1: pointer network
Pointer Network是seq2seq模型的一个变种。他们不是把一个序列转换成另一个序列, 而是产生一系列指向输入序列元素的指针。最基础的用法是对可变长度序列或集合的元素进行排序。
传统的seq2seq模型是无法解决输出序列的词汇表会随着输入序列长度的改变而改变的问题的。在某些任务中,输入严格依赖于输入,或者说输出只能从输入中选择。例如输入一段话,提取这句话中最关键的几个词语。又或是输入一串数字,输出对这些数字的排序。这时如果使用传统seq2seq模型,则忽略了输入只能从输出中选择这个先验信息,Pointer Networks正是为了解决这个问题而提出的。
指针网络是在Seq2Seq模型的基础上,将attention机制修改得来的。
从Sequence2Sequence模型说起
Seq2Seq模型:
Sequence2Sequence模型,它实现了把一个序列转换成另外一个序列的功能,并且不要求输入序列和输出序列等长。比较典型的如机器翻译。
seq2seq模型往往使用RNN来构建,如LSTM和GRU。RNN天生适合处理具有时序关系的序列。
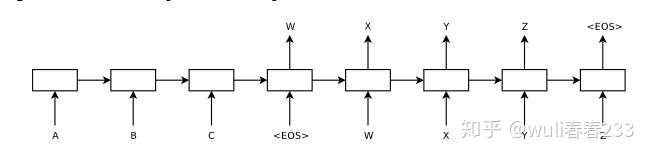 ABC—(Encoder)—语义编码C—(Decoder)—WXYZ
ABC—(Encoder)—语义编码C—(Decoder)—WXYZ
在这幅图中,模型把序列“ABC”转换成了序列“WXYZ”。分析其结构,我们可以把seq2seq模型分为encoder和decoder两个部分。encoder部分接收“ABC”作为输入,然后将这个序列转换成为一个中间向量C,向量C可以认为是对输入序列的一种编码。然后decoder部分,句子是一个个输出的,第一个元素的输出时把中间向量C作为自己的输入,第二个元素的输出是将中间向量C和第一个输出的元素一起作为输入,通过解码操作得到输出序列“WXYZ”。
公式描述如下:
用RNN做编码器和解码器,训练对( ,
)
Seq2Seq模型使用参数为 的RNN来计算条件概率
,以估计probability chain rule的项,这里
是n个向量的序列,
是
个索引的序列,
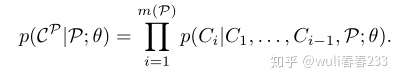 基于链式概率法则
基于链式概率法则
通过最大化训练集的条件概率来学习模型的参数,即(最大似然估计)
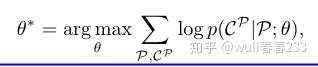 基于最大似然估计
基于最大似然估计
Seq2Seq模型使用参数为θ的RNN来计算条件概率,概率链式法则,通过最大化训练集的条件概率来学习模型的参数,即(最大似然估计)
如果我们输入的序列非常长,则该系统很容易性能会下降,因它会去处理整个句子,而造成前面的句子信息会被遗忘,attention机制应运而生。
Attention机制:
Attention Mechanism的加入使得seq2seq模型的性能大幅提升。那么Attention Mechanism做了些什么事呢?
Attention通常都是建立在Encoder-Decoder模型上来处理Seq2Seq的。
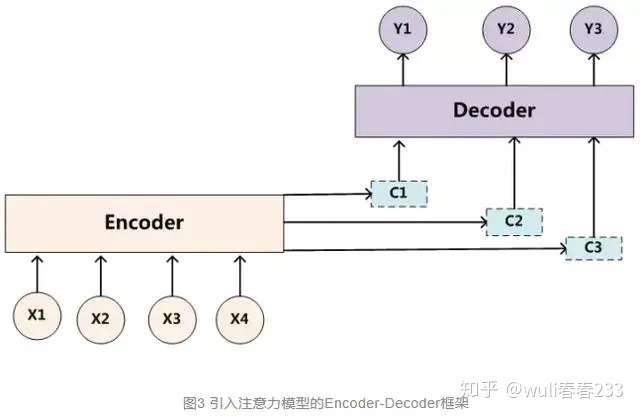
首先,将input sequences读入到一个encoder,生成的一个语言编码(Sequence Embedding)会作为decoder的已知条件,后面decoder每生成一个单词,都会参考这个固定的语言编码。
这存在一个问题,decoder生成一个单词的时候,应该将注意力重点放在那些影响这个单词的内容上,而不是一概将Input Sequence的embedding整体作为输出的参考,这会影响输出的准确性。Attention就是通过给input sequence分配不同的权重来决定每个单词的输出。
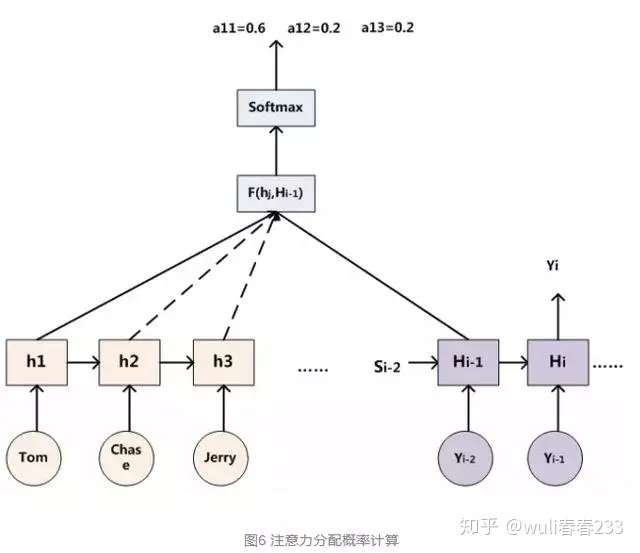
举例:
