1. 首先我们看一看文件读取:
(1)客户端(java程序、命令行等等)向NameNode发送文件读取请求,请求中包含文件名和文件路径,让NameNode查询元数据。
(2)接着,NameNode返回元数据给客户端,告诉客户端请求的文件包含哪些块以及这些块位置(块在哪些DataNode中可以找到)。
比如:下面的数据块A在DataNode1、DataNode2、DataNode4中可以找到,这些信息就会反馈给客户端,这样客户端就知道数据块A可以在DataNode1、DataNode2、DataNode4中可以找到。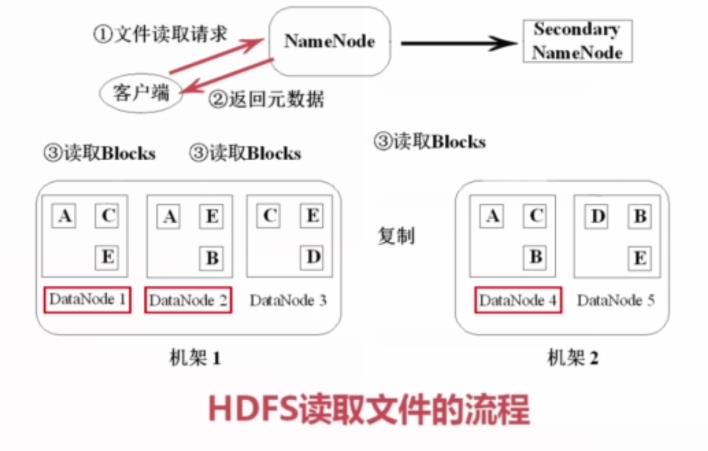
(3)接下来根据之前NameNode反馈的元数据,获知数据块的DataNode分布。这样的话,客户端就会去这些DataNode去读取Blocks,下载获取这些数据块,如下:

(4)组装数据块,形成完整的文件。
这样读取过程就完成了。
2. 接着我们看看文件的写入过程:
(1)先看看写入的总流程图,如下:
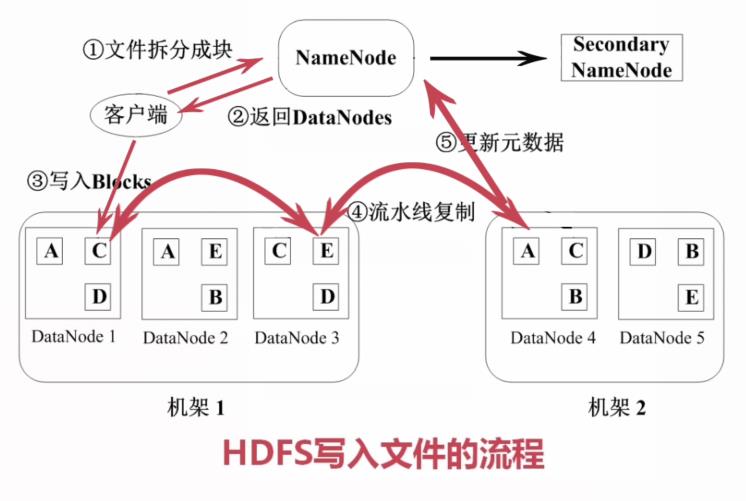
(2)写入数据第一步客户端拆分文件成块(固定大小,内容大小默认64M),客户端拆分完毕之后,通知NameNode。这个时候NameNode会返回当前在线而且拥有足够磁盘空间的DataNode的信息给客户端。客户端根据这个返回的DataNode信息,对块Blocks进行写入。注意块数据一块一块写入的,比如上面第一写入的数据块就是数据块C(写入到DataNode1)。DataNode1利用一个复制管道(流水线复制),把数据块C复制DataNode3、DataNode4上面。最后更新元数据,告诉NameNode已经完成创建一个新的数据块C的存在。