推荐一个语义分割专栏,作者对本领域的很多论文都进行了整理:语义分割刷怪进阶
而截止目前,CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:
- 较浅的卷积层感知域较小,学习到一些局部区域的特征;
- 较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
这些深层抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,也就是说图像分类是图像级别任务(参考图像语义分割入门)。
与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割,图像语义分割是像素级别的任务,但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。针对这个问题,Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。
注意,本文仅对基于深度学习的经典语义分割成果进行梳理,之所以说是经典,是因为本文几乎没有涉及18年及之后的最新进展,故标题也说了:只是入门基于深度学习的语义分割。
一、FCN
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题。
1、网络特点
- 全卷积(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
2、网络结构
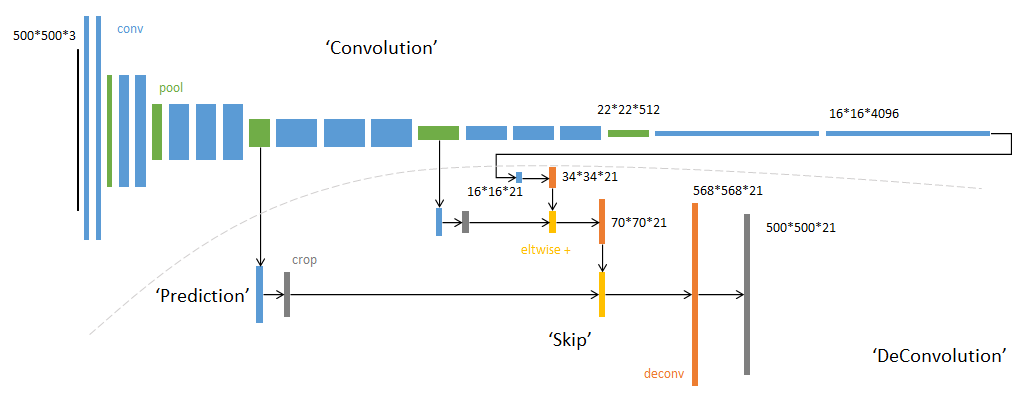
3、原理说明
全卷积
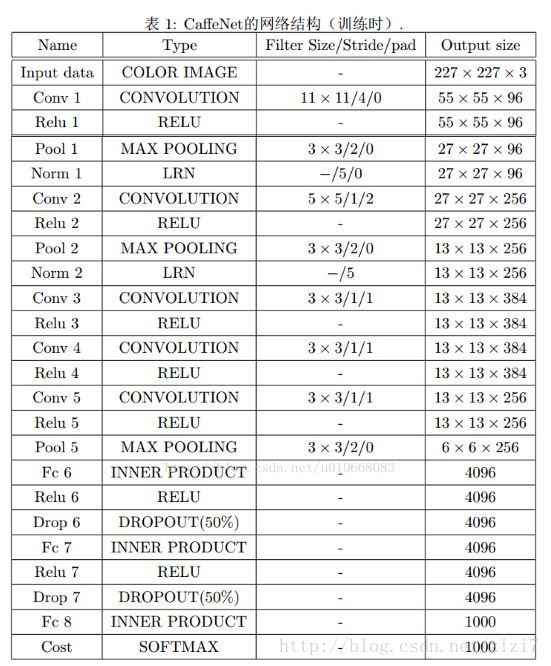
FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
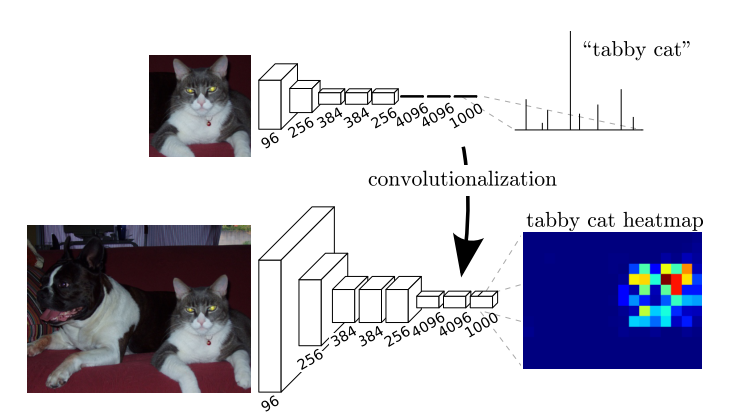
上采样——转置卷积
可以发现,经过多次卷积(还有pooling)以后,得到的图像越来越小,分辨率越来越低(粗略的图像),那么FCN是如何得到图像中每一个像素的类别的呢?为了从这个分辨率低的粗略图像恢复到原图的分辨率,FCN使用了上采样。例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。这个上采样是通过反卷积(deconvolution)实现的。
另外补充一句,上采样(upsampling)一般包括2种方式:
- Resize,如双线性插值直接缩放,类似于图像缩放(这种方法在原文中提到)
