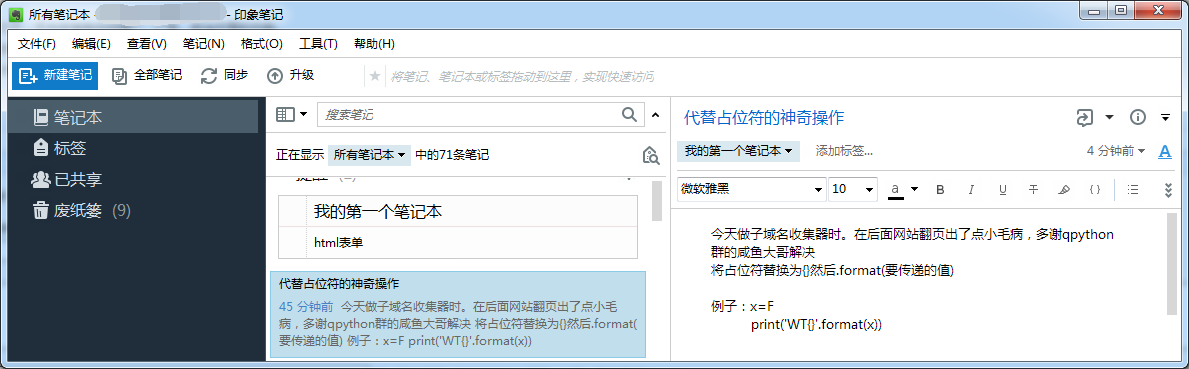
今天心血来潮做了一个子域名收集器。过程是蛋疼啊!这里先感谢一下qpython群的咸鱼大佬,在换页的时候出了点毛病,讲到后面我们就知道了。
思路:

代码开始:
我们要用到的模块是
Requests
Bs4模块里的BeautifulSoup
Time模块
如果BeautifulSoup没有
安装方法:
LINUX:sudo pip install bs4
WINDOWS:pip install bs4
Import requests
From bs4 import BeautifulSoup
Import time
For i in range(48):
I=i*10#48*10=50我们爬50页
Heads={'User-Agent': 'Mozilla/5.0(Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}#将自己伪装成浏览器
Url=”https://cn.bing.com/search?q=site%3adgjy.net&qs=n&sp=-1&pq=site%3adgjy.net&sc=2-11&sk=&cvid=C1A7FC61462345B1A71F431E60467C43&toHttps=1&redig=3FEC4F2BE86247E8AE3BB965A62CD454&pn=2&first={}&FORM=PERE”.format(i)#占位符会报错
#解析:q=你要搜索的东西 first=页数
First=1为第一页
First=10为第二页
以此类推
Html=request.urlopen(url,headers=heads)
soup=BeautifulSoup(html.content,'html.parser')
Job=soup.findAll(‘h2’)#列出h2标签
For i in job:
Time.sleep(3)#延迟3秒,防止被必应发现
Print(i.a.get(‘href’))
运行结果:
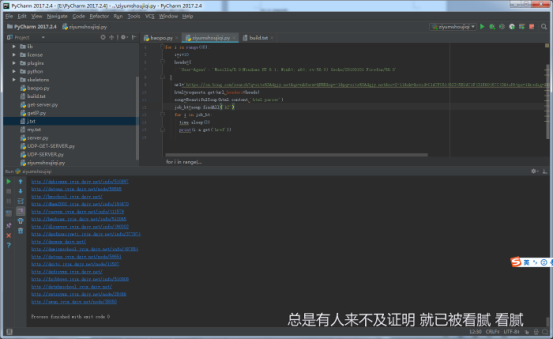
总结:
脚本代码:
import requests
from bs4 import BeautifulSoup
import time
for i in range(48):
i=i*10
heads={
'User-Agent': 'Mozilla/5.0(Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}
url='https://cn.bing.com/search?q=site%3Adgjy.net&qs=n&form=QBRE&sp=-1&pq=site%3Adgjy.net&sc=2-11&sk=&cvid=C1A7FC61462345B1A71F431E60467C43&toHttps=1&redig=3FEC4F2BE86247E8AE3BB965A62CD454&pn=2&first={}&FROM=PERE'.format(i)
html=requests.get(url,headers=heads)
soup=BeautifulSoup(html.content,'html.parser')
job_bt=soup.findAll('h2')
for i in job_bt:
time.sleep(3)
print(i.a.get('href'))