问题:test_table 表中有 a,b,c 三个字段,求根据字段a 去除重复数据,得到去重后的整行数据
根据mysql的经验尝试以下方法均失败
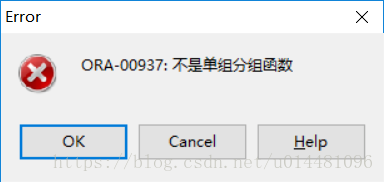
1、使用 distinct 关键字 (oracle查询数据中,不允许非 distinct 标注字段 )
select count(distinct a),a,b,c from test_table;
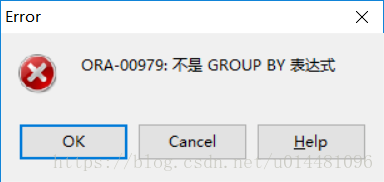
2、使用 group by (oracle查询数据中不允许非分组字段)
select a,b,c from test_table group by a;
解决方案:使用row_number() over( partition by) 方法分组排序
with temp as (
select a,b,c from test_table
)
select a,b,c from (
select a,b,c,row_number() over (partition by a order by rownum) row_no from temp
) where row_no = 1
ps: with temp as() 括号内的内容 就是查询的sql 结果包含重复数据
row_number() over(partition by 需要检索重复的列 order by 排序的列名) 别名 row_no ,如果分组存在多条相同值,row_no 从1开始递增,筛选 row_no = 1 ,就取到了只出现一次的数据
参考:https://blog.csdn.net/u014481096/article/details/82144519