1.移动端适配1px的问题
解答:
(1)原因:
css中的1px并不等于移动设备的1px,这些由于不同的手机有不同的像素密度。在window对象中有一个devicePixelRatio属性,他可以反应css中的像素与设备的像素比。
devicePixelRatio的官方的定义为:设备物理像素和设备独立像素的比例,也就是 devicePixelRatio = 物理像素 / 独立像素。
关于devicePixelRatio的详细介绍可以参考张鑫旭的这篇博文,http://www.zhangxinxu.com/wordpress/2012/08/window-devicepixelratio/
(2)解决方法:
a:0.5px边框
IOS8下已经支持带小数的px值, media query 对应 devicePixelRatio 有个查询值 -webkit-min-device-pixel-ratio, css可以写成这样
通过-webkit-min-device-pixel-ratio设置。
.border { border: 1px solid #999 } @media screen and (-webkit-min-device-pixel-ratio: 2) { .border { border: 0.5px solid #999 } } @media screen and (-webkit-min-device-pixel-ratio: 3) { .border { border: 0.333333px solid #999 } }
如果使用less/sass的话只是加了1句mixin
缺点: 安卓与低版本IOS不适用, 这个或许是未来的标准写法, 现在不做指望
b.viewport + rem 实现
同时通过设置对应viewport的rem基准值,这种方式就可以像以前一样轻松愉快的写1px了。
在devicePixelRatio = 2 时,输出viewport:
<meta name="viewport" content="initial-scale=0.5, maximum-scale=0.5, minimum-scale=0.5, user-scalable=no">
<meta name="viewport" content="initial-scale=0.3333333333333333, maximum-scale=0.3333333333333333, minimum-scale=0.3333333333333333, user-scalable=no">
c.使用border-image实现
准备一张符合你要求的border-image:

.border-bottom-1px { border-width: 0 0 1px 0; -webkit-border-image: url(linenew.png) 0 0 2 0 stretch; border-image: url(linenew.png) 0 0 2 0 stretch; }
上文是把border设置在边框的底部,所以使用的图片是2px高,上部的1px颜色为透明,下部的1px使用视觉规定的border的颜色。如果边框底部和顶部同时需要border,可以使用下面的border-image:

.border-image-1px { border-width: 1px 0; -webkit-border-image: url(linenew.png) 2 0 stretch; border-image: url(linenew.png) 2 0 stretch; }
d.使用background-image实现
background-image 跟border-image的方法一样,你要先准备一张符合你要求的图片。然后将边框模拟在背景上。
样式设置:
.background-image-1px { background: url(../img/line.png) repeat-x left bottom; -webkit-background-size: 100% 1px; background-size: 100% 1px; }
e.使用box-shadow模拟边框
利用css 对阴影处理的方式实现0.5px的效果
.box-shadow-1px { box-shadow: inset 0px -1px 1px -1px #c8c7cc; }
f.伪类 + transform 实现
对于老项目,有没有什么办法能兼容1px的尴尬问题了,个人认为伪类+transform是比较完美的方法了。
原理是把原先元素的 border 去掉,然后利用 :before 或者 :after 重做 border ,并 transform 的 scale 缩小一半,原先的元素相对定位,新做的 border 绝对定位。
单条border样式设置:
.scale-1px{ position: relative; border:none; } .scale-1px:after{ content: ''; position: absolute; bottom: 0; background: #000; width: 100%; height: 1px; -webkit-transform: scaleY(0.5); transform: scaleY(0.5); -webkit-transform-origin: 0 0; transform-origin: 0 0; }
四条boder样式设置:
.scale-1px{ position: relative; margin-bottom: 20px; border:none; } .scale-1px:after{ content: ''; position: absolute; top: 0; left: 0; border: 1px solid #000; -webkit-box-sizing: border-box; box-sizing: border-box; width: 200%; height: 200%; -webkit-transform: scale(0.5); transform: scale(0.5); -webkit-transform-origin: left top; transform-origin: left top; }
最好在使用前也判断一下,结合 JS 代码,判断是否 Retina 屏:
if(window.devicePixelRatio && devicePixelRatio >= 2){ document.querySelector('ul').className = 'scale-1px'; }
2.如何解决跨域的问题
1. JSONP
利用 <script> 标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的 JSON 数据。JSONP 请求一定需要对方的服务器做支持才可以。
JSONP 优点是简单兼容性好,可用于解决主流浏览器的跨域数据访问的问题。缺点是仅支持 get 方法具有局限性,不安全可能会遭受 XSS 攻击。
2.cors
CORS 需要浏览器和后端同时支持。IE 8 和 9 需要通过 XDomainRequest 来实现。
浏览器会自动进行 CORS 通信,实现 CORS 通信的关键是后端。只要后端实现了 CORS,就实现了跨域。
服务端设置 Access-Control-Allow-Origin 就可以开启 CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
虽然设置 CORS 和前端没什么关系,但是通过这种方式解决跨域问题的话,会在发送请求时出现两种情况,分别为简单请求和复杂请求。
3.postMessage
postMessage 是 HTML5 XMLHttpRequest Level 2 中的 API,且是为数不多可以跨域操作的 window 属性之一,它可用于解决以下方面的问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的 iframe 消息传递
- 上面三个场景的跨域数据传递
postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
otherWindow.postMessage(message, targetOrigin, [transfer]);
- message: 将要发送到其他 window 的数据。
