第6章 执行期语意学
6.1 对象的构造和析构
constructor和destructor的安排
{
if (cache)
// 检查cache; 如果温和就传回1
return 1;
Point point;
// constructor在这里行动
switch(int(point.x())) {
case -1:
// numble;
// destructor在这里行动
return;
case 0:
// numble;
// destructor在这里行动
return;
case 1:
// numble;
// destructor在这里行动
default:
// numble;
// destructor在这里行动
return;
}
}
另外也很有可能在这个区段的结束符号(右大括号)之前被生出来, 即使程序分析的结构发现绝不会进行到那里, 一般而言会把object尽可能放置在使用它的那个程序区段附近, 这么做可以节省非必要的对象产生操作或摧毁操作
全局对象
Matrix identity;
main() {
// identity必须在此处被初始化
matrix m1 = identity;
//...
return 0;
}
C++保证, 一定会在main()函数第一次用到identify之前, 把identify构造出来, 而在main()函数结束之前把identify摧毁掉. 像identify这样的所谓的global object如果有constructor和destructor的话, 我们说他需要静态的初始化操作和内存释放操作
C++程序中所有的global objects都被放置在程序的data segment中. 如果显式指定给它一个值, 此object将以该值为初值. 否则object所配置到的内存内容为0(这和C略有不同, C并不自动设定初值). 在C语言中一个global object只能够被一个常量表达式(可在编译时期求其值的那种)设定初值. 当然constructor并不是常量表达式. 虽然class object在编译时期可以被放置于data segment中并且内容为0, 但constructor一直要到程序启动(startup)时才会实施. 必须对一个"放置于program data segment中的object的初始化表达式"做评估(evaluate), 这正是为什么object需要静态初始化的原因.
我的理解是data segment(包括object)中的值全为0, 只是在main函数执行时, 设定了值(object 执行constructor操作)
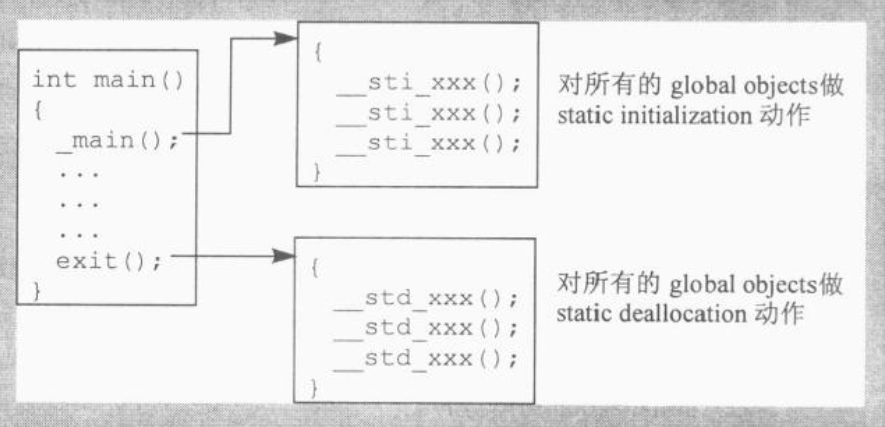
当cfront还是唯一的C++编译器, 而且跨平台移植性比效率的考虑更重要的时候,有一个可移植但成本颇高的静态初始化(以及内存释放)方法, 称为munch策略:
(1) 为每一个需要静态初始化的文件产生一个_sti()函数, 内含必要的constructor调用操作或是inline expansions. 例如起前面所说的identify对象会在matrix.c中产生出下面的_sti()函数(可能是static initialization的缩写):
__sti__matrix_c__identity() {
// C++伪码
identify.Matrix::Matrix; // 这就是static initialization
}
(2) 在每一个需要静态的内存释放操作的文件中, 产生一个__std()函数(可能是static deallocation的缩写), 内含必要的destructor调用操作, 或是其inline expansions
(3) 提供一组runtime library "munch"函数: 一个_main()函数(用以调用可执行文件中的所有__sti()函数), 以及一个exit()函数(以类似方式调用所有的_std()函数)
cfront 2.0版之前并不支持nonclass object的静态初始化操作; 也就是说C语言的限制仍然残留着. 所以下面的每一个初始化操作都被标记为不合法:
extern int i;
// 全部都要求静态初始化(static initialization)
// 在2.0版之前的C和C++中, 这些都是不合法的
int j = i;
int *pi = new int(i);
double sal = compute_sal(get_employee(i));
使用被静态初始化的objects, 有下列缺点:
(1) 如果exception handling被支持, 那些objects将不能够被放置于try区段之内. 这对于被静态调用的constructors可能是特别无法接受的, 因为任何的throw操作将必然触发exception handling library默认的terminate()函数
(2) 为了控制"需要跨越模块做静态初始化"的objects的相依顺序, 而扯出来的复杂度
作者建议根本就不要用那些需要静态初始化的global objects(虽然这项建议几乎普遍不为C程序员所接收)
局部静态对象
const Matrix& identity() {
static Matrix mat_identity;
// ...
