R语言笔记文档
2019.11.24
R语言的安装
工作目录查看与更改
变量的三种赋值
如何查看R语言帮助 ? args
基础数据类型
基本数据类型 因子、数据框、数组、矩阵、列表、向量
2019.11.25 晚
读取数据
read.csv的属性
colname 取列名
sapply(q, class) ##得到每列的数据类型
取子集-向量
三种取子集 中括号 双中括号 $
三种索引方式 数字 逻辑 名字
对子集进行赋值
逻辑运算 与或非 & | !
向量跟向量之间合并成数据框
cbind rbind 组成矩阵
data.frame(a,b,stringsAsFactors = F)
去缺失值
complete.cases(x,y) #找到x,y两列中的是否有NA值,有返回F
na.omit() ##针对的是数据框有NA直接去掉
综合练习
取数据框中数学成绩大于60的数据
取数学、语文、英语都大于60的数据
将五个的数学和语文成绩改成60
q[q$Temp>90,]$Temp = q[q$Temp>90,]$Temp + 1000
创建一个列sum,求三科成绩 x$sum=x$数据+x$英语+x$语文
求总分跟均值的差 x$sum<-x$sum-mean(x$sum)
搜索路径的理解
search ##查看搜索路径
attach ##tach进第2个搜索路径中
detach
libray ##加载进第2个搜索路径中
detach("Package.woe")
with(airquality,hist(Ozone)) ##也是让你少写,第一个参数是指定你的数据框,第二个参数就不需要你指定数据框了
data() ##查看R语su言包含的可操作的数据是哪些
2019.11.26早
向量的运算 https://www.cnblogs.com/ljhdo/p/4421644.html
基本数据运算函数
创建随机数
#rnorm dnorm pnorm qnorm ##rdpq引导的一系列分布随机数
#set.seed() ##随机播种
#sample(letters,19,replace = T) #取19个随机数,放回抽取
日期和时间 https://www.cnblogs.com/ljhdo/p/4804113.html
一,系统当前的日期和时间
sys.Date() sys.time() date()
二,把文本解析成日期和时间
as.Date(x,format) strptime(x,format,tz="") as.POSIXct()
三,把日期和时间格式化为文本
format(today,format='%Y-%m-%d')
strftime(today,format='%Y-%m-%d')格式化日期
四,日期的比较
1,时间和数字相加
2,时间比较 t2时间大t1
difftime(t2,t1,units = "year")
3,时间序列
seq(t3,by="2 month",length.out=12)
seq(t1,t3,"year")
五,泛时间函数
weekdays()
months() ##一年的第几月
quarters()
字符处理
链接字符 paste("cc","qq",sep="&") 属性:sep是作用于向量之间、collapse是作用于向量内部的
分割字符 strsplit(c,"d")-->返回的是list 属性:fixed = T 表达是固定模式,不采用正则表达
抽取[替换]字符 substr("eeqeqq",2,4)<-"ss"
替换字符 chartr sub gsub
匹配字符
grep("er",x) grepl("er",x) ##返回的是单元格
regexpr("er",x) gregexpr("er",x) #返回的是匹配的位置
match(x,table,nomatch=NA_integer_) ##在一大堆的可选项,筛选出你想要的选项
1:10 %in% c(1,2,4,9) ##实现的功能和上面一样的 !!很好用 很实用
2019.11.27
控制结构
判断语句
if(){}else{} 这里
ifelse(rbinom(10,1,0,5),yes='字',no='花')
loan = c("A","B","D","C","C","B","A","B","A","D")
ifelse(loan=="B",NA,ifelse(loan=="D","否","是"))
循环语句
for () {}
循环嵌套
m = matrix(1:6,2,3)
for (i in 1:2) {
for (j in 1:3){
print(m[i,j])
}
}
无限循环 配合break
repeat一般不使用,偶尔会用到,适用无限逼近
next ,return
next可以用于如何一种循环,用来跳过某一次迭代,类似python-continue
return也可以退出循环,主要用于退出函数,会结束函数,返回一个值
9*9乘法表
1:9 %*% t(1:9)
t(1:9),原本是9行一列,转置就变成了1行9列
会将前面也变成矩阵
2019.11.28
函数 关键字:function
函数的嵌套
循环函数
