测试题目:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
本次测试的结果并不是很理想,hive装的匆忙,导致在测试的时候启动总是有问题,耽搁了很长的时间。
解答过程:
1.首先是对老师提供的数据进行清洗,通过图片我们可以看出
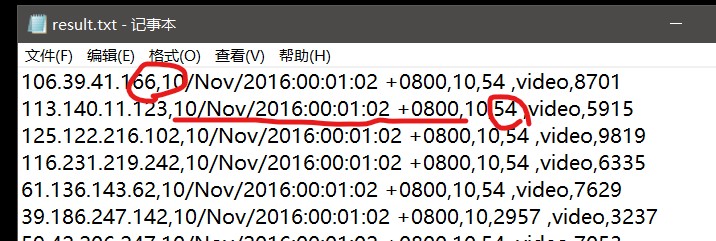
在图片中已经标出提取数据需要注意点:1.获取的时候以逗号作为分割符号,2.时间的格式需要进行修改,3.在课程编号后面有空格需要删除
所以决定在map的过程中解决这三个事情,完成提取。
public class Map extends Mapper<Object , Text , Text , NullWritable> //map将输入中的value复制到输出数据的key上,并直接输出 { public void map(Object key,Text value,Context context) throws IOException, InterruptedException //实现map函数 { //获取并输出每一次的处理过程 String line=value.toString(); String arr[]=line.split(","); //提取日期 String oldData=arr[1]; String dataTemp[] =oldData.split("/"); if(dataTemp[1].equals("Nov")) { dataTemp[1]="11"; }else { dataTemp[1]="1"; //在文件中没有除了11月以外的月份,所以其他情况就省略 } String dataYear=dataTemp[2].substring(0,4); String dataTime=dataTemp[2].substring(5,13); String newData=dataYear+"-"+dataTemp[1]+"-"+dataTemp[0]+" "+dataTime; //traffic String traffic=arr[3].replace(" ", ""); //媒体类型 String type=arr[4]; //id String id=arr[5]; //整合key //String sum="ip:"+arr[0]+",date:"+newData+",day:"+arr[2]+",traffice:"+traffic+",type:"+type+",id:"+id; String sum=arr[0]+","+newData+","+arr[2]+","+traffic+","+type+","+id; //只填写key值,value值使用nullwrite类型代替 context.write(new Text(sum), NullWritable.get()); } }
然后再hdfs中查看提取的结果:已经达到了要求

然后打开hive,将hdfs上的文件导入到hive中。首先我们需要创建相应的表:

使用导入语句(在导入的过程中,hdfs上的文件会因此被移走):LOAD DATA INPATH '/user/SuperMan/input/newresult.txt' INTO TABLE test1113 PARTITION(create_time='2019-11-13');
查看结果:

可以看到已经导入到hive中。