- targetOrigin:通过窗口的 origin 属性来指定哪些窗口能接收到消息事件,其值可以是字符串"*"(表示无限制)或者一个 URI。在发送消息的时候,如果目标窗口的协议、主机地址或端口这三者的任意一项不匹配 targetOrigin 提供的值,那么消息就不会被发送;只有三者完全匹配,消息才会被发送。
- transfer(可选):是一串和 message 同时传递的 Transferable 对象. 这些对象的所有权将被转移给消息的接收方,而发送一方将不再保有所有权。
4.Websocket
Websocket 是 HTML5 的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。WebSocket 和 HTTP 都是应用层协议,都基于 TCP 协议。但是 WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据。同时,WebSocket 在建立连接时需要借助 HTTP 协议,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了。
原生 WebSocket API 使用起来不太方便,我们使用Socket.io,它很好地封装了 WebSocket 接口,提供了更简单、灵活的接口,也对不支持 WebSocket 的浏览器提供了向下兼容。
5. Node 中间件代理(两次跨域)
实现原理:同源策略是浏览器需要遵循的标准,而如果是服务器向服务器请求就无需遵循同源策略。
代理服务器,需要做以下几个步骤:
- 接受客户端请求 。
- 将请求转发给服务器。
- 拿到服务器响应数据。
- 将响应转发给客户端。
6.nginx 反向代理
实现原理类似于 Node 中间件代理,需要你搭建一个中转 nginx 服务器,用于转发请求。
使用 nginx 反向代理实现跨域,是最简单的跨域方式。只需要修改 nginx 的配置即可解决跨域问题,支持所有浏览器,支持 session,不需要修改任何代码,并且不会影响服务器性能。
实现思路:通过 nginx 配置一个代理服务器(域名与 domain1 相同,端口不同)做跳板机,反向代理访问 domain2 接口,并且可以顺便修改 cookie 中 domain 信息,方便当前域 cookie 写入,实现跨域登录。
7.window.name + iframe
window.name属性的独特之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
8.location.hash + iframe
实现原理: a.html 欲与 c.html 跨域相互通信,通过中间页 b.html 来实现。 三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js 访问来通信。
具体实现步骤:一开始 a.html 给 c.html 传一个 hash 值,然后 c.html 收到 hash 值后,再把 hash 值传递给 b.html,最后 b.html 将结果放到 a.html 的 hash 值中。
9.document.domain + iframe
该方式只能用于二级域名相同的情况下,比如 a.test.com 和 b.test.com 适用于该方式。
只需要给页面添加 document.domain ='test.com' 表示二级域名都相同就可以实现跨域。
实现原理:两个页面都通过 js 强制设置 document.domain 为基础主域,就实现了同域。
3.路由的动态加载
在Vue项目中,一般使用vue-cli构建项目后,我们会在Router文件夹下面的index.js里面引入相关的路由组件,如:
import Hello from '@/components/Hello' import Boy from '@/components/Boy' import Girl from '@/components/Girl'
这样做的结果就是webpack在npm run build的时候会打包成一个整个的js文件,如果页面一多,会导致这个文件非常大,加载缓慢,为了解决这个问题,需要将他分成多个小文件,而且还要实现异步按需加载,即用到了再加载,而不用一股脑全部加载。
1.webpack提供的require.ensure(),这样可以实现按需加载,并且你可以将多个相同类的组件打包成一个文件,只要给他们指定相同的chunkName即可,如示例中的demo将会打包成一个文件。
{ path: '/promisedemo', name: 'PromiseDemo', component: r => require.ensure([], () => r(require('../components/PromiseDemo')), 'demo')},{ path: '/hello', name: 'Hello', // component: Hello component: r => require.ensure([], () => r(require('../components/Hello')), 'demo')} |
2.Vue的异步组件技术,这种方法可以实现按需加载,并且一个组件会打包成一个js文件
{ path: '/promisedemo', name: 'PromiseDemo', component: resolve => require(['../components/PromiseDemo'], resolve) } |
3.es提案的import(),也是我推荐的方法
首先,可以将异步组件定义为返回一个 Promise 的工厂函数 (该函数返回的 Promise 应该 resolve 组件本身):
const Foo = () => Promise.resolve({ /* 组件定义对象 */ }) |
第二,在 Webpack 2 中,我们可以使用动态 import语法来定义代码分块点 (split point):
import('./Foo.vue') // 返回 Promise |
注意:如果您使用的是 Babel,你将需要添加 syntax-dynamic-import 插件,才能使 Babel 可以正确地解析语法。
结合这两者,这就是如何定义一个能够被 Webpack 自动代码分割的异步组件。
const Foo = () => import('./Foo.vue') |
const Foo = () => import(/* webpackChunkName: "group-foo" */ './Foo.vue') |
4.怎么实现对象的深拷贝
/* this的使用:在预编译的过程this指向是window 在全局作用域里this指向是window call/apply 改变this的指向 obj.function();function()里面的this指向的是obj */var obj = { a: function () { console.log(this.name) }, name: '123'}obj.a(); //谁调用这个方法this指向谁,没用调用就是预编译var foo = 123;function print() { this.foo = 234; console.log(foo);}/*print();*/ //234new print(); //123/* arguments.callee:指向函数的引用,也就是它本身 */var num = (function (n) { if (n == 1) { return 1; } else { return n * arguments.callee(n - 1); }}(10))/*深层拷贝*//* 遍历对象 for (var prop in obj) 1:判断是不是原始值 typeof() 2:判断是数组还是对象 3:判断相应的数组和对象 */var obj = { name: 'tom', age: 23, son: {}, wife: ['sss', 'ddd']}function deepClone(origin, target) { //容错 var target = target || {}, toStr = Object.prototype.toString(), arrStr = "[Object Array]"; for (var prop in origin){ if (origin.hasOwnProperty(prop)){ if (origin[prop] !== 'null' && typeof (origin[prop]) == 'object'){ if ( toStr.call(origin[prop]) == arrStr){ target[prop]= []; }else { target[prop] ={}; } deepClone(origin[prop],target[prop]); }else { target[prop] == origin[prop]; } } }} |