return mat_identity;
}
- mat_identity的constructor必须只能实施一次, 虽然上述函数可能被调用多次
- mat_identify的destructor必须只能实施一次, 虽然上述函数可能会被调用多次
编译器的策略之一就是, 无条件地在程序起始(startup)时构造出对象来. 然而这会导致所有的local static class objects都在程序起始时被初始化, 即使它们所在的那个函数从不曾被调用过
实际上identify()被调用时才把mat_identity构造起来是一种更好的做法, 现在的C+标准已经强制要求这一点
类中static数据成员未初始化时, 在第一次使用该值时会报错, 很难定位错误位置
cfront的做法: 首先导入一个临时性对象以保护mat_identity的初始化操作. 第一次处理identify()时, 这个临时对象被评估为false, 于是constructor会被调用, 然后临时对象被改为true. 这样就解决了构造的问题. 而在相反的那一端, destructor也需要有条件地施行于mat_identity身上, 但只有mat_identity已经被构造起来才算数, 可以通过那个临时对象是否为true来判断mat_identity是否已经构造
对象数组
Point knots[10]; // 没有明显初值
如果Point没有定义一个constructor也没有定义一个destructor, 那么上面代码所执行的工作不会比"内建(build-in)类型所组成的数组"更多(即不会调用下面所要讲到的vec_new()), 也就是说我们只要配置足够内存以存在10个连续的Point元素即可
然而Point的确定义了一个default destructor, 所以这个destructor必须轮流施行于每一个元素之上. 一般而言这是经由一个或多个runtime library函数达成的. 在cfront中, 使用一个被命名为vec_new()的函数, 产生出以class objects构造而成的数组. (比较新近的编译器, 则是提供两个函数, 一个用来处理"没有virtual base class"的class, 另一个用来处理"内含virtual base class"的class, 后一个函数通常被称为vec_vnew), vec_new()类型通常如下:
void* vec_new(
void *array, // 数组起始地址
size_t elem_size; // 每一个class object的大小
int elem_count; // 数组中的元素个数
void (*constructor)(void *),
void (*destructor)(void *, char)
)
- constructor是class的default constructor的函数指针
- destructor是class的default destructor的函数指针
- array持有的若不是具名数组(本例中为knots)的地址, 就是0. 如果是0, 那么数组将经由应用程序的new运算符, 被动态配置于heap中
- 在vec_new()中, constructor施行于elem_cout个元素之上
下面是编译器可能对10个Point元素所做的vec_new()调用操作:
Point knots[10];
vec_new(&knots, sizeof(Point), 10, &Point::Point, 0);
如果Point也定义了一个destructor, 当knots的生命结束时, 该destructor也必须是施行于那10个Point元素身上. 这是经由一个类似的vec_delete()(或是一个vec_vdelete(), 如果classes拥有virtual base classes的话)的runtime library函数完成, 函数类型如下:
void* vec_delete(
void *array,
size_t elem_size,
int elem_count,
void (*destructor)(void *, char)
)
如果程序员提供一个或多个明显初值给一个由class objects组成的数组, 像下面这样:
Point knots[10] = {
Point(),
Point(1.0, 1.0, 0.5),
-1.0
};
对于那些明显获得初值的元素, vec_new()不再有必要,对于那些尚未被初始化的元素, vec_new()的施行方式就行面对"由class elements组成的数组, 而该数组没有explicit initialization list"一样. 因此上一个定义很可能被转换为:
Point knots[10];
// C++伪码
// 显示地初始化前3个元素
Point::Point(&knots[0]);
Point::Point(&knots[1], 1.0, 1.0, 0.5);
Point::Point(&knots[2], -1.0, 0.0, 0.0);
// 以vec_new初始化后7个元素
vec_new(&knots+3, sizeof(Point), 7, &Point::Point, 0);
Default Constructors和数组
如果想要在程序中取出一个constructor的地址, 是不可以的. 当然, 这是在编译器支持vec_new()时该做的事情. 然而, 经由一个指针来启动constructor, 将无法(不被允许)存取default argument values
举个例子, 在cfront2.0之前, 声明一个由class objects所组成的数组, 意味着这个class必须没有声明constructs或一个default constructor(没有参数那种)----> 有还是没有一个default constructor(没有参数那种)???. 一个constructor不可以取一个或一个以上的默认参数值. 这违反直觉的, 会导致以下的大错
class complex {
complex(double = 0.0, double = 0.0);
};
在当时的语言规则下, 此复数函数库的使用者没办法声明一个由complex class objects组成的数组.