lapply:针对的是列表,中的每个元素,对输出不简化
lapply(x,mean)
sapply:针对的是列表,中的每个元素,对输出简化
lapply(x,colmean)
quantile(1:10,probs = c(0,1)) 求分位数
apply(x,方向,函数):针对的是数据框或者数组
rowMeans()-->apply(x,1,mean)
rowSums()-->apply(x,1,sum)
colMeans()-->apply(x,2,mean)
colSums()-->apply(x,2,mean)
数组是:2*3*4的数据,apply(x,c(1:2),mean)
返回的数据就是2*3的数据,是对边界的高进行压缩
tapply:针对的是向量
tapple(x,Index,fun)
Index:是对向量x进行分组,然后执行fun函数
q=c(1:10,11:20)
tapply(q,gl(2,10),mean)
split:针对的是数据框,进行分组,输出list
split(x,f,drop=T) 参数三是否要去掉空等级
qq = airquality
lair = split(qq,qq$Month)
sapply(lair,colMeans,na.rm=T) ##colmean是用于数据框的
interaction()## 对向量向量取交集
数据的清洗
排序
sort() ##输出数值
order() ##输出升序的数值所对应索引值
x[order[x]] = 可以用在数据框中使用
arrange(qq,desc(qq$math),qq$eng)
##需要安装plyr 数据按math降序排序,再按eng升序排序
分箱 install("Hmsic")
自定义分箱
等宽分箱 --》区间是范围一样
cut(x,3,label=c()) ##将数据等宽分成3部分,label设置标签,include.lowest=T --》切割点包含最小值
等深分箱 --》区间中的包含的数据一样
cut2(x,m=3) ##将数据等深分成三部分
excel的使用
外部包 openxlsx
read.xlsx("文件名",sheet) ##sheet可以采用数字页,或者页的文件名字
convertToDateTime(x2$x1) ##读文件,日期格式会变成数值,采用这个进行转换成日期格式
sql语句的汇总
sinfo = data.frame(id=1:4,name=c("hmm","cc","qq","bbc"))
smath = data.frame(id1=1:3,math=94:92)
seng = data.frame(id=1:5,math1=94:90)
##链接表的几种方式
rbind(seng,smath) ##要求的是列名字都相同
#外部包sqldf sql语句
library(sqldf)
sqldf("select * from sinfo,smath") ##笛卡尔乘积
sqldf("select * from sinfo union all select * from smath") ##union链接表,列要相同
sqldf("select * from sinfo left join smath on sinfo.id=smath.id") #left join
sqldf("select * from sinfo except select * from smath") ##表1 - 表2
##内部包dpldr
merge(sinfo,smath,by.x = "id",by.y = "id1")
merge(sinfo,seng,by = "id")
merge(sinfo,seng,by = "id",all=T) ##all全链接,和left join一样
##外部包dplyr
library(dplyr)
inner_join(sinfo,smath,by=c("id1","id"))
维度转换 --》外部包library(reshape2)
二维转一维
melt(soce,id.vars = c("id","name","math","eng"),measure.vars = c("math","eng"))
一维转二维
dcast(q,id+name+math~variable,value.var = "value")
dcast(qq,sex~variable,value.var = "value")
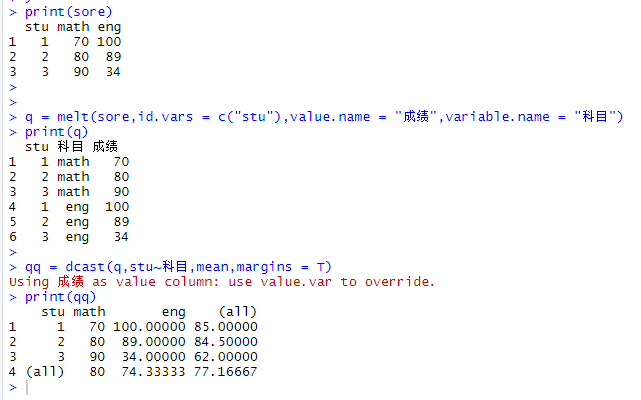
library(reshape2)
sore = data.frame(
stu = c(1,2,3),
math = c(70,80,90),
eng =c(100,89,34)
)
print(sore)
q = melt(sore,id.vars = c("stu"),value.name = "成绩",variable.name = "科目")
print(q)
qq = dcast(q,stu~科目,mean,margins = T)
print(qq)
删除变量
rm()删除变量
ls()查看全局变量有哪些
rm(list=ls())删除全部的全局变量