5.什么叫优雅降级和渐进增强
优雅降级:
Web站点在所有新式浏览器中都能正常工作,如果用户使用的是老式浏览器,则代码会检查以确认它们是否能正常工作。由于IE独特的盒模型布局问题,针对不同版本的IE的hack实践过优雅降级了,为那些无法支持功能的浏览器增加候选方案,使之在旧式浏览器上以某种形式降级体验却不至于完全失效。
渐进增强:
从被所有浏览器支持的基本功能开始,逐步地添加那些只有新式浏览器才支持的功能,向页面增加无害于基础浏览器的额外样式和功能的。当浏览器支持时,它们会自动地呈现出来并发挥作用。
.transition { /*渐进增强写法*/ -webkit-transition: all .5s; -moz-transition: all .5s; -o-transition: all .5s; transition: all .5s;}.transition { /*优雅降级写法*/ transition: all .5s; -o-transition: all .5s; -moz-transition: all .5s; -webkit-transition: all .5s;} |
前缀CSS3(-webkit- / -moz- / -o-*)和正常的 CSS3 在浏览器中的支持情况是这样的:
- 很久以前:浏览器前缀CSS3和正常的CSS3都不支持。
- 不久以前:浏览器只支持前缀CSS3,不支持正常CSS3。
- 现在:浏览器既支持前缀CSS3,又支持CSS3。
- 未来:浏览器不支持前缀CSS3,仅支持正常CSS3。
注意: css中需要知道的是 - 如果属性不可用,则不发挥任何作用,无影响;如果属性是相同的作用,则后者会覆盖前者。
渐进增强的写法,优先考虑老版本浏览器的可用性,最后才考虑新版本浏览器的可用性。
而优雅降级的写法,优先考虑新版本浏览器的可用性,最后才考虑浏览器的可用性。
就CSS3来说,我们更加推荐渐进增强的写法。
6.promise、async有什么区别(对async、await的理解,内部原理、介绍下Promise,内部实现)
7.介绍AST(Abstract Syntax Tree)抽象语法树
8.什么是防抖和节流?有什么区别?如何实现?
防抖
触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间
思路:
每次触发事件时都取消之前的延时调用方法
function debounce(fn) { let timeout = null; // 创建一个标记用来存放定时器的返回值 return function () { clearTimeout(timeout); // 每当用户输入的时候把前一个 setTimeout clear 掉 timeout = setTimeout(() => { // 然后又创建一个新的 setTimeout, 这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数 fn.apply(this, arguments); }, 500); }; } function sayHi() { console.log('防抖成功'); } var inp = document.getElementById('inp'); inp.addEventListener('input', debounce(sayHi)); // 防抖 |
节流
高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率
思路:
每次触发事件时都判断当前是否有等待执行的延时函数
function throttle(fn) { let canRun = true; // 通过闭包保存一个标记 return function () { if (!canRun) return; // 在函数开头判断标记是否为true,不为true则return canRun = false; // 立即设置为false setTimeout(() => { // 将外部传入的函数的执行放在setTimeout中 fn.apply(this, arguments); // 最后在setTimeout执行完毕后再把标记设置为true(关键)表示可以执行下一次循环了。当定时器没有执行的时候标记永远是false,在开头被return掉 canRun = true; }, 500); }; } function sayHi(e) { console.log(e.target.innerWidth, e.target.innerHeight); } window.addEventListener('resize', throttle(sayHi)); |
9.vue-router有哪几种导航钩子
- 全局导航钩子
- router.beforeEach(to, from, next),
- router.beforeResolve(to, from, next),
- router.afterEach(to, from ,next)
- 组件内钩子
- beforeRouteEnter,
- beforeRouteUpdate,
- beforeRouteLeave
- 单独路由独享组件
- beforeEnter
10.Vue的双向数据绑定原理是什么?
vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty()来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
具体步骤:
第一步:需要 observe 的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter 和 getter 这样的话,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了数据变化
第二步:compile 解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
第三步:Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁,主要做的事情是:
- 在自身实例化时往属性订阅器(dep)里面添加自己
- 自身必须有一个 update()方法
- 待属性变动 dep.notice()通知时,能调用自身的 update() 方法,并触发 Compile 中绑定的回调,则功成身退。
第四步:MVVM 作为数据绑定的入口,整合 Observer、Compile 和 Watcher 三者,通过 Observer 来监听自己的 model 数据变化,通过 Compile 来解析编译模板指令,最终利用 Watcher 搭起 Observer 和 Compile 之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据 model 变更的双向绑定效果。
11.请详细说下你对vue生命周期的理解?
总共分为 8 个阶段创建前/后,载入前/后,更新前/后,销毁前/后。
- 创建前/后: 在 beforeCreate 阶段,vue 实例的挂载元素 el 还没有。
- 载入前/后:在 beforeMount 阶段,vue 实例的$el 和 data 都初始化了,但还是挂载之前为虚拟的 dom 节点,data.message 还未替换。在 mounted 阶段,vue 实例挂载完成,data.message 成功渲染。
- 更新前/后:当 data 变化时,会触发 beforeUpdate 和 updated 方法。
- 销毁前/后:在执行 destroy 方法后,对 data 的改变不会再触发周期函数,说明此时 vue 实例已经解除了事件监听以及和 dom 的绑定,但是 dom 结构依然存在
12.客户端存储
1.常用的客户端存储方法有哪些?