假设输入为一句英文的话:Tom chase Jerry
那么最终的结果应该是逐步输出 “汤姆”,“追逐”,“杰瑞”。
如果用传统Seq2Seq模型,那么在翻译Tom时,所有输入单词对翻译的影响都是相同的,但显然“汤姆”的贡献度应该更高。
引入attention后,每个单词都会有一个权重:(Tom,0.6)(Chase,0.2) (Jerry,0.2)
Attention机制公式描述:
将编码器和解码器对input sequence做embeddeing,分别定义为(e 1,...,e n)和(d 1,...,d m(P))而v,W 1和W 2是模型的可学习参数。
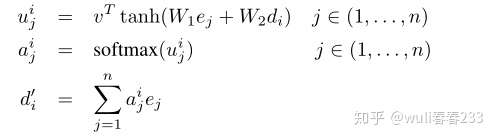 Attention机制三步骤:1.编码器和解码器对每个单词的embedding,做权重和之后输入到tanh激活函数,来求编码器和解码器的单词embedding的相似性 2.归一化 3.求权重和 . 求得的值就是attention权重。每当Decoder生成一个单词的时候,都会考虑不同权重的Input
Attention机制三步骤:1.编码器和解码器对每个单词的embedding,做权重和之后输入到tanh激活函数,来求编码器和解码器的单词embedding的相似性 2.归一化 3.求权重和 . 求得的值就是attention权重。每当Decoder生成一个单词的时候,都会考虑不同权重的Input
通过Attention Mechanism将encoder的隐状态和decoder的隐状态结合成一个中间向量C,然后使用decoder解码并预测,最后经由softmax层得到了针对词汇表的概率分布,从中选取概率最高的作为当前预测结果。
Pointer Network=Seq2Seq模型+Attention机制
指针网络:
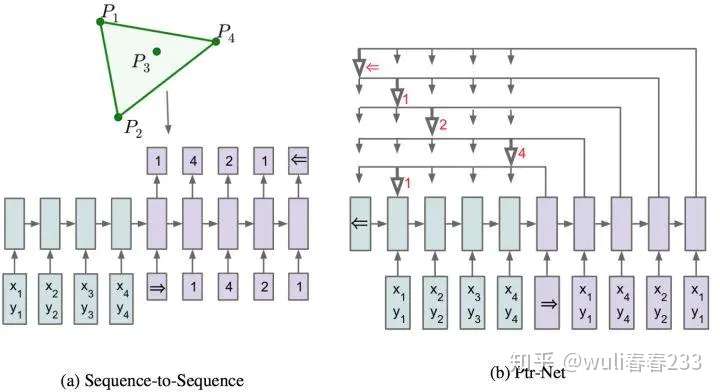
对注意力模型的非常简单的修改,用于解决输出序列的大小取决于输入序列中元素的数量这个问题。
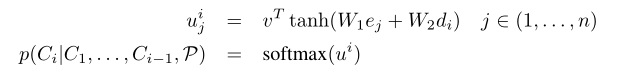 指针网络三步骤:1.编码器和解码器对每个单词做embedding,求其权重和之后输入到tanh激活函数,来求编码器和解码器的单词的embedding相似性 2.归一化 3.将前i-1个输出的单词和Attention权重作为条件概率,来生成第i个单词
指针网络三步骤:1.编码器和解码器对每个单词做embedding,求其权重和之后输入到tanh激活函数,来求编码器和解码器的单词的embedding相似性 2.归一化 3.将前i-1个输出的单词和Attention权重作为条件概率,来生成第i个单词
这种方法专门针对输出离散且与输入位置相对应的问题。
这种方法适用于可变大小的输入(产生可变大小的输出序列)
本质上,input Sequence里对生成第i个单词的影响(相似性,相关性)越大,权重就越大。
为啥叫pointer network呢?对于凸包的求解,就是从输入序列{P1,....,P1000}中选点的过程。选点的方法就叫pointer,他不像attetion mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
就像指针一样,ouput将指针(weight)指向对他影响最大的input序列。
这篇文章也解释的很通俗易通。
2: recursive神经网络
刚接触RNN的时候根本分不清recursive network和recurrent network,一个是递归神经网络,一个是循环神经网络,傻傻分不清。但是实际上,recursive network是recurrent network的一般形式。
如下图,我们以情感分析为例子,我们输入一个句子,判断这个句子的情感,是正面负面中性等等。在Recurrent Structure里面,句子会被表示成word vector,假如说情感有五类,最后输出的是一个五维向量。

