通常机器学习每一个算法中都会有一个目标函数,算法的求解过程是通过对这个目标函数优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的算法使用的损失函数不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。通常表示为如下:

其中,前面的均值项表示经验风险函数,L表示损失函数,后面的是正则化项(regularizer)或惩罚项(penalty term),它可以是L1、L2或者其他正则函数。整个式子表示要找到使得目标函数最小的值。
下面介绍几种常见的损失函数。
0-1损失函数和绝对值损失函数
0-1损失是指,预测值和目标值不相等为1,否则为0:
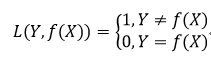
感知机就是用的这种损失函数。但是由于相等这个条件太过严格,因此我们可以放宽条件,即满足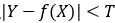 时认为相等。
时认为相等。
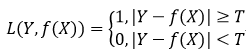
绝对值损失函数:
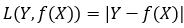
log对数损失函数
Logistic回归的损失函数就是对数损失函数,在Logistic回归的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。Logistic回归并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了log损失函数。
log损失函数的标准形式:
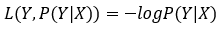
在极大似然估计中,通常都是先取对数再求导,再找极值点,这样做是方便计算极大似然估计。损失函数L(Y,P(Y|X))是指样本X在标签Y的情况下,使概率P(Y|X)达到最大值(利用已知的样本分布,找到最大概率导致这种分布的参数值)。
平方损失函数
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。最小二乘法的基本原则是:最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧式距离进行距离的度量。平方损失的损失函数为:

指数损失函数
AdaBoost就是一指数损失函数为损失函数的。
指数损失函数的标准形式:
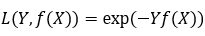
Hinge损失函数
Hinge loss用于最大间隔(maximum-margin)分类,其中最有代表性的就是支持向量机SVM。
Hinge函数的标准形式:
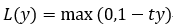
(与上面统一的形式: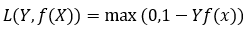 )
)
其中,t为目标值(-1或+1),y是分类器输出的预测值,并不直接是类标签。其含义为,当t和y的符号相同时(表示y预测正确)并且|y|≥1时,hinge loss为0;当t和y的符号相反时,hinge loss随着y的增大线性增大。
在支持向量机中,最初的SVM优化的函数如下:
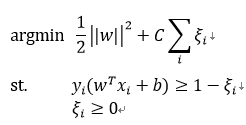
将约束项进行变形,则为:
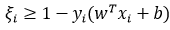
则损失函数可以进一步写为:
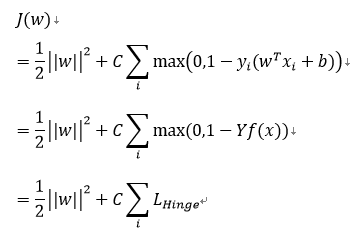
因此,SVM的损失函数可以看做是L2正则化与Hinge loss之和。
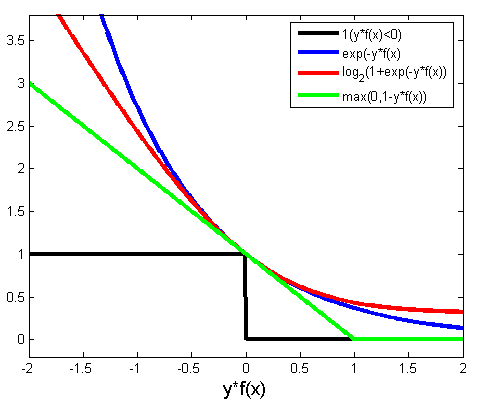
几种损失函数的曲线如下图:
参考:
相关博客:
http://blog.csdn.net/weixin_37933986/article/details/68488339
http://blog.csdn.net/u010976453/article/details/78488279
维基百科:
https://en.wikipedia.org/wiki/Hinge_loss