我的理解是在2.0版本之前, 这样带有默认参数的构造函数无法区分无参构造函数
然而在2.0版, 修改了语言本身, 为支持句子:complex::complex(double = 0.0, double = 0.0), 当程序员写出complex c_array[10]时, 而编译器最终需要调用vec_new(&c_array, sizeof(complex), 10, &complex::complex, 0);, 默认的参数如何能够对vec_new()而言有用?
cfront所采用的方法是产生一个内部的stub construct, 没有参数. 在其函数内调用由程序员提供的constructor, 并将default参数值显式地指定过去(由于construct的地址已经被取得, 所以它不能够成为一个inline):
// 内部产生的stub constructor
// 用以支持数组的构造
complex::complex() {
complex(0.0, 0.0);
}
编译器自己又一次违反了一个明显的语言规则: class如今支持了两个没有带参数的constructs. 当然, 只有class objects数组真正被产生出来时, stub实例才会被产生以及被使用
6.2 new和delete运算符
int *pi = new int(5);
实际上是由两个步骤完成:
(1) 通过适当的new运算符函数实例, 配置所需内存: int *pi = __new(sizeof(int));
(2) 将配置得来的对象设置初值: *pi = 5;
更进一步, 初始化操作应用在内存配置成功后才执行:
int *pi;
if (pi = __new(sizeof(int))) // (__new即下面会说到的operator new)
*pi = 5;
delete pi;
delete pi时, 如果pi是0, C++语言会要求delete运算符不要有操作. 因此"编译器"必须为此调用构造一层保护:
if (pi != 0)
__delete(pi); // (__delete即下面会说到的operator delete)释放内存, 但是pi并不会设为0
以constructor来配置一个class object:
Point3d *origin = new Point3d;
// 转换为:
// C++伪码
if (origin = __new(sizeof(Point3d)))
origin = Point3d::Point3d(origin);
// 出现exception handling情况:
// C+++伪码
if (origin = __new(sizeof(Point3d))) {
try {
origin = Point3d::Point3d(origin);
}
catch(...) {
// 调用delete library function以释放因new而配置的内存
__delete(origin);
// 将原来的exception上传
throw;
}
}
destructor的应用:
delete origin;
// 会变成
// C++伪码
if (origin != 0) {
Point3d::~Point3d(origin);
__delete(origin);
}
// 如果在exception handling的情况下, destructor应该被放在一个try区段中
// exception handler会调用delete运算符, 然后再一次抛出该exception
一般的library对于new运算符的实现操作都很直接了当, 担忧两个精巧之处值得斟酌(以下版本并未考虑exception handling):
extern void* operator new(size_t size) {
if (size == 0);
size = 1;
void *last_alloc;
while (!(last_alloc = malloc(size))) {
if (_new_handler)
(*_new_handler)();
else
return 0;
}
return last_alloc;
}
虽然new T[0]是合法的, 但语言要求每一次对new的调用都必须传回一个独一无二的指针. 解决此问题的传统方法是传回一个指针, 指向一个默认为1 byte的内存区块(这就是为什么上述代码中将size设为1的原因)
上述实现允许使用者提供一个属于自己的_new_handler()函数, 这正是为什么每一次循环都调用_new_handler()之故
new运算符实际上总是以标准的C malloc()完成, 虽然并没有规定一定得这么做不可. 相同情况, delete运算符也总是以标准C free()完成:
extern void operator delete(void *ptr) {
if (ptr) {
free((char *)ptr);
}
}
针对数组的new语意
int *p_array = new int[5];vec_new()不会真正被调用, 因为它的主要功能是把default constructor施行于class objects所组成的数组的每一个元素身上(这里并不需要调用constructor). 到是operatoror new会被调用:int *p_array = (int *)__new(5 * sizeof(int));
