转载:CFS任务的负载均衡
一、任务放置场景
1. 什么是任务放置(task placement)
linux内核为每个CPU都配置一个cpu runqueue,用以维护当前CPU需要运行的所有线程,调度器会按一定的规则从runqueue中获取某个线程来执行。如果一个线程正挂在某个CPU的runqueue上,此时它处于就绪状态,尚未得到cpu资源,调度器会适时地通过负载均衡(load balance)来调整任务的分布;当它从runqueue中取出并开始执行时,便处于运行状态,若该状态下的任务负载不是当前CPU所能承受的,那么调度器会将其标记为misfit task,周期性地触发主动迁移(active upmigration),将misfit task布置到更高算力的CPU。
上面提到的场景,都是线程已经被分配到某个具体的CPU并且具备有效的负载。如果一个任务线程还未被放置到任何一个CPU上,即处于阻塞状态,又或者它是刚创建、刚开始执行的,此时调度器又是何如做均衡分布的呢?这便是今天我们要花点篇幅来介绍的任务放置场景。
内核中,task placement场景发生在以下三种情况:
(1)进程通过fork创建子进程;
(2)进程通过sched_exec开始执行;
(3)阻塞的进程被唤醒。
2. 调度域(sched domain)及其标志位(sd flag)
如果你正在使用智能手机阅读本文,那你或许知道,目前的手机设备往往具备架构不同的8个CPU core。我们仍然以4小核+4大核的处理器结构为例进行说明。4个小核(cpu0-3)组成一个little cluster,另外4个大核(cpu4-7)组成big cluster,每个cluster的CPU架构相同,它们之间使用同一个调频策略,并且频率调节保持一致。大核相对小核而言,具备更高的算力,但也会带来更多的能量损耗。
对于多处理器均衡(multiprocessor balancing)而言,sched domain是极为重要的概念。内核中以结构体struct sched_domain对其进行定义,将CPU core从下往上按层级划分,对系统所有CPU core进行管理,本系列文章第一篇已进行过较为详细的描述。little cluster和big cluster各自组成底层的MC domain,包含各自cluster的4个CPU core,顶层的DIE domian则覆盖系统中所有的CPU core。
内核调度器依赖sched domain进行均衡,为了方便地对各种均衡状态进行识别,内核定义了一组sched domain flag,用来标识当前sched domain具备的均衡属性。表中,我们可以看到task placement场景常见的三种情况对应的flag。

在构建CPU拓扑结构时,会为各个sched domain配置初始的标识位,如果是异构系统,会设置SD_BALANCE_WAKE:
*sd = (struct sched_domain){ //kernelsched opology.c .min_interval = sd_weight, .max_interval = 2*sd_weight, .busy_factor = 32, .imbalance_pct = 125, .cache_nice_tries = 0, .busy_idx = 0, .idle_idx = 0, .newidle_idx = 0, .wake_idx = 0, .forkexec_idx = 0, .flags = 1*SD_LOAD_BALANCE | 1*SD_BALANCE_NEWIDLE | 1*SD_BALANCE_EXEC | 1*SD_BALANCE_FORK | 0*SD_BALANCE_WAKE | 1*SD_WAKE_AFFINE | 0*SD_SHARE_CPUCAPACITY | 0*SD_SHARE_PKG_RESOURCES | 0*SD_SERIALIZE | 0*SD_PREFER_SIBLING | 0*SD_NUMA | sd_flags ,
3. task placement均衡代码框架
linux内核的调度框架是高度抽象、模块化的,所有的线程都拥有各自所属的调度类(sched class),比如大家所熟知的实时线程属于rt_sched_class,CFS线程属于fair_sched_class,不同的调度类采用不同的调度策略。上面提到的task placement的三种场景,最终的函数入口都是core.c中定义的select_task_rq()方法,之后会跳转至调度类自己的具体实现。本文以CFS调度类为分析对象,因为该调度类的线程在整个系统中占据较大的比重。有兴趣的朋友可以了解下其它调度类的select_task_rq()实现。