- Deconvolution,也叫Transposed Convolution
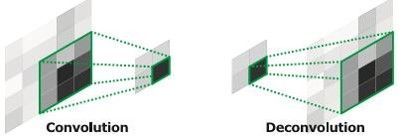
一张更为形象的说明如下:
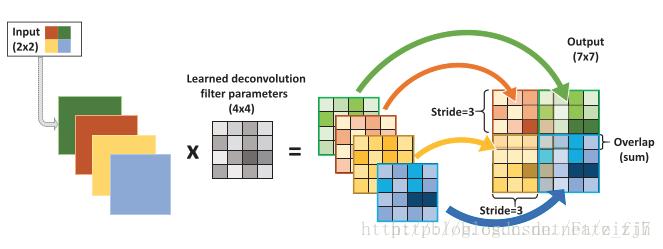
跳跃结构
对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。
其卷积过程类似:
- image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2
- pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4
- pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8
- ......
- 直到pool5 feature,宽高变为1/32。
相对应的:
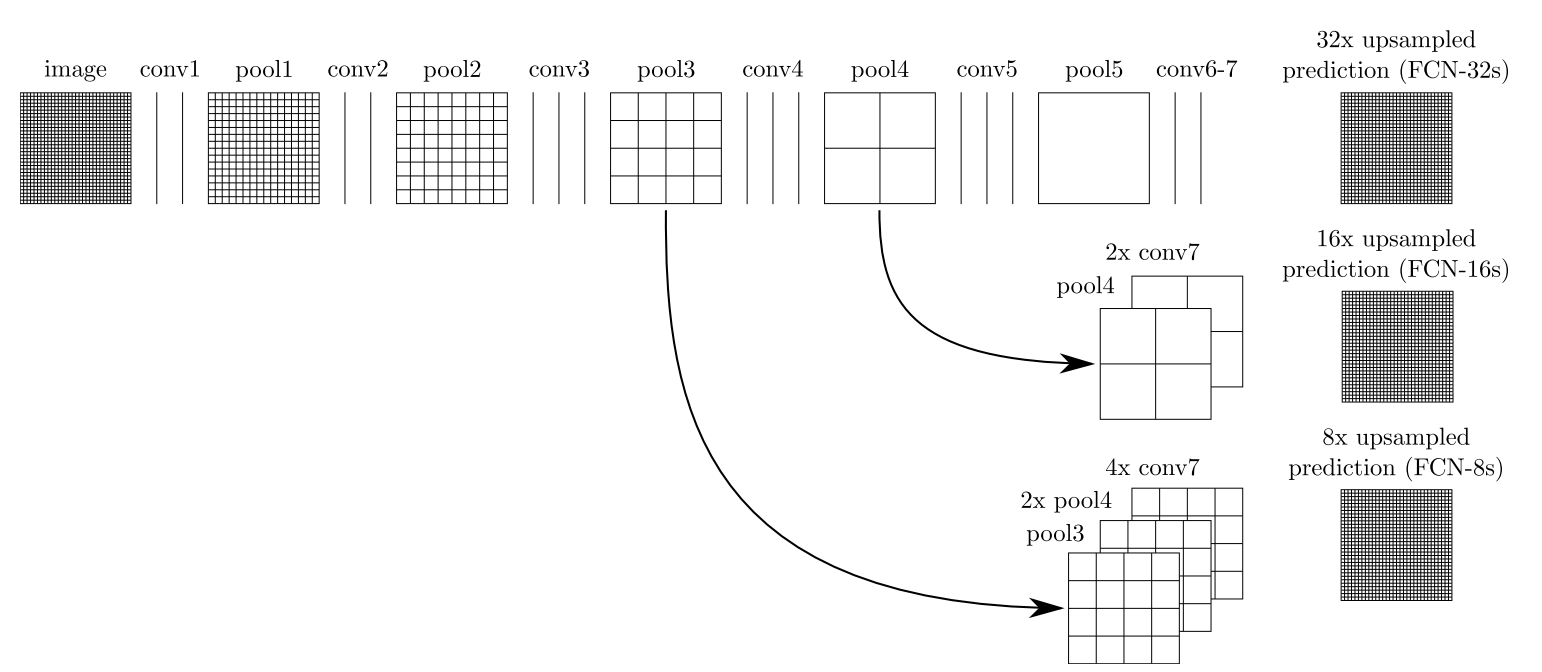
- 对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
- 对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
- 对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
下图是这个卷积和反卷积上采样的过程:
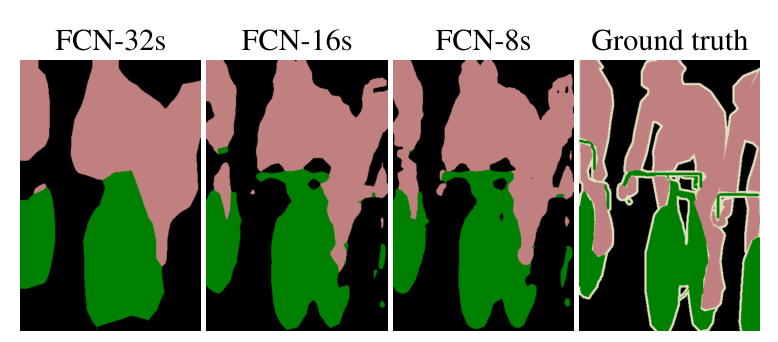
下图是32倍,16倍和8倍上采样得到的结果的对比,可以看到它们得到的结果越来越精确:
4、优点(贡献)和不足
优点和贡献
1.为深度学习解决语义分割提供了基本思路,激发了很多优秀的工作
2.输入图像大小没有限制,结构灵活
3.更加高效,节省时间和空间
不足
1.结果不够精细,边界不清晰
2.没有充分考虑到语义间的上下文关系
3.padding操作可能会引入噪声
二、SegNet
基于FCN的一项工作,修改VGG-16网络得到的语义分割网络,有两种SegNet,分别为正常版与贝叶斯版,同时SegNet作者根据网络的深度提供了一个basic版(浅网络)。
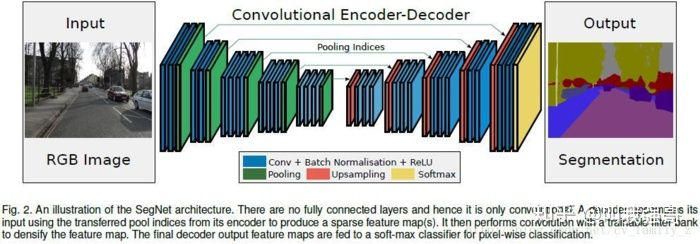
1、网络结构
作者提供了几种网络结构,上图就是通用结构:对称的encode-decode结构,想了解更为具体的实现建议查看开源实现。
2、创新点