平时前端开发中用到最多的是cookie、sessionStorage、localStorage,也有少量的业务场景会使用indexedDB。
2.cookie、sessionStorage 和 localStorage的区别
存储时效来说:
- cookie可以手动设置失效期,默认为会话级
- sessionStorage的存储时长是会话级
- localStorage的存储时长是永久,除非用户手动利用浏览器的工具删除
访问的局限性:
- cookie可以设置路径path,所有他要比另外两个多了一层访问限制
- localStorage和sessionStorage的访问限制是文档源级别,即协议、主机名和端口
- 还要注意的是,cookie可以通过设置domain属性值,可以不同二级域名下共享cookie,而Storage不可以,比如http://image.baidu.com的cookie http://map.baidu.com是可以访问的,前提是Cookie的domain设置为".http://baidu.com",而Storage是不可以的(这个很容易实验,就不细说了)
存储大小限制:
- cookie适合存储少量数据,他的大小限制是个数进行限制,每个浏览器的限制数量不同
- Storage的可以存储数据的量较大,此外他是通过占用空间大小来做限制的,每个浏览器的实现也是不同的,大家可以看这篇文章来进一进步了解Web Storage Support Test
操作方法:
- cookie是作为document的属性存在,并没有提供标准的方法来直接操作cookie
- Storage提供了setItem()和getItem()还有removeItem()方法,操作方便不易出错
其他:
- cookie在发送http请求时,会将本地的cookie作为http头部信息传递给服务器
- cookie可以由服务器通过http来设定
3.cookie由哪些部分组成?
除了基础的键值对外,cookie还有下面的属性:
- Expires :cookie最长有效期
- Max-Age:在 cookie 失效之前需要经过的秒数。(当Expires和Max-Age同时存在时,文档中给出的是已Max-Age为准,可是我自己用Chrome实验的结果是取二者中最长有效期的值)
- Domain:指定 cookie 可以送达的主机名。
- Path:指定一个 URL 路径,这个路径必须出现在要请求的资源的路径中才可以发送 Cookie 首部
- Secure:一个带有安全属性的 cookie 只有在请求使用SSL和HTTPS协议的时候才会被发送到服务器。
- HttpOnly:设置了 HttpOnly 属性的 cookie 不能使用 JavaScript 经由
Document.cookie属性、XMLHttpRequest和RequestAPIs 进行访问,以防范跨站脚本攻击(XSS)。
4.如何用原生JS方法来操作cookie
上面已经说过了,在浏览器中cookie做为document的一个属性存在,并没有提供原生的操作方法,并且所有形式都以字符串拼接的形式存储,需要开发利用字符串操作的方法来操作document.cookie,从而达到操作客户端cookie的目的。
想操作cookie,必须知道document.cookie中存储的字符串是怎样的结构。
document.cookie返回的结构大概如下面的样子:
name1=value1; name2=value2; name1=value3
即:document.cookie返回当前页面可用的(根据cookie的域、路径、失效时间和安全设置)所有cookie的字符串,一系列由分号隔开的名值对儿。
当想设置cookie时,可以直接对document.cookie赋值,对document.cookie赋值并不会覆盖掉cookie,除非设置的cookie已经存在。设置cookie的格式如下,和Set-Cookie头中的使用的格式是一样的。
name=value; expires=expiration_time; path=domain_path; domain=domain_name; secure
上面这些参数中,只有cookie中的名字和值是必须的。下面是一个简单的例子:
document.cookie = 'name=Roy';
此外,需要注意的是设置值时需要对于属性和值都用encodeURIComponent()来保证它不包含任何逗号、分号或空格(cookie值中禁止使用这些值).
5.在Hybrid环境下(混合应用),使用客户端存储应该注意哪些?
在混合应用中,主要是注意会话级存储——sessionStorage。
因为混合应用中的webview从一个页面跳转的另一个页面时,会话并没有像浏览器中那样是继承延续的,也就是说,当在A页面中设置的了sessionStorage值后跳转的下一个页面时,这是sessionStorage是全新的,根本获取不到A页面中设置的任何sessionStorage。
所以如果你们的app开发者还没有解决这个问题的话,建议这时使用session级别的cookie来代替sessionStorage,因为cookie是可以跨标签访问的,不要会话连续。
6.sessionStorage和localStorage存储的数据类型是什么?
sessionStorage和localStorage只能存储字符串类型的数据,如果setItem()方法传入的数据不是字符串的话,会自动转换为字符串类型再进行存储。所以在存储之前应该使用JSON.stringfy()方法先进行一步安全转换字符串,取值时再用JSON.parse()方法再转换一次。
7.session级存储中,session cookie和sessionStorage有哪些区别?
详细的分析可以看我之前的文章——同样是客户端会话级存储,sessionStorage和session cookie有什么?
大体的概括就是说:
- sessionStorage的会话基于标签,即标签关闭则会话终止,而cookie基于浏览器进程。
- sessionStorage的访问必须基于会话继承和延续,即只有在当前标签下或当前标签打开的标签下可以访问sessionStorage中的数据,而cookie是可以跨标签进行访问的。
13.前端路由的模式有几种
1.history 模式
HTML5规范提供了history.pushState和history.replaceState来进行路由控制。通过这两个方法可以改变url且不向服务器发送请求。同时不会像hash有一个#,更加的美观。但是history路由需要服务器的支持,并且需将所有的路由重定向倒根页面。
已经有 hash 模式了,而且 hash 能兼容到IE8, history 只能兼容到 IE10,为什么还要搞个 history 呢?