相同的情况, 如果写:
// struct simple_aggr{float f1, f2;};
simple_aggr *p_aggr = new simple_aggr[5];
vec_new也不会被调用. 因为simple_aggr并没有定义一个constructor或destructor, 所以配置数组以及清楚p_aggr数组的操作, 只是单纯地获得内存和释放内存而已. 由operator new和operator delete来完成绰绰有余
如果class定义了一个default constructor, 某些版本的vec_new()就会被调用, 配置并构造class objects所组成的数组, 例如:
Point3d *p_array = new Point3d[10];
// 通常会被编译为:
Point3d *p_array;
// 与前面的数组有区别, 前面在析构的地方传的是0, 这里是&Point3d::~Point3d
p_array = vec_new(0, sizeof(Point3d), 10, &Point3d, &Point3d::~Point3d);
在个别的数组元素构造过程中, 如果发生exception, destructor就会被传给vec_new(). 只有已经构造妥当的元素才需要destructor的施行, 因为它的内存已经被配置出来(所以这里析构位置不在为0?), vec_new()有责任在exception发生的时机把那些内存释放掉
当delete一个指向数组的指针时, C++2.0版之前, 需要提供数组的大小. 而2.1版后, 不需要提供数组大小, 只有在[]出现时, 编译器才寻找数组的维度. 否则它便假设只有单独一个object要被删除:
// 正确的代码应该是delete[] p_array;
delete p_array; // 只有第一个元素会被析构. 其他元素仍然存在, 虽然相关的内存已经被要求归还了
由于新近的编译器不提供数组大小, 那么如何记录数组的元素, 以便在delete[] arr;时使用?
(1) 一个明显的方法是为vec_new()所传回的每一个内存区块配置一个额外的word, 然后把元素个数包藏在这个word之中, 通常这种被包藏的数值称为cookie
(2) Jonathan和Sun编译器决定维护一个"联合数组", 放置指针及大小. Sun也把destructor的地址维护于此数组之中
cookie策略有一个普遍引起忧虑的话题, 如果一个坏指针被交给delete_vec(), 取出来的cookie自然是不合法的. 一个不合法的元素个数和一个坏指针的起始地址, 会导致destructor以非预期的次数被实施于一段非预期的区域. 然而在"联合数组"的策略下, 坏指针的可能结果就只是取出错误的元素个数而已
**避免一个base class指针指向一个derived class objects所组成的数组: **
Point *ptr = new Point3d[10];
实施于数组上的destructor, 是根据交给vec_delete()函数的"被删除的指针类型的destructor", 在本例中正是Point destructor, 并非所期望那样. 此外, 每一个元素的大小也一并被传递过去, 本例中是Point class object的大小, 而不是Point3d的大小. 这就是vec_delete()如何迭代走过每一个元素的方式. 因此整个过程失败了, 不只是因为执行了错误的destructor, 而且自若第一个元素之后, 该destructor即被施行于不正确的内存区块中(因为元素大小不对)
测试程序(执行结果与书上有出入):
#include <iostream>
using namespace std;
class base {
public:
base() { cout << "base constructor" << endl; }
virtual ~base() { cout << "base destructor" << endl; }
};
class derived : public base{
public:
derived() { cout << "derived constructor" << endl; }
virtual ~derived() { cout << "derived destructor" << endl; }
};
int main() {
base *arr = new derived[2];
delete[] arr;
/* 正确做法应该强制类型转换后delete, vs, g++都报错
for (int i = 0; i < 2; i++) {
derived *p = &((derived *)arr)[i];
delete p;
}
*/
return 0;
}
/* vs执行结果
base constructor
derived constructor
base constructor
derived constructor
derived destructor
base destructor
derived destructor
base destructor
请按任意键继续. . .