SegNet的最大池化层和上采样层不同于通常的处理,SegNet 中使用最大池化,并且同时输出最大点的 index。同一层次的上采样根据 index 确定池化前 max 值的点的位置,并对其他丢失的点做插值。
补充一点,tensorflow对于SegNet的上采样方式并不支持(也许只是没有封装好而已,可以手动实现,不确定),所以我查到的实现一般就直接用普通的上采样了,这样tf版本的SegNet结构相较U-Net简单了不少(个人感觉两者还是很相似的)。有趣的是带索引最大池化tf是有封装好的接口的,在nn包中。
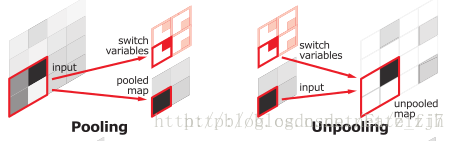
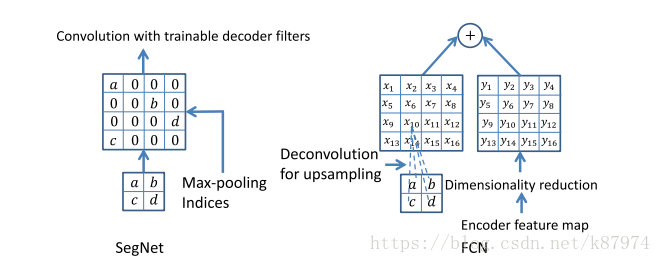
作为对比,下左为SegNet,下右为FCN中的上采样实现(FCN的上采样相较现在成熟的上采样方案也略有不同,多加了一个根据原始编码得来并保存的y,这需要消耗额外的内存):
此外还有贝叶斯SegNet变种,不太懂,就不画蛇添足了。
三、U-Net
U-Net是原作者参加ISBI Challenge提出的一种分割网络,能够适应很小的训练集(大约30张图)。U-Net与FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构简单。
卷积网络被大规模应用在分类任务中,输出的结果是整个图像的类标签。然而,在许多视觉任务,尤其是生物医学图像处理领域,目标输出应该包括目标类别的位置,并且每个像素都应该有类标签。另外,在生物医学图像往往缺少训练图片。所以,Ciresan等人训练了一个卷积神经网络,用滑动窗口提供像素的周围区域(patch)作为输入来预测每个像素的类标签。这个网络有两个优点: 第一,输出结果可以定位出目标类别的位置; 第二,由于输入的训练数据是patches,这样就相当于进行了数据增广,解决了生物医学图像数量少的问题。
但是,这个方法也有两个很明显缺点。
第一,它很慢,因为这个网络必须训练每个patch,并且因为patch间的重叠有很多的冗余(冗余会造成什么影响呢?卷积核里面的W,就是提取特征的权重,两个块如果重叠的部分太多,这个权重会被同一些特征训练两次,造成资源的浪费,减慢训练时间和效率,虽然说会有一些冗余,训练集大了,准确率不就高了吗?可是你这个是相同的图片啊,重叠的东西都是相同的,举个例子,我用一张相同的图片训练20次,按照这个意思也是增大了训练集啊,可是会出现什么结果呢,很显然,会导致过拟合,也就是对你这个图片识别很准,别的图片就不一定了)。
