前言:
不知道写什么好,绕来绕去还是写回爬虫这一块。
之前的都爬了一遍。这次爬点好用一点的网站。
0x01:
自行备好requests模块
目标站:http://tool.chinaz.com/
0x2:
代码:
import optparse
import requests
import re
import sys
from bs4 import BeautifulSoup
def main():
usage="[-z Subdomain mining]"
"[-p Side of the station inquiries]"
"[-x http status query]"
parser=optparse.OptionParser(usage)
parser.add_option('-z',dest="Subdomain",help="Subdomain mining")
parser.add_option('-p',dest='Side',help='Side of the station inquiries')
parser.add_option('-x',dest='http',help='http status query')
(options,args)=parser.parse_args()
if options.Subdomain:
subdomain=options.Subdomain
Subdomain(subdomain)
elif options.Side:
side=options.Side
Side(side)
elif options.http:
http=options.http
Http(http)
else:
parser.print_help()
sys.exit()
def Subdomain(subdomain):
print('-----------Subdomains quickly tap-----------')
url="http://m.tool.chinaz.com/subdomain/?domain={}".format(subdomain)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g = re.finditer('<td>D[a-zA-Z0-9][-a-zA-Z0-9]{0,62}D(.[a-zA-Z0-9]D[-a-zA-Z0-9]{0,62})+.?</td>', str(r))
for x in g:
lik="".join(str(x))
opg=BeautifulSoup(lik,'html.parser')
for link in opg.find_all('td'):
lops=link.get_text()
print(lops)
def Side(side):
print('--------Side of the station inquiries--------')
url="http://m.tool.chinaz.com/same/?s={}".format(side)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g=r.decode('utf-8')
ksd=re.finditer('<a href=.*?>[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+.?</a>',str(g))
for l in ksd:
ops="".join(str(l))
pods=BeautifulSoup(ops,'html.parser')
for xsd in pods.find_all('a'):
sde=re.findall('[a-zA-z]+://[^s]*',str(xsd))
low="".join(sde)
print(low)
def Http(http):
print('--------Http status query--------')
url="http://{}".format(http)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
b=r.headers
for sdw in b:
print(sdw,':',b[sdw])
if __name__ == '__main__':
main()
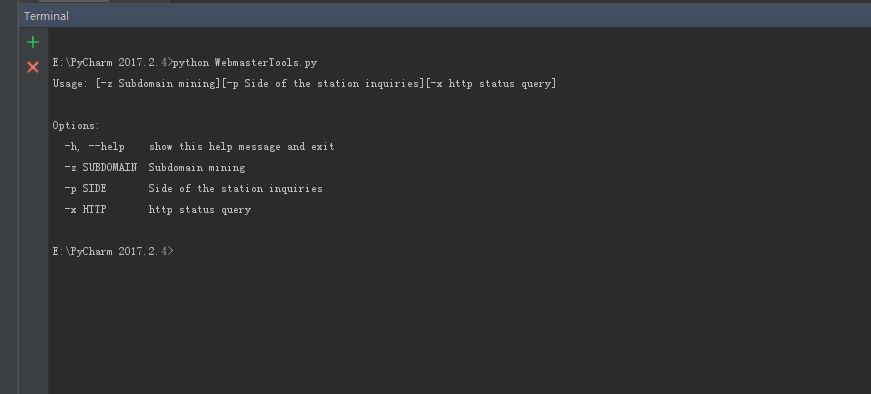
运行截图:
-h 帮助
-z 子域名挖掘
-p 旁站查询
-x http状态查询
-z 截图
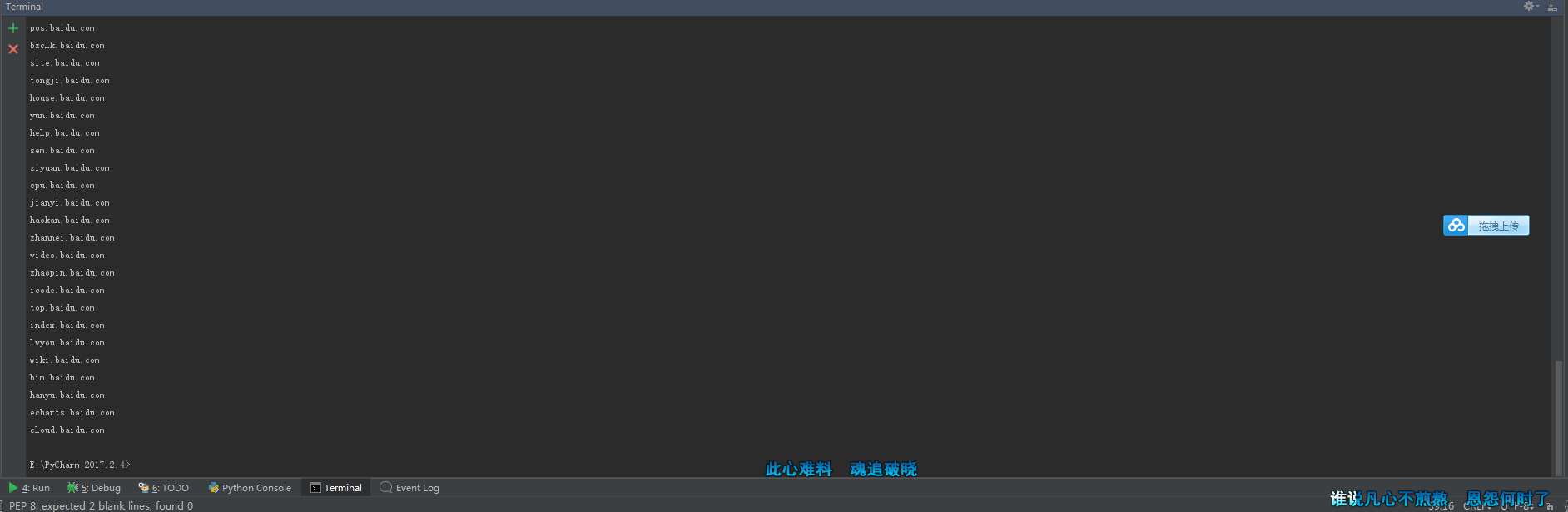
-p 截图

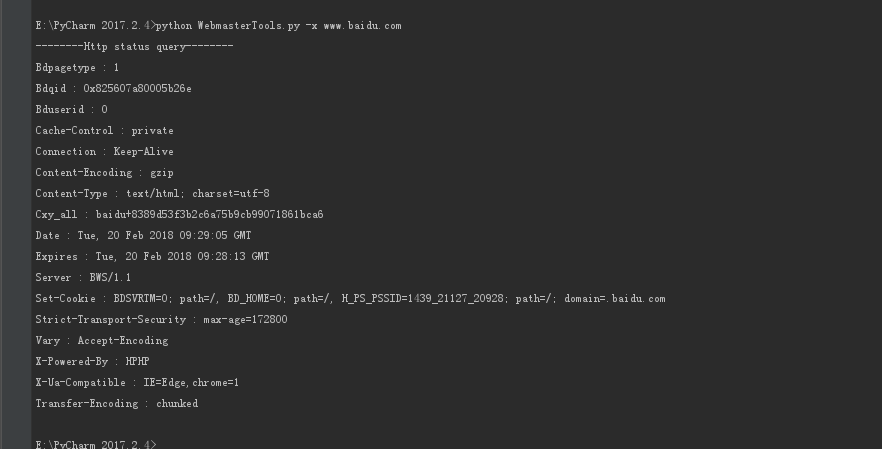
-x 截图
距离上学还有5天。啊啊啊啊啊啊啊啊啊啊啊