4. select_task_rq_fair()方法
CFS调度类的线程进行task placement时,会通过core.c的select_task_rq()方法跳转至select_task_rq_fair(),该方法声明如下:
static int select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
sd_flag参数:传入sched domain标识位,目前一共有三种:SD_BALANCE_WAKE、SD_BALANCE_FORK、SD_BALANCE_EXEC,分别对应task placement的三种情形。调度器只会在设置有相应标识位的sched domain中进行CPU的选择。
wake_flags参数:特地为SD_BALANCE_WAKE提供的唤醒标识位,一共有三种类型:
//kernelschedsched.h #define WF_SYNC 0x01 /* Waker goes to sleep after wakeup */ #define WF_FORK 0x02 /* Child wakeup after fork */ #define WF_MIGRATED 0x4 /* Internal use, task got migrated */
select_task_rq_fair()内仅对WF_SYNC进行处理,若传入该标识位,说明唤醒线程waker在被唤醒线程wakee唤醒后,将进入阻塞状态,调度器会倾向于将wakee放置到waker所在的CPU。这种场景使用相当频繁,比如用户空间两个进程进行非异步binder通信,Server端唤醒一个binder线程处理事务时,调用的接口如下:
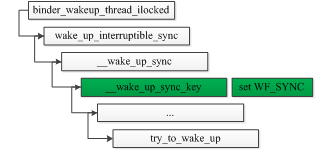
select_task_rq_fair()中涉及到三个重要的选核函数:
find_energy_efficient_cpu()
find_idlest_cpu()
select_idle_sibling()
它们分别代表任务放置过程中的三条路径。task placement的各个场景,根据不同条件,最终都会进入其中某一条路径,得到任务放置CPU并结束此次的task placement过程。现在让我们来理一理这三条路径的常见进入条件以及基本的CPU选择考量:
(1)find_energy_efficient_cpu(),即EAS选核路径。当传入参数sd_flag为SD_BALANCE_WAKE,并且系统配置key值sched_energy_present(即考虑性能和功耗的均衡),调度器就会进入EAS选核路径进行CPU的查找。这里涉及到内核中Energy Aware Scheduling(EAS)机制,我们稍后将在第三节中详细描述。总之,EAS路径在保证任务能正常运行的前提下,为任务选取使系统整体能耗最小的CPU。通常情况下,EAS总是能如愿找到符合要求的CPU,但如果当前平台不是异构系统,或者系统中存在超载(Over-utilization)的CPU,EAS就直接返回-1,不能在这次调度中大展拳脚。
当EAS不能在这次调度中发挥作用时,分支的走向取决于该任务是否为wake affine类型的任务,这里让我们先来简单了解下该类型的任务。
用户场景有时会出现一个主任务(waker)唤醒多个子任务(wakee)的情况,如果我们将其作为wake affine类型处理,将wakee打包在临近的CPU上(如唤醒CPU、上次执行的CPU、共享cache的CPU),即可以提高cache命中率,改善性能,又能避免唤醒其它可能正处于idle状态的CPU,节省功耗。看起来这样的处理似乎非常完美,可惜的是,往往有些wakee对调度延迟非常敏感,如果将它们打包在一块,CPU上的任务就变得“拥挤”,调度延迟就会急剧上升,这样的场景下,所谓的cache命中率、功耗,一切的诱惑都变得索然无味。
对于wake affine类型的判断,内核主要通过wake_wide()和wake_cap()的实现,从wakee的数量以及临近CPU算力是否满足任务需求这两个维度进行考量。
