近年来二手房市场已经成为一个不可忽视的存在。从价格的节节攀升,到交易量的持续增长;从大中介公司的“跑马圈地”,到小中介公司林立,二手房市场已经开始“奔跑着歌
唱”,更重要的是,二手房已经纳入了越来越多老百姓置业的考虑范围。
二手房市场是离普通百姓最近的住房市场,二手房市场的健康发展,对于整个房地产市场的全面启动有着巨大了拉动作用。二手房的价格也成为房地产市场发展中至关重要的存
在。于是我爬取了贝壳租房的信息,用来研究二手房市场的租房情况,主要定位在广州这一边。
- 广州各区出租房量
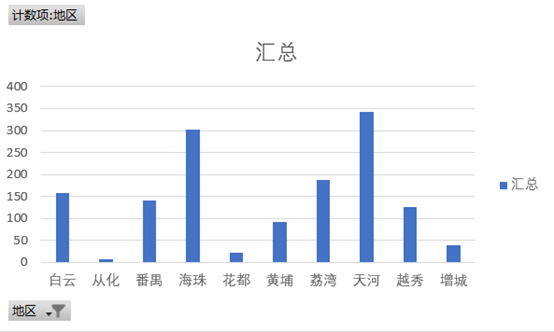
我们从这里看得出广州的老七区中越秀区、海珠区、荔湾区、白云区、黄浦区、海珠区相对于广州新四区中的番禺区、从化区、增城区、花都区所开放的租房是比较多的,而其中
老七区中的天河是所有的地区中最多的,看得出越繁荣的地区二手房开放的越多。
- 出租房时间发布情况

由图我们可以看的出广州出租房发布量还是很多的,然而2个月之前的发布量是非常少,由此可以看的广州出租房的需求量是非常大的,一般发布了一个月之后都被奋斗的人员所租走,还有一些会在两个
月以后被租走。
- 广州出租房房价的情况
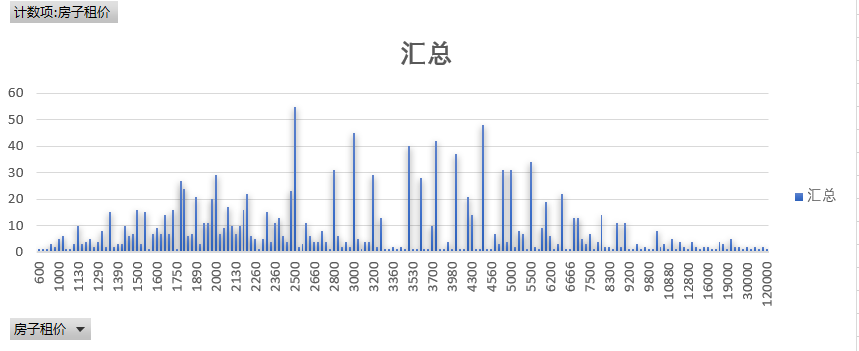
从这里的情况我们可以看的出广州的出租房租费的范围是从600元/月到12000元/月,而其中2500的房费是最多的,4500是排行第二的房费,而3000的房费排行第三,看的出在广
州租房是非常贵的,如果是一个人租房的话必须的拿出几千多的房费来居住,在算上吃的、娱乐的以及水电费每个没有房子的奋斗人士需要5000以上的工资。
- 出租房与楼层的关系

这里的低楼层指10层一下、中楼层指10-20层、高楼层指20层以上。由图我们总的可以看得出高楼层的出租房相对于中低楼层来说是比较多,但是在房费方面勒,中楼层在低价方面还是胜率与 高楼层的,而2500元/月到4000元的价格中高楼层还是处于霸主的地位远超其他的房价。
- 总结
广州的出租房市场还是处于比较繁荣的阶段,每个月发布的数量非常多而被租的数量也非常多,这源自于广州的外来人口非常多的原因,而在老区中的天河、越秀的工作岗位非常多,从而那里出租房的数量非常大,因此那里的出租房数量非常的多。而新区的例如增城区、花都区的工作岗位比较少相对比较落后,因此那里的出租房数量比较少。而在广州这里的出租房的费用是非常的贵。