那么如果用Recursive Structure,怎么去解决呢?在这里面,你需要先决定这四个input word
接下来我们将一个比较具体的例子:
假如我们现在要做情感分析,输入的句子是:not very good,machine要决定not very good是positive还是negative,首先先得到句子的文法结构,这不是我们这节课要讨论的;文法结构告诉我们very和good要先合并在一起,合起来的结果再跟not结合;然后我们要把输入向量(word embedding)输入到machine,接下来用函数,应用顺序和文法结构的结合顺序一致;假设word vector的维度是
的话,输入就是2个
,输出是
。

那么当我们组合这两个vector的时候,那么这个意思是不是"very good"的意思么?这里我们可能要用到神经网络,因为very good的vector不会简单地等于very的vector和good的vector的加和,显然不会是这么单纯的:“not”: neutral ,“good”: positive,加和的结果是中性的,然而“not good”: negative,因此不会是简单的加和。

所以我们需要一个神经网络来帮我们处理这个问题。我们希望是这个神经网络要能处理 not和good放一起变成负面的意思,machine要自动学到假设他看到not所代表的vector,自动反转另一个输入的情感;machine也要自动学到假设他看到very所代表的vector,自动强调另一个输入的情感等等诸如此类。函数
透过training data自动学习出来的:

那么函数

最简单的就是上图上半部分所示:把蓝色和黄色向量串联起来,乘以一个权重矩阵
因此我们改装成下半部分的样子:加号后面就是上半部分的内容,加号前面是两次运算,权重矩阵不一样,得到情感。
注意:后面还是传统的做法,但是前面加上了一个vector。这个vector的元素就是来学习这些词之间的interaction,然后将这些interaction变成bias,因为recursive network的function都是不变的,因此这些bias就这样被传递下去了。那么这里有一个需要注意的就是,我们这里有几个词,那我们就需要多少个bias,而且每个bias中间的这个矩阵W都是不一样的。
如下图是实验结果:

接下来,他有很多版本:比如下一个 Matrix-Vector Recursive Network
这个模型设计的想法就是:

还有Tree LSTM

这种recursive network模型还有很多应用:句子关联

Batch Normalization

转自:https://www.jianshu.com/p/f3ae607d9969