首先,hash 本来是拿来做页面定位的,如果拿来做路由的话,原来的锚点功能就不能用了。其次,hash 的传参是基于 url 的,如果要传递复杂的数据,会有体积的限制,而 history 模式不仅可以在url里放参数,还可以将数据存放在一个特定的对象中。
vue-router默认hash模式,使用 URL 的 hash 来模拟一个完整的 URL,于是当 URL 改变时,页面不会重新加载。
不过这种模式要玩好,还需要后台配置支持。因为我们的应用是个单页客户端应用,如果后台没有正确的配置,当用户在浏览器直接访问 http://oursite.com/user/id 就会返回 404,这就不好看了。
所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个index.html 页面,这个页面就是你 app 依赖的页面。
相关API:
window.history.pushState(state, title, url) // state:需要保存的数据,这个数据在触发popstate事件时,可以在event.state里获取 // title:标题,基本没用,一般传 null // url:设定新的历史记录的 url。新的 url 与当前 url 的 origin 必须是一樣的,否则会抛出错误。url可以是绝对路径,也可以是相对路径。 //如 当前url是 https://www.baidu.com/a/,执行history.pushState(null, null, './qq/'),则变成 https://www.baidu.com/a/qq/, //执行history.pushState(null, null, '/qq/'),则变成 https://www.baidu.com/qq/ window.history.replaceState(state, title, url) // 与 pushState 基本相同,但她是修改当前历史记录,而 pushState 是创建新的历史记录 window.addEventListener("popstate", function() { // 监听浏览器前进后退事件,pushState 与 replaceState 方法不会触发 }); window.history.back() // 后退 window.history.forward() // 前进 window.history.go(1) // 前进一步,-2为后退两步,window.history.lengthk可以查看当前历史堆栈中页面的数量
2.hash 模式
这里的hash是指url尾巴后的#号及后面的字符。这里的#和css里的#是一个意思。hash也称作锚点,本身是用来做页面定位的,她可以使对应id的元素显示在可是区域内。由于hash值变化不会导致浏览器向服务器发出请求,而且hash改变会触发hashchange事件,浏览器的进后退也能对其进行控制,所以人们在 html5 的 history 出现前,基本都是使用 hash 来实现前端路由的。
改变#不触发网页加载
http://www.example.com/index.html#location1 // 改成 http://www.example.com/index.html#location
浏览器不会重新向服务器请求index.html
使用到的api:
window.location.hash = 'qq' // 设置 url 的 hash,会在当前url后加上 '#qq' var hash = window.location.hash // '#qq' window.addEventListener('hashchange', function(){ // 监听hash变化,点击浏览器的前进后退会触发 })
14.flex布局
参考链接: https://blog.csdn.net/weixin_34206899/article/details/87992902
参考链接: https://www.jianshu.com/p/b591eee50568
15.原型链
1.什么是构造函数
构造函数的本质是一个普通函数,他的特点是需要通过new关键字来调用,用来创建对象的实例。所有的引用类型,如[],{},function等都是由构造函数实例化而来。一般首字母大写。
解析:首字母大写只是约定俗成的规范。首字母小写的函数也可以用作构造函数。
2.什么是原型和原型链
原型模式是JS实现继承的一种方式。所有的函数都有一个prototype属性,通过new生成一个对象时,prototype会被实例化为对象的属性。所有的引用类型都有一个__proto__指向其构造函数的prototype。原型链的话,指的就是当访问一个引用类型时,如果本身没有这个属性或方法,就会通过__proto__属性在父级的原型中找,一级一级往上,直到最顶层为止。
解析:原型链最顶层Object的prototype的__proto__指向为null。
3.如何理解 constructor 属性
答:所有函数的原型对象都有一个constructor属性指向函数本身。
解析:实例化的对象可以通过[].__proto__.constructor获取到其构造函数。
4.描述new 操作符的执行过程
- 创建一个空对象。
- 将这个空对象的
__proto__指向构造函数的prototype。 - 将构造函数的
this指向这个对象。 - 执行构造函数中的代码。
5.如何判断一个变量是数组类型
答: 使用instanceof关键字 或者constructor属性。
解析:instanceof的原理是判断操作符左边对象的原型链上是否有右边构造函数的prototype属性。
关于构造函数和原型
构造函数:相当于java中“类”的存在,如原生JS中的Array, Function, String, Date等等,都是构造函数。例如new Date()通过new操作符进行调用,用来创建一个Date对象的实例。
一个便于理解的栗子,描述js通过原型模式实现继承的过程
function Animal (name) { // 构造函数 this.name = name } Animal.prototype.type = 'animal' // 原型上的属性和方法可以被继承 Animal.prototype.eat = function () { console.log('eat') } let dog = new Animal('忠犬八公') // 通过new 调用构造函数创建Animal的实例dog console.log(dog.name) // 输出:忠犬八公 console.log(dog.type) // 输出:animal dog.eat() // 输出:eat console.log(dog.__proto__) // 输出:{ type:'animal', eat: f, __proto__: ...} // dog.__proto__ 指向其构造函数Animal的prototype对象
一个关于原型的实用型例子