从里看的出,1000-2000元/月的出租屋是最多的。因此想要在广州工作还没房子的话,你得保证你得工资花费完之后还要抽出这个费用用来居住。
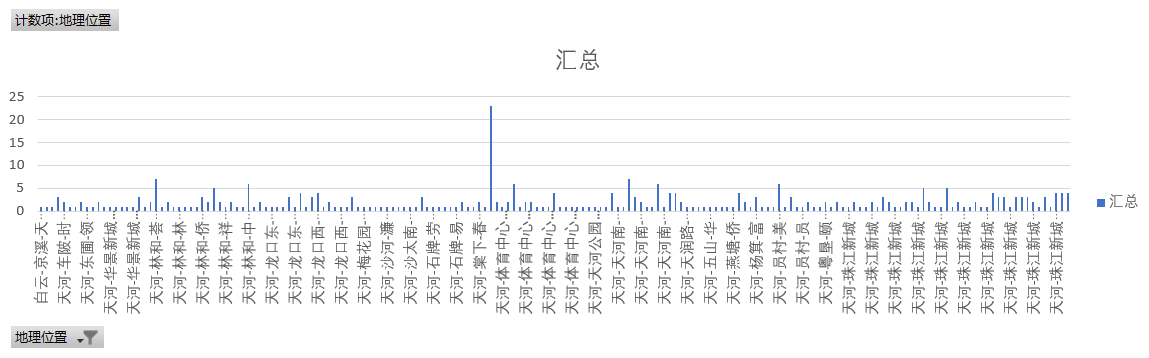

但是别急在天河区中,我们从这两张图看的出,棠夏得出租房是最多,而房价求和(就是将出租房数量×出租房得价钱)是最低,所以刚出来工作的人工资不高是可以考虑去这里租房,而珠江新城的出租房的数量是最少的,但是房价求和是最贵的,如果有钱想要环境好可以考虑这里租房。房价其实和楼层的影响不大,可以随心选自己喜欢的楼层进行租房。
技术实现
python代码
import requests
from datetime import datetime
from bs4 import BeautifulSoup
import jieba
import pandas as pd
import time
import random
import sqlite3
def getDisc(tag):
total = {}
chage = []
ziliao = tag.select('.content__list--item--des')[0].text
s = ziliao.split(' ')
s = [x.strip() for x in s]
s = [x.strip() for x in s if x.strip() != '']
s = [x.strip() for x in s if x.strip() != '/']
if len(s) == 6:
s[0] = s[0].strip('
/')
s[2] = s[2].strip('/')
total['地理位置'] = s[0]
total['房子大小'] = s[1]
total['房子朝向'] = s[2]
total['房子格局'] = s[3]
total['房子楼层'] = s[4]
total['房子层数'] = s[5]
total['房子租价'] = tag.select('.content__list--item-price')[0].text.strip('元/月')
total['发布时间'] = tag.select('.content__list--item--time')[0].text
chage.append(total)
return chage
def getInfor(url):
resourses = requests.get(url)
resourses.encoding = 'UTF-8'
soup = BeautifulSoup(resourses.text, 'html.parser')
infor = []
for tag in soup.find_all('div', class_='content__list--item--main'):
infor.extend(getDisc(tag))
return infor
allnews = []
url = 'https://gz.zu.ke.com/zufang?unique_id=6812048e-8d7a-4591-92ec-02d371a5e753zufang1556269286214'
# getInfor(url)
allnews.extend(getInfor(url))
print(allnews)
for i in range(2, 100):
time.sleep(random.random() * 3) # 设置爬取的时间间隔
listUrl = 'https://gz.zu.ke.com/zufang/pg{}/?unique_id=2af93b62-8b69-4075-88ba-30a676ab4103zufangpg'.format(i)
allnews.extend(getInfor(listUrl))
newsdf = pd.DataFrame(allnews)
newsdf.to_csv(r'D:Downloadgzcc.csv', encoding='utf_8_sig') # 保存成csv格式,为避免乱码,设置编码格式为utf_8_sig
挖出的数据模型
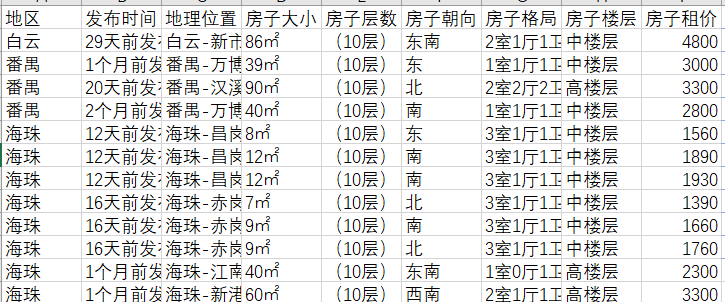
数据处理删除违规的数据