表中,于是表的大小整体就变小了 垂直切分的优点:
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
缺点:
- 部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
- 分布式事务处理复杂
- 依然存在单表数据量过大的问题(需要水平切分)
水平分表
某种表中的数据太多了,表的结构不动它,复杂多个表的结构,当插入数据的时候使用分配策略,数据分散在各个表中。 水平切分的优点:
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
缺点:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 数据多次扩展难度和维护量极大
分库分表带来的问题
下面罗列的问题并不一定完全,讲的也比较粗糙,这里只是提供一个思路,各位要是在生活中遇到,则可以针对某个方面进行解决。
事务
由于分成了多个库所以需要分布式事务来解决事务问题,一般可使用"XA协议"和"两阶段提交"处理。而假如对一致性没有那么高要求的我们只要达到最终一致性的,我们可以通过以下方式 : 对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等等。事务补偿还要结合业务系统来考虑。
join 联立查表
建立全局表等,相当于全局的属性表。
分页,排序,函数
分页,排序函数等都可以通过将数据取出会再进行对应的操作,例如以下的查询操作。

唯一主键
这里可以使用一些框架来生成,例如: Leaf——美团点评分布式ID生成系统
案例补充--用户中心-运营侧最佳实践
例子引用自参考文章,非原创,假如我们存在以下架构查询 :
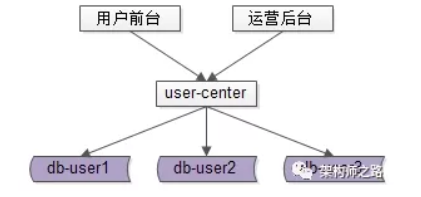
前台用户侧,业务需求基本都是单行记录的访问,只要建立非uid属性 login_name / phone / email 到uid的映射关系,就能解决问题;后台运营侧,业务需求各异,基本是批量分页的访问,这类访问计算量较大,返回数据量较大,比较消耗数据库性能。 如果此时前台业务和后台业务公用一批服务和一个数据库,有可能导致,由于后台的“少数几个请求”的“批量查询”的“低效”访问,导致数据库的cpu偶尔瞬时100%,影响前台正常用户的访问(例如,登录超时)。 而且,为了满足后台业务各类“奇形怪状”的需求,往往会在数据库上建立各种索引,这些索引占用大量内存,会使得用户侧前台业务uid/login_name上的查询性能与写入性能大幅度降低,处理时间增长。 对于这一类业务,应该采用“前台与后台分离”的架构方案:
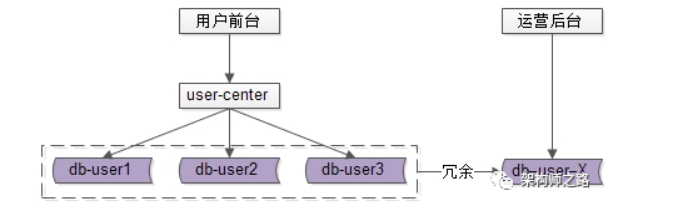
用户侧前台业务需求架构依然不变,产品运营侧后台业务需求则抽取独立的web / service / db 来支持,解除系统之间的耦合,对于“业务复杂”“并发量低”“无需高可用”“能接受一定延时”的后台业务:
- 可以去掉service层,在运营后台web层通过dao直接访问db
- 不需要反向代理,不需要集群冗余
- 不需要访问实时库,可以通过MQ或者线下异步同步数据
- 在数据库非常大的情况下,可以使用更契合大量数据允许接受更高延时的“索引外置”或者倒排索引或者“HIVE”的设计方案
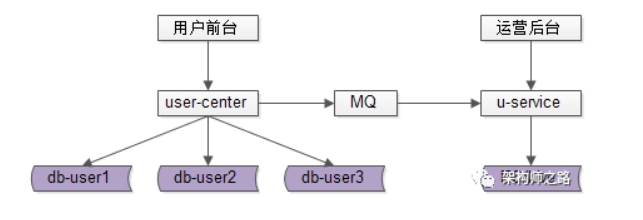
总结 : 运营后台侧,“前台与后台分离”最佳实践:
- 前台、后台系统web/service/db分离解耦,避免后台低效查询引发前台查询抖动
- 可以采用数据冗余的设计方式
- 可以采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求
数据迁移
见参考文章,迁移的主要核心步骤就是 : 迁移数据 -> 追平旧库 -> 校验数据
参考资料
- cnblogs.com/butterfly100/p/9034281.html
- https://www.zhihu.com/question/352256403
- https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651960212&idx=1&sn=ab4c52ab0309f7380f7e0207fa357128&pass_ticket=G8v3RrpK9Is7NJZH0fOShUfY8lp5oz9un8K5L24LeGGVtiBTXkBMc9UKkTMdQeDS (推荐一看)
- https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651959992&idx=1&sn=eb2fbd7d7922db42a593c304e50a65b7&chksm=bd2d07648a5a8e72d489022ec6006274d7e43ab48449b255d5661658c2af8e9221977a9609ed&scene=21#wechat_redirect (数据迁移相关)
- https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651959883&idx=1&sn=e7df8510c7096a5b069e0f12eaaca010&chksm=bd2d07978a5a8e815c2ae41b16b6b4c579923502fb919008a22bb108a1e920109f25387f8903&scene=21#wechat_redirect (库扩容相关)