第二,定位准确性和获取上下文信息不可兼得。大的patches需要更多的max-pooling层这样减小了定位准确性(为什么?因为你是对以这个像素为中心的点进行分类,如果patch太大,最后经过全连接层的前一层大小肯定是不变的,如果你patch大就需要更多的pooling达到这个大小,而pooling层越多,丢失信息的信息也越多;小的patches只能看到很小的局部信息,包含的背景信息不够。
和SegNet格式极为相近,不过其添加了中间的center crop和concat操作实现了不同层次特征的upsample,目的同样是使上采样的层能够更多的参考前面下采样中间层的信息,更好的达到还原的效果。
U-Net的格式也不复杂,形状如下,参看github开源实现不难复现,注意用好相关张量操作API即可(如concet、slice等)。值得注意的是U-Net采用了与FCN完全不同的特征融合方式:拼接!与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征。所以:
语义分割网络在特征融合时也有2种办法:
- FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add()
- U-Net式的channel维度拼接融合,对应caffe的ConcatLayer层,对应tensorflow的tf.concat()

(1) 使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
(2) 左边的网络是收缩路径:使用卷积和maxpooling。
(3) 右边的网络是扩张路径:使用上采样产生的特征图与左侧收缩路径对应层产生的特征图进行concatenate操作。(pooling层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务有一些影响,对图像分类任务的影响不大,为什么要做上采样?因为上采样可以补足一些图片的信息,但是信息补充的肯定不完全,所以还需要与左边的分辨率比较高的图片相连接起来(直接复制过来再裁剪到与上采样图片一样大小),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有效,更加抽象,上采样的图片是经历多次卷积后的图片,肯定是比较高效和抽象的图片,然后把它与左边不怎么抽象但更高分辨率的特征图片进行连接)。
(4) 最后再经过两次反卷积操作,生成特征图,再用两个1X1的卷积做分类得到最后的两张heatmap,例如第一张表示的是第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为输入给交叉熵进行反向传播训练。