function Elem(id) { this.elem = document.getElementById(id) } Elem.prototype.html = function (val) { var elem = this.elem if (val) { elem.innerHTML = val return this // 链式编程 }else{ return elem.innerHTML } } Elem.prototype.on = function (type, fn) { var elem = this.elem elem.addEventListener(type, fn) } var div1 = new Elem('div1') div1.html('灶门碳治郎').on('click', (e) => { alert('灶门碳治郎') })
这个栗子,使用原型将对dom节点的操作封装起来,只要创建一个Elem实例就轻松插入dom和添加事件监听。
原型链图
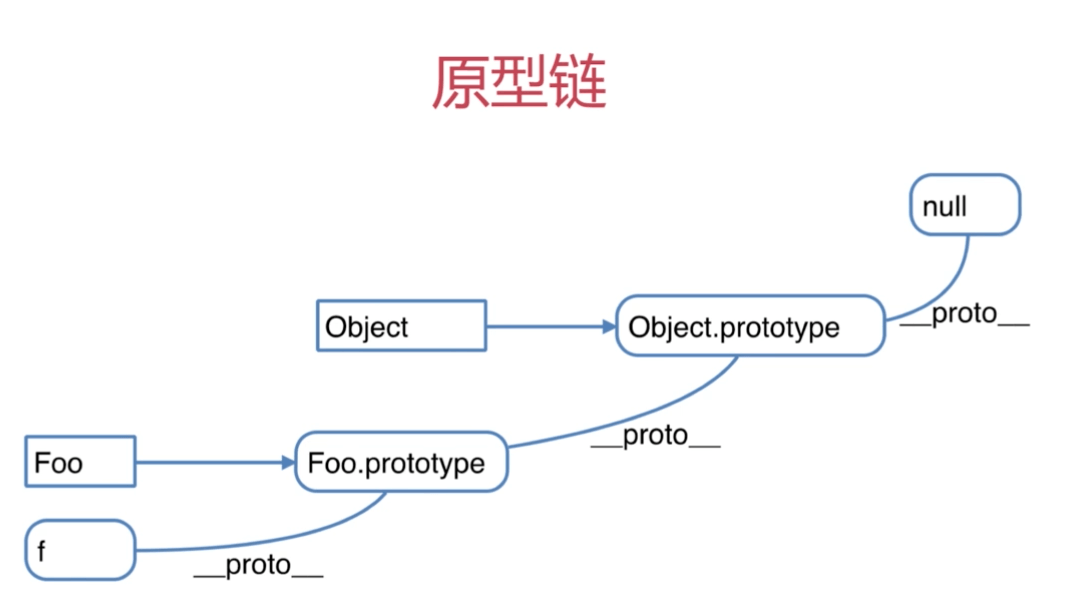
所有的引用类型会有一个__proto__属性指向其构造函数的prototype,当访问这个引用类型的变量和方法时,会通过__proto__属性一层层往上找。如[]不止有构造函数Array原型上的方法,还有可以通过原型链找到Object原型上的方法。
关于instanceof 和 constructor
instanceof:判断操作符右边的参数是否在左边的原型链上。所以[] instanceof Object也为true
let obj = {} let arr = [] console.log(typeof(obj)) // object console.log(typeof(arr)) // object console.log(obj instanceof Array) // false console.log(arr instanceof Array) // true console.log(obj.constructor === Array) // false console.log(arr.constructor === Array) // true
通过以上代码可以学习通过instanceof关键字和constructor 属性进行数据类型判断的使用方式。
关于链式编程
上述“一个关于原型的实用例子”中,提到了链式编程,在此做简单介绍
function Dog(){ this.run = function(){ alert('dog is run...') return this // 链式编程的关键 } this.eat = function(){ alert('dog is eat...') return this } this.sleep = function(){ alert('dog is sleep...') return this } } var d1 = new Dog() d1.run().eat().sleep()
通过以上代码可以看出
- 链式编程的设计模式就是,调用的函数的时候,可以基于其返回值继续调用其他方法。
- 关键在于方法执行结束后需要有一个供继续调用的返回值,如
this等。
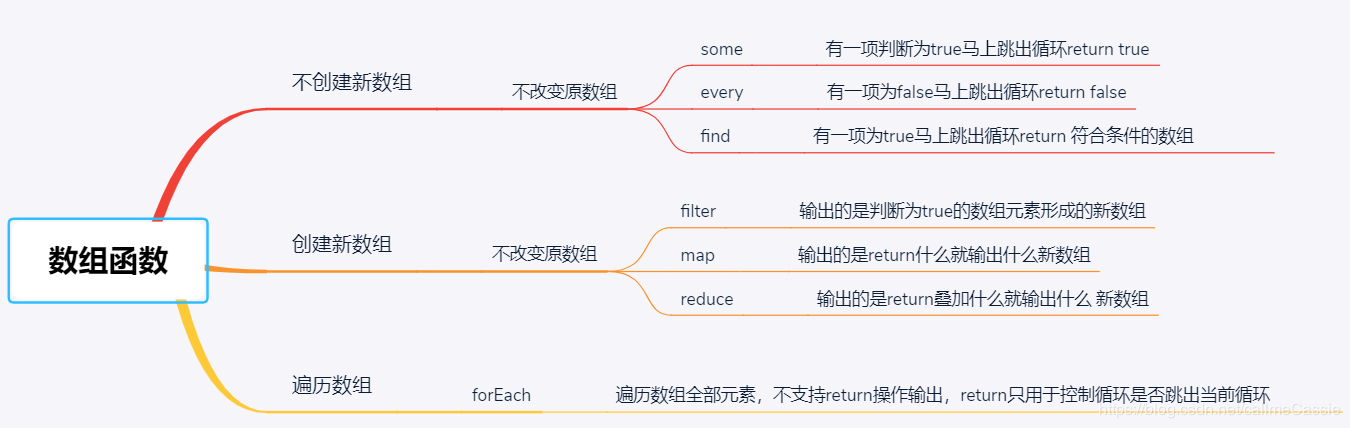
16.ES6数组操作:some、every、find、filter、map、forEach有什么区别
some
- 不创建新数组
- 不改变原数组
- 输出的是判断为true则马上跳出循环并return成true
- 回调函数参数,item(数组元素)、index(序列)、arr(数组本身)
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
//计算对象数组中每个电脑的操作系统是否可用, //大于16位操作系统表示可用,否则不可用 var computers = [ { name: "Apple", ram: 8 }, { name: "IBM", ram: 4 }, { name: "Acer", ram: 32 }, ]; var some = computers.some(function (computer) { return computer.ram > 16; }); console.log(some);//true console.log(computers);//[{ name: "Apple", ram: 8 },{ name: "IBM", ram: 4 },{ name: "Acer", ram: 32 }]
every(与some相反)
- 不创建新数组
- 不改变原数组
- 输出的是判断为false则马上跳出循环并return成false
- 回调函数参数,item(数组元素)、index(序列)、arr(数组本身)
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
var computers = [ { name: "Apple", ram: 8 }, { name: "IBM", ram: 4 }, { name: "Acer", ram: 32 }, ]; var every = computers.every(function (computer) { return computer.ram > 16; }); console.log(every);//false
find
- 不创建新数组
- 不改变原数组
- 输出的是一旦判断为true则跳出循环输出符合条件的数组元素
- 回调函数参数,item(数组元素)、index(序列)、arr(数组本身)
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
//假定有一个对象数组,找到符合条件的对象 var users = [ { name: 'Jill' }, { name: 'Alex', id: 1 }, { name: 'Bill' }, { name: 'Alex' }, ]; var user = users.find(function (user) { return user.name === 'Alex'; }); console.log(user);//[{ name: 'Alex', id: 1 }] //假定有一个对象数组(A),根据指定对象的条件找到数组中符合条件的对象 var posts = [ { id: 1, title: "Node.js" }, { id: 2, title: "React.js" }, ]; var comment = { postId: 1, content: 'hello' }; function postForComment(posts, comment) { return posts.find(function (post) { return post.id === comment.postId }) }; console.log(postForComment(posts,comment));//{ id: 1, title: "Node.js" }
