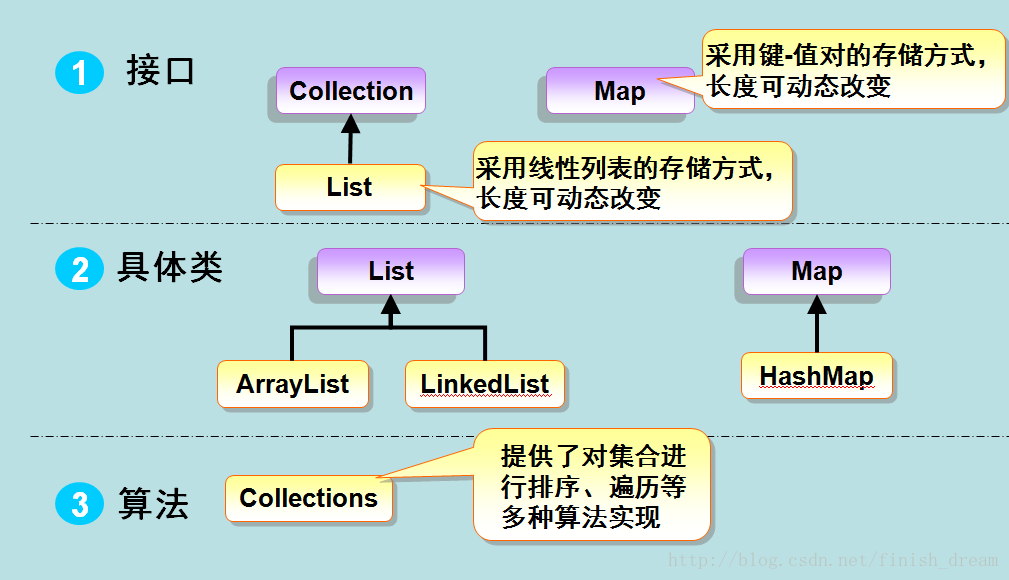
2.1、ArraList
1、自增长
容器的容量"capacity"会随着对象的增加,自动增长
只需要不断往容器里增加英雄即可,不用担心会出现数组的边界问题。
2、常用方法
关键字 | 简介 |
add | 增加 |
contains | 判断是否存在 |
get | 获取指定位置的对象 |
indexOf | 获取对象所处的位置 |
remove | 删除 |
set | 替换 |
size | 获取大小 |
toArray | 转换为数组 |
addAll | 把另一个容器所有对象加进来 |
clear | 清空 |
3、遍历
关键字 | 简介 |
for | 用for循环遍历 |
iterator | 迭代器遍历 |
for: | 用增强for循环遍历 |
2.2、HashMap
1、HashMap的存储方式——键值对
2、键不可以重复,值可以重复
2.3、HashSet
1、HashSet的元素,不能重复
2、Set中的元素没有顺序
3、遍历
Set不提供get()方法来获取指定位置的元素
所以便利需要用到迭代器,或者增强for循环
4、HashMap和HashSet的关系
通过观察HashSet的源代码
可以发现HashSet本身并没有独立的实现,而是在里面封装了一个Map
HashSet是作为Map的key而存在的
而value是一个命名为PRESENT的static的Object对象,因为是一个类属性,所以只会有一个
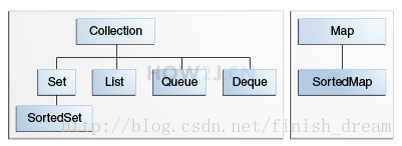
2.4、Collection
Collection是存放一个对象的,Map是存放键值对的
2.5、Collections
Collections是一个类,容器的工具类,就如同Arrays是数组的工具类
关键字 | 简介 |
reverse | 反转 |
shuffle | 混淆 |
sort | 排序 |
swap | 交换 |
rotate | 滚动 |
synchronizedList | 线程安全化 |
2.5、ArrayList和HashSet的区别
1、是否有顺序
ArrayList:有顺序
HashSet:无顺序
2、能否重复
List中的数据可以重复
Set中的数据不可以重复
重复的判断标准时:
首先看hashcode是否相同
如果hashcode不同,则认为是不同的数据
如果hashcode相同,在比较equals,如果equals相同,则是相同数据,否则是不同数据
2.6、ArrayList和LinkedList的区别
ArrayList 插入,删除数据慢
LinkedList 插入,删除数据快
ArrayList是顺序结构,所以定位很快
LinkedList是链式结构,所以定位慢
2.7、HashMap和HashTable的区别
HashMap和HashTable都实现了Map接口,都是键值对保存数据的方式
区别1:
HashMap可以存放null
HashTable不可以存放null
区别2:
HashMap不是线程安全类
HashTable是线程安全类
2.8、hashcode原理
1、hashcode概念
都有一个对应的hashcode(散列值)
比如字符串“gareen”对应的是1001 (实际上不是,这里是方便理解,假设的值)
比如字符串“temoo”对应的是1004
比如字符串“db”对应的是1008
比如字符串“annie”对应的也是1008
2、保存数据
准备一个数组,其长度是2000,并且设定特殊的hashcode算法,使得所有字符串对应的hashcode,都会落在0-1999之间
要存放名字是"gareen"的英雄,就把该英雄和名称组成一个键值对,存放在数组的1001这个位置上
要存放名字是"temoo"的英雄,就把该英雄存放在数组的1004这个位置上
要存放名字是"db"的英雄,就把该英雄存放在数组的1008这个位置上
要存放名字是"annie"的英雄,然而 "annie"的hashcode 1008对应的位置已经有db英雄了,那么就在这里创建一个链表,接在db英雄后面存放annie
3、查找数据
比如要查找gareen,首先计算"gareen"的hashcode是1001,根据1001这个下标,到数组中进行定位,(根据数组下标进行定位,是非常快速的) 发现1001这个位置就只有一个英雄,那么该英雄就是gareen.
比如要查找annie,首先计算"annie"的hashcode是1008,根据1008这个下标,到数组中进行定位,发现1008这个位置有两个英雄,那么就对两个英雄的名字进行逐一比较(equals),因为此时需要比较的量就已经少很多了,很快也就可以找出目标英雄
这就是使用hashmap进行查询,非常快原理。
这是一种用空间换时间的思维方式