四、空洞卷积
池化操作增大了感受野,有助于实现分类网络,但是池化操作在分割过程中也降低了分辨率,空洞卷积层则可以在不降低空间维度的前提下增大了相应的感受野指数。
五、DeepLab
v1
面临问题:
在DCNN进行分割任务时,有两个瓶颈:
一个是下采样所导致的信息丢失,通过带孔卷积的方法解决;
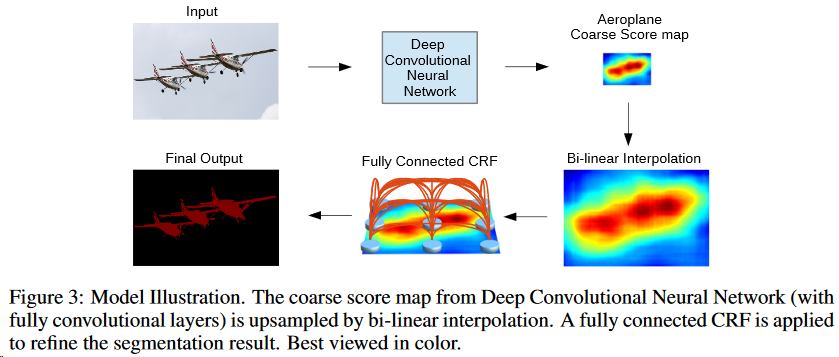
另一个是CNN空间不变性所导致的边缘不够准确,通过全连接的CRF解决(CRF是可以通过底层特征进行分割的一个方法)
核心工作:空洞卷积 (计算的特征映射更加密集)+ 如何降低计算量 + CRF作为后处理(知乎文章:FCN(3)——DenseCRF)
Deeplab:
使用带孔算法(空洞卷积)进行特征提取:将VGG16的全连层转换为卷积层,将最后两个最大池化层的后的下采样去掉,中间的卷积替换为带孔卷积
对于空洞卷积,作者提到了两个实现方法:在卷积核中间加0/ 先降采样然后过正常卷积,第二种方法计算速度快。最后三个卷积层使用2倍的步长,第一个全连层使用4倍步长,这样做的好处是不需要引入额外的近似算法。
感受野控制、加速卷积网络的密集计算:将VGG16转换为全卷积层后计算量变得非常大,为了降低运算,将第一个全连层进行降采样。这个做法降低了感受野的大小
不是很懂CRF的具体做法,简单的原文的图贴上来,感受一下框架的pipline,
v2
相较于v1,简单来说:
空洞卷积+全连接CRF+ASPP模块
主干网络从预训练的VGG变成了ResNet
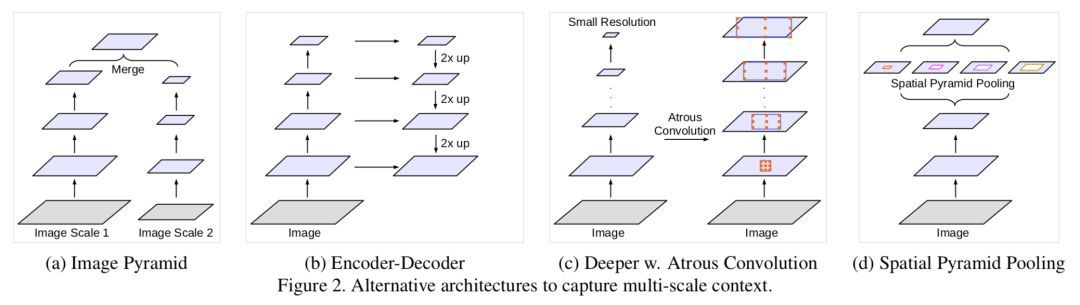
1.Image Pyramid:将输入图片放缩成不同比例,分别应用在 DCNN 上,将预测结果融合得到最终输出。
2.Encoder-Decoder:利用 Encoder 阶段的多尺度特征,运用到 Decoder 阶段上恢复空间分辨率,代表工作有 FCN、SegNet、PSPNet 等工。
3.Deeper w. Atrous Convolution:使用空洞卷积。
4.Spatial Pyramid Pooling:空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。
v3
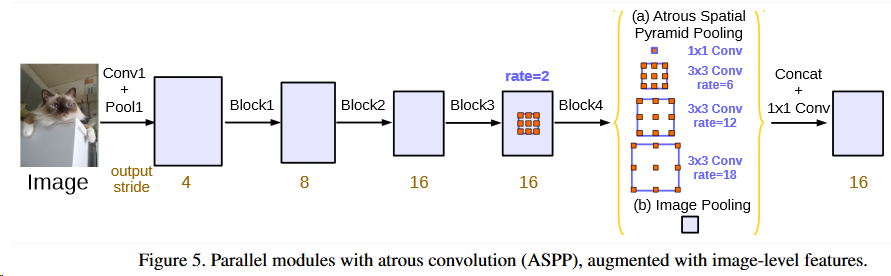
第三版相对于第二版的改动不是很大,主要是借鉴了下面的两篇论文的思想,然后分别对之前的空洞卷积和ASPP模块就行了改进,然后整体加入了BN,需要注意的是从本版本开始已经不要CRF进行后处理了:
Understanding Convolution for Semantic Segmentation
Pyramid Scene Parsing Network
另外文章指出了,在训练的时候将GT应该保持不动,将概率图插值之后再进行计算loss,这样不会导致金标准在降采样过程中丢失细节,毕竟8倍的降采样还是很严重的。
v3+
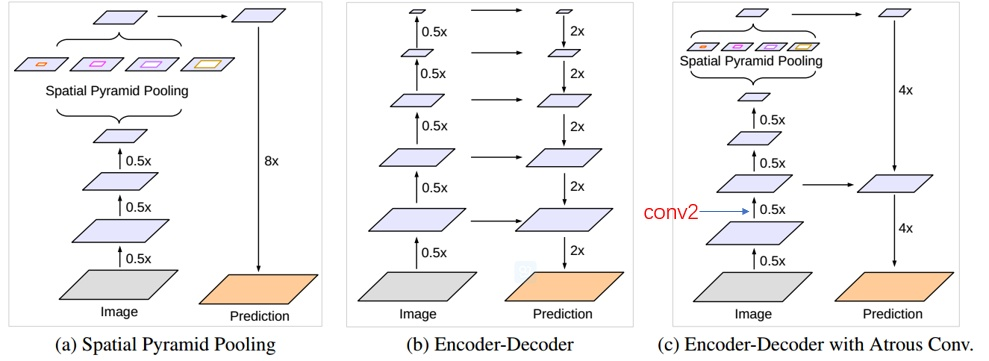
下图展示了具体的网络表示:
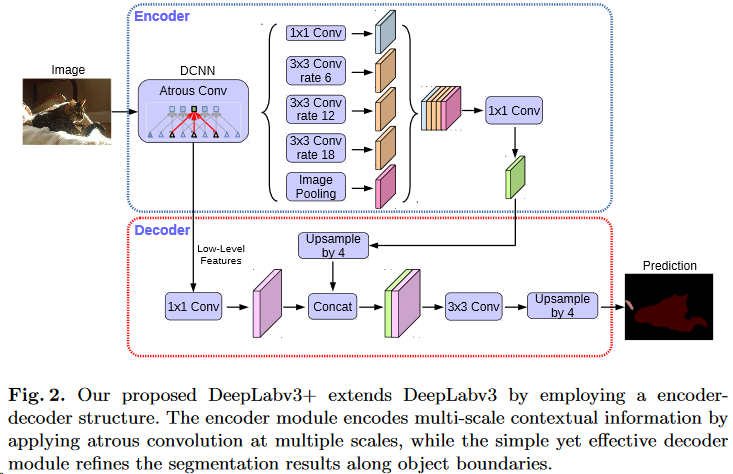
该框架参考了spatial pyramid pooling(SPP) module和encoder-decoder两种形式的分割框架。前一种就是PSPNet那一款,后一种更像是SegNet的做法。
- ASPP方法的优点是该种结构可以提取比较dense的特征,因为参考了不同尺度的feature,并且atrous convolution的使用加强了提取dense特征的能力。但是在该种方法中由于pooling和有stride的conv的存在,使得分割目标的边界信息丢失严重。
- Encoder-Decoder方法的decoder中就可以起到修复尖锐物体边界的作用。
- 关于Encoder中卷积的改进:
DeepLab V3+效仿了Xception中使用的depthwise separable convolution,在DeepLab V3的结构中使用了atrous depthwise separable convolution,降低了计算量的同时保持了相同(或更好)的效果。 - Decoder的设计:
2.1. Encoder提取出的特征首先被x4上采样,称之为F1;
2.2. Encoder中提取出来的与F1同尺度的特征F2'先进行1x1卷积,降低通道数得到F2,再进行F1和F2的concatenation,得到F3;(为什么要进行通道降维?因为在encoder中这些尺度的特征通常通道数有256或者512个,而encoder最后提取出来的特征通道数没有这么多,如果不进行降维就进行concate的话,无形之中加大了F2'的权重,加大了网络的训练难度)
2.3. 对F3进行常规的3x3convolution微调特征,最后直接x4upsample得到分割结果。
总结一下,CNN图像语义分割也就基本上是这个套路:
- 下采样+上采样:Convlution + Deconvlution/Resize
- 多尺度特征融合:特征逐点相加/特征channel维度拼接
- 获得像素级别的segement map:对每一个像素点进行判断类别