Scrapy终端
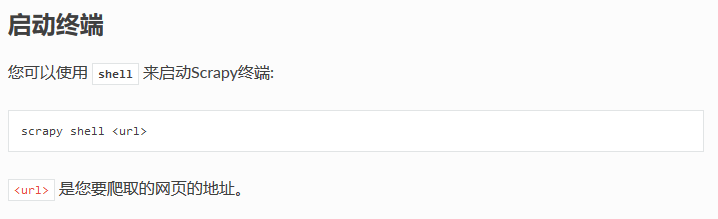
示例,输入如下命令后shell会进入Python(或IPython)交互式界面:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
有一点注意的是必须是双引号,单引号会报错。
之后会显示当前保存的数据结构以供查询,这和我们编写py脚本时的数据结构完全相同,可以直接使用相关方法,
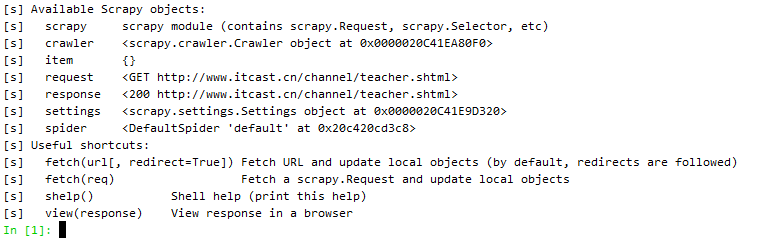
诸如:
Scrapy Selectors

如下所示,
>>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]
这两种方式提取的都是节点型数据,所以都可以使用.extract()或者.extract_first()方法提取data部分

以下面的源码为例进行提取示范:
<html> <head> <base href='http://example.com/' /> <title>Example website</title> </head> <body> <div id='images'> <a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> <a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> <a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> </div> </body> </html>
提取标签属性,
>>> response.xpath('//base/@href').extract()
[u'http://example.com/']
>>> response.css('base::attr(href)').extract()
[u'http://example.com/']
对提取目标路径的标签进行筛选,contains(@href, "image")表示href熟悉需要包含image字符,css同理,
response.xpath('//a[contains(@href, "image")]/@href').extract()
Out[1]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
response.xpath('//a[contains(@href, "image1")]/@href').extract()
Out[2]: ['image1.html']
response.css('a[href*=image]::attr(href)').extract()
Out[3]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
esponse.css('a[href*=image2]::attr(href)').extract()
Out[4]: ['image2.html']
结合两者,
>>> response.xpath('//a[contains(@href, "image")]/img/@src').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
>>> response.css('a[href*=image] img::attr(src)').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
内置了正则表达式re和re_first方法,
response.xpath('//a[contains(@href, "image")]/text()')
Out[8]:
[<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 1 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 2 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 3 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 4 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 5 '>]
response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:s*(.*)')
Out[7]: ['My image 1 ', 'My image 2 ', 'My image 3 ', 'My image 4 ', 'My image 5 ']
response.xpath('//a[contains(@href, "image")]/text()').re_first(r'Name:s*(.*)')
Out[9]: 'My image 1 '