filter
- 创建新数组
- 不改变原数组
- 输出的是判断为true的数组元素形成的新数组
- 回调函数参数,item(数组元素)、index(序列)、arr(数组本身)
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
//假定有一个对象数组(A),获取数组中指定类型的对象放到B数组中 var products = [ { name: "cucumber", type: "vegetable" }, { name: "banana", type: "fruit" }, { name: "celery", type: "vegetable" }, { name: "orange", type: "fruit" }, ]; var filtered = products.filter(function (product) { return product.type === "vegetable" }); console.log(filtered);//[{ name: "celery", type: "vegetable" }, { name: "celery", type: "vegetable" }] //假定有一个对象数组(A),过滤掉不满足以下条件的对象 //条件:蔬菜 数量大于0 价格小于10 var products = [ { name: "cucumber", type: "vegetable", quantity: 0, price: 1 }, { name: "banana", type: "fruit", quantity: 10, price: 16 }, { name: "celery", type: "vegetable", quantity: 30, price: 8 }, { name: "orange", type: "fruit", quantity: 3, price: 6 }, ]; products = products.filter(function (product) { return product.type === 'vegetable' && product.quantity > 0 && product.price < 10 }); console.log(products);//[{ name: "celery", type: "vegetable", quantity: 30, price: 8 }] console.log(products)//[{ name: "cucumber", type: "vegetable" },{ name: "banana", type: "fruit" },{ name: "celery", type: "vegetable" },{ name: "orange", type: "fruit" }]
map
- 创建新数组
- 不改变原数组
- 输出的是return什么就输出什么新数组
- 回调函数参数,item(数组元素)、index(序列)、arr(数组本身)
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
//假定有一个数值数组(A),将A数组中的值以双倍的形式放到B数组 var numbers = [1, 2, 3, 4, 5]; var doubled = numbers.map(function (number) { return number * 2; }) console.log(doubled);//[2,4,6,8,10] //假定有一个对象数组(A),将A数组中的对象某个属性的值存储到B数组中 var cars = [ { model: 'Buick', price: 'cheap' }, { model: 'BMW', price: 'expensive' }, ]; var prices = cars.map(function (car) { return car.price; }); console.log(prices)//(2) ["cheap", "expensive"]
reduce
- 创建新数组
- 不改变原数组
- 输出的是return叠加什么就输出什么 新数组
- 使用return操作输出,会循环数组每一项,并在回调函数中操作
- 回调函数参数
-
- pre(第一次为数组第一项,之后为上一操作的结果)
- next(数组的下一项)
- index(next项的序列)
- arr(数组本身)
- 回调函数后的改变第一项参数。(不影响原数组)
//计算数组中所有值的总共 var numbers = [10, 20, 30]; var sum = 0; //reduce第二个参数是sum的值,与上面的sum无关 var sumValue = numbers.reduce(function (sum, number) { return sum += number; }, 0); console.log(sumValue);//60 //使用reduce能同时实现map和filter,reduce能遍历数组两遍 const numberss=[10,20,30,40]; const doubleedOver50=numberss.reduce((finalList,num)=>{ num=num*2; if(num>50){ finalList.push(num); } return finalList; },[]); console.log(doubleedOver50);//[60,80] //将数组中对象的某个属性抽离到另外一个数组中 var primaryColors = [ { color: 'red' }, { color: 'yellow' }, { color: 'blue' }, ]; var color = primaryColors.reduce(function (previous, primaryColor) { previous.push(primaryColor.color); return previous; }, []); console.log(color);//["red", "yellow", "blue"] // 判断字符串括号是否对称,遇到(时加1,遇到)时减1 function balancedParens(string) { return !string.split("").reduce(function (previous, char) { if (previous < 0) { return previous };//若")"比"("先出现 if (char == "(") { return ++previous }; if (char == ")") { return --previous }; return previous; }, 0); }; console.log(balancedParens(")((()))"));//false