(2)find_idlest_cpu(),即慢速路径。有两种常见的情况会进入慢速路径:传入参数sd_flag为SD_BALANCE_WAKE,且EAS没有使能或者返回-1时,如果该任务不是wake affine类型,就会进入慢速路径;传入参数sd_flag为SD_BALANCE_FORK、SD_BALANCE_EXEC时,由于此时的任务负载是不可信任的,无法预测其对系统能耗的影响,也会进入慢速路径。慢速路径使用find_idlest_cpu()方法找到系统中最空闲的CPU,作为放置任务的CPU并返回。基本的搜索流程是:
首先确定放置的target domain(从waker的base domain向上,找到最底层配置相应sd_flag的domain),然后从target domain中找到负载最小的调度组,进而在调度组中找到负载最小的CPU。
这种选核方式对于刚创建的任务来说,算是一种相对稳妥的做法,开发者也指出,或许可以将新创建的任务放置到特殊类型的CPU上,或者通过它的父进程来推断它的负载走向,但这些启发式的方法也有可能在一些使用场景下造成其他问题。
(3)select_idle_sibling(),即快速路径。传入参数sd_flag为SD_BALANCE_WAKE,但EAS又无法发挥作用时,若该任务为wake affine类型任务,调度器就会进入快速路径来选取放置的CPU,该路径在CPU的选择上,主要考虑共享cache且idle的CPU。在满足条件的情况下,优先选择任务上一次运行的CPU(prev cpu),hot cache的CPU是wake affine类型任务所青睐的。其次是唤醒任务的CPU(wake cpu),即waker所在的CPU。当该次唤醒为sync唤醒时(传入参数wake_flags为WF_SYNC),对wake cpu的idle状态判定将会放宽,比如waker为wake cpu唯一的任务,由于sync唤醒下的waker很快就进入阻塞状态,也可当做idle处理。
如果prev cpu或者wake cpu无法满足条件,那么调度器会尝试从它们的LLC domain中去搜索idle的CPU。
二、Energy Aware Scheduling(EAS)
系统中的Energy Aware Scheduling(EAS)机制被使能时,调度器就会在CFS任务由阻塞状态唤醒的时候,使用find_energy_efficient_cpu()为任务选择合适的放置CPU。
1. 什么是Energy Model(EM)
在了解什么是EAS之前,我们先学习下EM。EM的设计使用比较简单,因为我们要避免在task placement时,由于算法过于复杂导致调度延迟变高。理解EM的一个重点是理解性能域(performance domain)。与sched domain相同,内核也有相应的结构体struct perf_domain来定义性能域。相同微架构的CPU会归属到同一个perf domain,4大核+4小核的CPU拓扑信息如下:

little cluster的4个CPU core组成一个perf domain,big cluster则组成另外一个。相同perf domian内的所有CPU core一起进行调频,保持着相同的频率。CPU使用的频点是分级的,各级别的频点与capacity值、power值是一一映射的关系,例如:小核的4个cpu,最大capacity都是512,与之对应的最高频点为1G Hz,那么500M Hz的频点对应的capacity就是256。为了将这些信息有效的组织起来,内核又为EM增加两个新的结构体,用于存储这些信息,它们都能够从perf domain中获取。

2. 什么是EAS
异构CPU拓扑架构(比如Arm big.LITTLE架构),存在高性能的cluster和低功耗的cluster,它们的算力(capacity)之间存在差异,这让调度器在唤醒场景下进行task placement变得更加复杂,我们希望在不影响整体系统吞吐量的同时,尽可能地节省能量,因此,EAS应运而生。它的设计令调度器在做CPU选择时,增加能量评估的维度,它的运作依赖于Energy Model(EM)。
EAS对能量(energy)和功率(power)的定义与传统意义并无差别,energy是类似电源设备上的电池这样的资源,单位是焦耳,power则是每秒的能量损耗值,单位是瓦特。
EAS在非异构系统下,或者系统中存在超载CPU时不会使能,调度器对于CPU超载的判定是比较严格的,当root domain中存在CPU负载达到该CPU算力的80%以上时,就认为是超载。
3. EM是如何估算energy的