*/
/* g++执行结果
base constructor
derived constructor
base constructor
derived constructor
derived destructor
base destructor
derived destructor
base destructor
*/
/* 按书上的结果应该是
base constructor
derived constructor
base constructor
derived constructor
base destructor
base destructor
*/
Placement Operator new的语意
有一个预先定义好的重载的(overloaded)new运算符, 称为placement operator new. 它需要第二个参数, 类型为void *, 调用方式:Point2w *ptw = new(arena)Point2w;
其中arena指向内存中的一个区块, 用以放置新产生出来的Pioin2dw object. 这个预先定义好的placement operator new的实现方法简直是出乎意料的平凡. 它只要将"获得的指针(上面的arena)"所指的地址传回即可
详情略
6.3 临时性对象
如果有一个函数T operator+(const T&, const T&);, 分析下列3个语句产生的临时对象:
(1)T c = a + b;
(2)c = a + b;
(3)a + b;
对于T c = a + b;, 有三种方式获得c对象, C++标准允许编译器厂商有完全的自由度, 以下三种方式所获得的c对象结果都一样, 期间的差异在于初始化的成本:
- 编译器可以产生一个临时对象, 放置a+b的结果, 然后再使用T的copy constructor, 把该临时性对象当作C的初始值
- 编译器也可以直接以拷贝构造的方式, 将a+b的值放到c中(2.3节对于加法运算符的转换曾有讨论), 于是不需要临时对象, 以及对其constructor和destructor的调用
- 此外视operator+()的定义而定, NRV(named return value)优化也可能实施起来, 这将导致直接在上述c对象中求表达式结果, 避免执行copy constructor和具名对象(named object)的destructor
实际上, 由于市场竞争, 几乎包装任何表达式T c = a + b;背后的T operator+(const T&, const T&)或T T::operator+(const T&)的实现都不会产生一个临时对象
对于c = a + b, 不能忽略临时对象, 它将导致下面的结果:
// T temp = a + b;
T temp;
// c = tmep
c.operator+(temp);
temp.T::~T();
直接传递C到运算符函数中都是有问题的. 由于运算符函数并不为其外加参数调用一个destructor(它期望一块"新鲜的"内存), 所以必须在此调用之前先调用destructor
对于a + b;, 没有目标对象, 这时候有必要产生一个临时对象以外置运算后的结果. 这种情况在子表达式中十分普遍. 对这种情况下的一个问题时何时销毁临时对象, C++标准规定, 临时对象的被销毁, 应该是对完整表达式求值过程中的最后一个步骤, 该完整表达式造成临时对象的产生, 但是, 这个规则也存在2个例外:
- 发生在表达式被用来初始化一个object时, 此时object初始化完成后才销毁临时对象
bool verbose;
//...
String pogNameVersion = !verbose ? 0 : progName + progVersion;
如果在完整的"?:表达式"结束后就销毁临时的progName + progVersion对象, 那么就无法正确初始化progNameVersion
但是, 即使遵守这个规则, 程序员还是可能让一个临时对象在控制中被下偶hi, 最终初始化操作失败:
const char *progNameVersion = progName + progVersion;
产生的临时对象会调用转换函数转换为char*, 然后赋值给progNameVersion, 在初始化完成后, 临时对象的销毁会使得指针指向未定义的内存
2. "当一个临时对象被一个reference绑定"时, 临时对象应该在reference的生命结束后才销毁
const String &space = " ";
如果临时对象在初始化space后就销毁, 那么reference也就没用了
在类似
if (s + t || u + v)这种表达式中, 临时对象是根据程序的执行期语意, 有条件地被产生出来的, 如果把临时对象的destructor放进每一个子算式的求值过程中, 刻一个免除"努力追踪第二个子算式是否真的需要被评估". 然后现在C++标准以及要求这类表达式在整个完整表达式结束后才销毁对象, 因此某些形式的测试会被安插进来, 以决定是否要摧毁和第二算式有关的临时对象