forEach
遍历数组全部元素,利用回调函数对数组进行操作,自动遍历数组.length次数,且无法break中途跳出循环
不支持return操作输出,return只用于控制循环是否跳出当前循环
因此难操作成新数组,新值
var colors = ['red', 'blue', 'green'] colors.forEach(function (color) { console.log(color);//red blue green })
17.数组去重(ES5/ES6)
方法一
- 利用es6中set容器的特点:set容器是无序不可重复的多个value的集合体,将数组作为参数传入会自动去重
- 循环遍历 for(let value of target){},可遍历数组,set容器,map容器,字符串,伪数组
let arr = [1,2,3,3,4,4,5,6,6,7] let arr1 = arr; arr = []; let set2 = new Set(arr1); for(let i of set2){ arr.push(i); } console.log(arr);// [1, 2, 3, 4, 5, 6, 7]
方法二
Array.from(v) : 将伪数组对象或可遍历对象转换为真数组
let arr = [3,3,4,5,6,1,3,5,5,6,1] arr = Array.from(new Set(arr)); console.log(arr);// [3, 4, 5, 6, 1]
方法三
三点运算符内部使用for...of循环
let arr = [3,3,4,5,6,1,3,5,5,6,1] let arr1 = [...new Set(arr)]; console.log(arr1); //[3, 4, 5, 6, 1]
方法四
reduce函数的特点
let arr = [1,2,3,4,4,1] let arr1 = arr.reduce((pre,cur)=>{ if(!pre.includes(cur)){ return pre.concat(cur) }else{ return pre } },[]) console.log(arr1);// [1, 2, 3, 4]
方法五
使用的数组方法:
- arrayObject.slice(start,end:可不传) ,返回一个新的数组,包含从 start 到 end (不包括该元素)的 arrayObject 中的元素,该方法并不会修改数组,而是返回一个子数组。。
- arrayObject.splice(index,howmany,item1,.....,itemX),方法向/从数组中添加/删除项目,然后返回被删除的项目,该方法会改变原数组。
let arr = [3,3,4,5,6,1,3,5,5,6,1] for(let i = 0;i<arr.length-1;i++){ let item = arr[i], args = arr.slice(i+1) if(args.includes(item)){ //① arr[i] = null arr.splice(i,1) i-- } } //① arr = arr.filter(item => item!=null) console.log(arr)// [4, 3, 5, 6, 1]
方法六
该方法是方法五的修改版,思路是取每一项和剩下的作对比,如果剩下的数组存在此项,则将数组最后一项与他替换
let arr = [3, 3, 4, 5, 6, 1, 3, 5, 5, 6, 1] for (let i = 0; i < arr.length; i++) { let item = arr[i], args = arr.slice(i + 1) if (args.includes(item)) { arr[i] = arr[arr.length - 1] arr.length-- i-- } } console.log(arr)
方法七
就是简单的循环套循环遍历对比
function way1(arr){ var arr1 = [arr[0]]; for(var i = 1;i<arr.length;i++){ var repeat = false; for(var j = 0;j<arr1.length;j++){ if(arr[i] === arr1[j]){ repeat = true; break; } } if(!repeat){ arr1.push(arr[i]) } } return arr1; }
方法八
先排序,取出新的值与相邻的值进行对比
function way2(arr){ var arr2 = arr.sort(); var arr3 = [arr2[0]]; for(var i=1; i<arr2.length; i++){ if(arr2[i] !== arr3[arr3.length-1]){ arr3.push(arr2[i]); } } return arr3; }
方法九
利用json对象的特点
function way3(arr){ var obj = {}, arr1 = []; for(var i = 0;i < arr.length;i++){ if(!obj[arr[i]]){ obj[arr[i]] = 1; arr1.push(arr[i]); } } return arr1; }
方法十
利用数组的indexOf方法,调用时,若参数在该数组中存在,则返回该参数在数组中的下标位置。
注:此处参数与数组中的元素对比,严格采用“===”进行对比,即不做隐式的数据类型转换
function way4(arr){ var arr1 = []; for(var i=0; i<arr.length; i++){ if(arr1.indexOf(arr[i]) == -1){ arr1.push(arr[i]); } } return arr1; }
18.项目如何管理模块
在一个项目内,当有多个开发者一起协作开发时,或者功能越来越多、项目越来越庞大时,保证项目井然有序的进行是相当重要的。
一般会从下面几点来考证一个项目是否管理得很好:
- 可扩展性:能够很方便、清晰的扩展一个页面、组件、模块
- 组件化:多个页面之间共用的大块代码可以独立成组件,多个页面、组件之间共用的小块代码可以独立成公共模块
- 可阅读性:阅读性良好(包括目录文件结构、代码结构),能够很快捷的找到某个页面、组件的文件,也能快捷的看出项目有哪些页面、组件
- 可移植性:能够轻松的对项目架构进行升级,或移植某些页面、组件、模块到其他项目
- 可重构性:对某个页面、组件、模块进行重构时,能够保证在重构之后功能不会改变、不会产生新 bug
- 开发友好:开发者在开发某一个功能时,能够有比较好的体验(不好的体验比如:多个文件相隔很远)
- 协作性:多人协作时,很少产生代码冲突、文件覆盖等问题
- 可交接性:当有人要离开项目时,交接给其他人是很方便的
参考链接: https://blog.csdn.net/weixin_34185512/article/details/88570900