由于EM将系统中所有CPU的各级capacity、frequence、power以便捷高效的方式组织起来,计算energy的工作就变得很简单了。内核中某个perf domian的energy可以通过em_pd_energy()获得,它实际上是通过假定将任务放置到某个CPU上,引起perf domain各个CPU负载变化,来估算整体energy数值。令人值得庆幸的是,该方法的实现代码中,有一半以上都是注释语句。
static inline unsigned long em_pd_energy(struct em_perf_domain *pd, unsigned long max_util, unsigned long sum_util)
max_util参数:perf domain各个CPU中的最高负载。
sum_util参数:perf domain中所有CPU的总负载。
前面提到过,同个perf domian下的所有CPU使用相同的频点,因此,cluster选择哪个频点,取决于拥有最大负载的CPU。EM首先会获取当前perf domain的最高频点和最大算力,并将max_util映射到对应的频率上,找到超过该频率的最低频点及相应的算力cs_capacity,毕竟我们要确保任务能够正常执行。
尽管我们知道EA可以很轻易的获得该频点的功率cs_power值,并且无论是cs_capacity还是cs_power,domain下所有CPU都是相同的,但是要获得各个CPU的energy,我们还需要一个跟各个CPU运行时间相关的信息。由于CPU不是超载的(超载情况下EAS不会使能),它不会一直运行任务,我们需要忽略掉idle的部分,这一点可以通过CPU负载与算力的比值进行估算。这是由于,负载体现了CPU执行任务的窗口时间,当整个窗口时间都在运行任务时,CPU的负载就达到其算力上限。
好了,现在需要的信息都齐全,只要将所有CPU的energy累加起来,就能得到整个perf domain的估计能量值。
4. EAS task placement
EAS在任务唤醒时,通过函数find_energy_efficient_cpu()为任务选择合适的放置CPU,它的实现逻辑大致如下:
(1)通过em_pd_energy()计算取得各个perf domian未放置任务的基础能量值;
(2)遍历各个perf domain,找到该domain下拥有最大空余算力的CPU以及prev cpu,作为备选放置CPU;
(3)通过em_pd_energy()计算取得将任务放置到备选CPU引起的perf domain的energy变化值;
(4)通过比较得到令energy变化最小的备选CPU,即将任务放置到该CPU上,能得到最小的domain energy,如果相对于将任务放置到prev cpu,此次的选择能节省6%以上的能量,则该CPU为目标CPU。
选择perf domain中拥有最大空余算力的CPU作为备选CPU,是因为这样可以避免某个CPU负载特别高,导致整个cluster的频点往上提。并且顾及到hot cache的prev cpu有利于提高任务运行效率,EAS对于prev cpu还是难以割舍的,除非节能可以达到6%以上。
另外,从上面的逻辑中也可以看出为何超载情况下EAS是不使能的。我们假定little cluster中cpu3存在超载的情况,那么无论你将任务放置到哪个CPU上,little cluster总是维持最高频点,对于同个perf domain下拥有最大空余算力的CPU来说,这样预估的energy是不公平的,与EAS的设计相违背,EAS希望能通过放置任务改变cluster的频点来降低功耗。
三、总结
本文作为负载均衡系列文章的第二篇,主要对CFS任务的task placement做场景分析,描述调度器在此过程中的选择实现和考量,由于篇幅和精力有限,很多具体的细节还没能呈现清晰,特别是对快速路径和慢速路径这一块的描述,希望有兴趣的朋友可以自行阅读源码实现,共同学习交流。
我们可以看到,目前task placement过程中的一些启发式算法还存在缺陷,也能看到开发者对此的不断思考和创新,随着内核版本的不断更新迭代,未来的调度算法一定会出现更多有意思的特性。
参考资料
[1] linux-5.4.24 source code
[2] linux-5.4.24/Documentation/power/ energy-model.rst
[3] linux-5.4.24/Documentation/scheduler/ sched-energy.rst
[4] https://lwn.net/Articles/728942/