集合框架总图:

一、ArrayList
为什么要使用?
存放多个对象也可以使用数组,但是定义数组有局限性,例如先声明个长度为20的数组,如果存10个就浪费了空间,存25个又不够。所以引入容器,ArrayList就是一种常见的容器,容器的容量会随着存放的对象自动增多。
常用方法

例子:
public class ArrayListTest { public static void main(String[] args) { //泛型,list只能存string类型 //下面这样写可以存各种类型 //ArrayList list1 = new ArrayList(); ArrayList<String> list = new ArrayList<String>(); list.add("aaa"); list.add("bbb"); list.add("ccc"); System.out.println(list); System.out.println("之前的长度:"+list.size()); list.add("ddd"); System.out.println("新添加一个元素后的长度:"+list.size()); System.out.println(list); //contains判断容器中是否有某元素 System.out.println("是否存在aaa:"+list.contains("aaa")); //get获得指定位置的元素 System.out.println("第2个元素是:"+list.get(1)); //set替换某位置的元素 System.out.println("拿AAA替换第一个元素:"+list.set(0, "AAA")); System.out.println(list); //转化为数组,如果要转换为一个string数组, //那么需要传递一个string数组类型的对象给toArray(), //这样toArray方法才知道,你希望转换为哪种类型的数组,否则只能转换为Object数组 String []arr = new String[list.size()]; arr=(String[]) list.toArray(new String[] {}); for(String str:arr) { System.out.println("转化成数组:"+str); } //清空list list.clear(); System.out.println(list); } }
泛型
不指定泛型的容器,可以存放任何类型的元素
指定了泛型的容器,只能存放指定类型的元素以及其子类,如上面代码的 ArrayList<String> list,只能存放String类型
三种遍历集合的方法
使用for循环
方便操作集合中相关元素
使用迭代器iterator
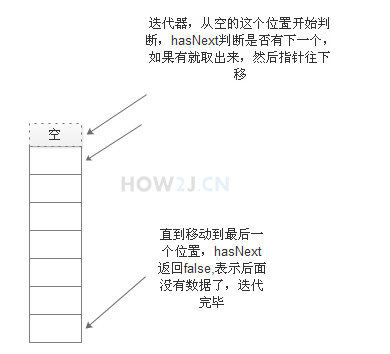
增强型for循环
使用增强型for循环可以非常方便的遍历ArrayList中的元素,这是很多开发人员的首选
不过增强型for循环也有不足:
无法用来进行ArrayList的初始化
无法得知当前是第几个元素了,当需要只打印单数元素的时候,就做不到了。 必须再自定下标变量。
代码:
public class Test { public static void main(String[] args) { ArrayList<Integer> al = new ArrayList<>(); for(int i=0;i<10;i++) { al.add(i); } System.out.println("----------for循环遍历------------"); for(int i=0;i<al.size();i++) { /*for循环遍历的好处,可以操作相关元素 * if((i+1)%8==0) { al.remove(i); continue; }*/ System.out.print(al.get(i)+","); } System.out.println(); System.out.println("----------迭代器遍历------------"); Iterator<Integer> it = al.iterator(); while(it.hasNext()) { System.out.print(it.next()+","); } System.out.println(); System.out.println("----------foreach循环遍历------------"); for(Integer i:al) { System.out.print(i+","); } }
}
二、LinkedList
LinkedList也实现了List接口,像add(),get()这些List的方法也可以使用。
Deque
特别的是 它实现了双向链表Deque,可以很方便的在头和尾进行操作;
常用方法:
addFirst()在最前面插入元素,addLast()在最后面插入元素,
getFirst(),getLast查看头部和尾部元素,
removeFirst(),removeLast()移除头部尾部元素
Queue
还实现了Queue(队列)接口,队列的特点是先进先出(FIFO)
常用方法:
offer() 在最后面添加元素
peek()查看第一个元素
pool()取出第一个元素
代码
public class LinkedListTest { public static void main(String[] args) { LinkedList<Integer> ll = new LinkedList<Integer>(); //双向链表deque Deque<Integer> d = new LinkedList<Integer>(); //队列queue Queue<Integer> q = new LinkedList<Integer>(); //初始化 for(int i=1;i<10;i++) { ll.add(i); d.add(i); q.add(i); } /* * Deque的相关方法 * * addLast * getFirst * removeFirst * */ System.out.println("deque初始值"+d); //尾部添加10 d.addLast(10); System.out.println("尾部添加:"+d); //头部添加0 d.addFirst(0); System.out.println("头部添加:"+d); //查看第一个 System.out.println("查看头部:"+d.getFirst()); //取出最后一个 d.removeLast(); System.out.println("取出最后一个:"+d); /* * Queue队列的相关方法 * offer放置队尾 * poll取出队列第一个元素 * peek查看队列第一个元素 */ System.out.println("queue初始值:"+q); q.offer(10); System.out.println("队尾添加后:"+q); q.poll(); System.out.println("使用poll去掉队首:"+q); System.out.println("使用peek查看队首:"+q.peek());
结果:

stack
stack栈是先进后出(FILO),利用Deque实现自定义Stack
先定义接口Stack
public interface Stack { //把元素推入到最后位置 public void push(Integer i); //把最后一个元素取出来 public Integer pull(); //查看最后一个元素 public Integer peek(); }
自定义MyStack实现接口
public class Mystack implements Stack { Deque<Integer> dq = new LinkedList<Integer>(); public void push(Integer i) { // 入栈,到最底部 dq.addLast(i); }
public Integer pull() { // 取出最后一个元素 return dq.removeLast(); } public Integer peek() { // 查看最后一个元素 return dq.getFirst(); } }
三、二叉树
建立二叉树:基本思想 小的在左边,大的在右边
public class Node { //左子节点 public Node leftNode; //右子节点 public Node rightNode; //值 public Object value; public void add(Object o) { //如果当前节点值为空 if(value==null) { value=o; } else {//值小于等于根的值放入左节点 if((int)o<=(int)value) { if(leftNode==null) { leftNode = new Node();} leftNode.add(o); }else {//值大于根的值 if(rightNode==null) {rightNode = new Node();} rightNode.add(o); } } } }
二叉树的遍历:前序遍历:根左右
中序遍历:左根右
后序遍历:左右根
接下来是中序遍历,顺便还能排序,这就是二叉树排序
public List<Object> values() { //中序遍历二叉树 List<Object> al = new ArrayList<>(); //左节点 if(leftNode!=null) al.addAll(leftNode.values()); //当前节点 al.add(value); //右节点 if(rightNode!=null) al.addAll(rightNode.values()); return al; }
四、HashMap
HashMap的存储方式是键值对的方式,键不能重复,值可以重复
public class HashMapTest { public static void main(String[] args) { HashMap<String, String> hm = new HashMap<>(); hm.put("name", "tom"); hm.put("age", "18"); hm.put("sex", "man"); System.out.println(hm.get("name")); } }
3种遍历方式,分别使用foreach和迭代器遍历
package com.yyt.pojo; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import java.util.Set; import java.util.concurrent.atomic.AtomicStampedReference; import javax.activation.MailcapCommandMap; public class YeYangTao { public static void main(String[] args) { HashMap<String, String> map = new HashMap<>(); map.put("001", "yyt1"); map.put("002", "yyt2"); map.put("003", "yyt3"); //ketSet遍历 foreach for(Object o:map.keySet()) { System.out.println(o); } //ketSet遍历 迭代器 Iterator it1 = map.keySet().iterator(); while(it1.hasNext()) { System.out.println(it1.next()); } //values foreach for(Object o:map.values()) { System.out.println(o); } //values 迭代器 Iterator it2 = map.values().iterator(); while (it2.hasNext()) { System.out.println(it2.next()); } //entry foreach Set<Entry<String, String>> entry = map.entrySet(); for(Entry<String, String> e:entry) { System.out.println(e.getKey()+","+e.getValue()); } //entry 迭代器 Iterator<Entry<String, String>> it = map.entrySet().iterator(); while(it.hasNext()) { Map.Entry<String, String> entry1 = it.next(); System.out.println(entry1.getKey()+","+entry1.getValue()); } } }
五、HashSet
无序,不可重复。其实它就是HashMap中的key。
它没有顺序,不能通过get()来获取元素
所以遍历用增强型for循环和Iterator迭代器
接下来用HashSet来解决一个问题:
问题:
创建一个长度是100的字符串数组
使用长度是2的随机字符填充该字符串数组
统计这个字符串数组里重复的字符串有多少种并输出重复值
思路:定义两个HashSet,利用第一个插入随机字符串数组,但是HashSet不允许重复,所以第二次遇到重复的则会插入失败,用第二个HashSet保存插入失败的元素,最后只需要统计第二个HashSet的长度和其中元素便找到了有多少种重复和重复值是什么。
代码:
public class HashSetTest { public static void main(String[] args) { //获取100个长度为2的随机字符串 String s[] = new String[100]; for(int i=0;i<s.length;i++) { s[i] = randomStr(2); } System.out.println("初始化字符串数组为:"); for(int i=0;i<s.length;i++) { System.out.print(s[i] +" "); if(i%10==9) System.out.println(); } HashSet<String> repeat =new HashSet<String>(); HashSet<String> sets =new HashSet<String>(); for(String str:s) { if(!sets.add(str)) {//当之前有重复值的时候,第二次会插入失败 repeat.add(str);//将插入失败的值保存,也就是重复值 } } System.out.println("重复的有"+repeat.size()+"个"); for(String str:repeat) { System.out.println(str); } } //获取随机字符串 public static String randomStr(int length) { Random r = new Random(); int i; String s = "qwertyuioplkjhgfdsazxcvbnmQWERTYUIOPLKJHGFDSAZXCVBNM1234567890"; char sa[]=new char[length]; for(int j=0;j<length;j++) { //26个大写字母,26个小写字母,10位数字 i = r.nextInt(26+26+10-1); sa[j]=s.charAt(i); } return new String(sa); } }
六、关系和区别
1、collection与collections
collection是一个接口,是Set,List,Queue的接口
collections是一个类,容器的工具类
常用方法
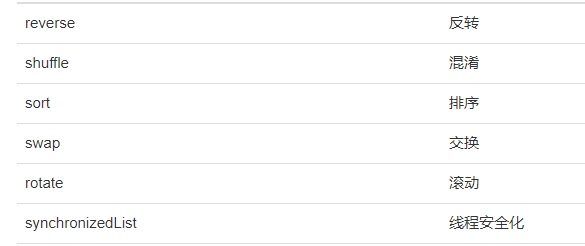
2、ArrayList与HashSet
ArrayList有序,HashSet无序
List中可以重复,Set中不能重复
3、ArrayList与LinkedList
都可以重复
ArrayList插入数据慢,删除数据慢,但它是顺序结构,定位快
LinkedList插入、删除数据快,但它是链表结构,定位慢
4、线程安全的与线程不安全的
Vector与ArrayList区别
HashTable与HashMap区别
都是前者是线程安全的类。