url模块:解析url地址的模块
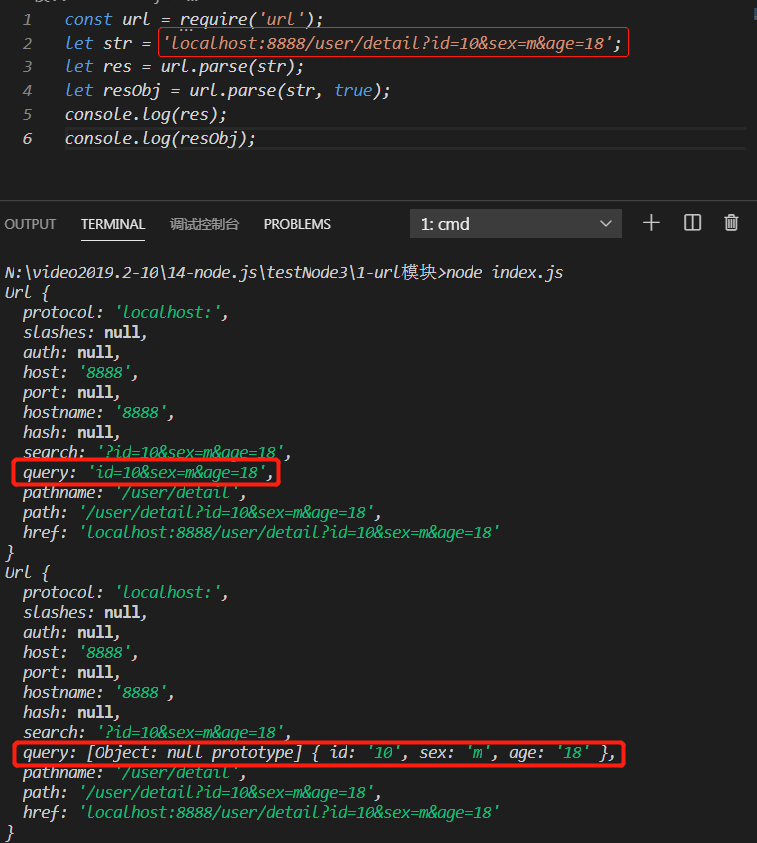
1)url.parse(url字符串,参数二) => 用于解析url地址中的各个数据
参数二:是否解析queryString,默认false
2)url对象是用来解析url地址的,可以获取url地址的各个部分,但是内部不会解析查询字符串的,当将第二个参数设置为true时,是去调用了queryString.parse() 将查询字符串(url中的query属性)转成了对象。
querystring模块:用于把查询字符串解析为对象 querystring.parse(str)

url模块是把整个url地址进行解析,querystring模块是只针对查询字符串(id=xxx&age=18)进行解析
JSON.stringify(obj,null,缩进空格数):
里面有三个参数:
(1)要转为字符串的对象 -> 必填参数
(2)回调函数(很少用) -> 可选参数
(3)缩进空格数 -> 可选参数:就是把要转为对象字符串的对象按照传入的缩进空格数字进行格式化。
服务端重定向
- HTTP 状态码说明
- 301 和 302
- 说明:服务端可以通过HTTP状态码让浏览器中的页面重定向
res.writeHead(302, {
'Location': '/'
})
res.end()
post传递数据的原理: 
POST请求参数的处理
- 说明:POST请求可以发送大量数据,没有大小限制
// 接受POST参数
var postData = []
// 给req注册一个data事件, 只要浏览器给服务器发送post请求,data事件就会触发
// post请求发送的数据量可以很大, 这个data事件会触发多次,一块一块的传输
// 要把所有的chunk都拼接起来
// data事件:用来接受客户端发送过来的POST请求数据
var result = "";
req.on('data', function (chunk) {
result += chunk;
})
// end事件:当POST数据接收完毕时,触发
req.on('end', function () {
cosnole.log(result);
})
模块化的标准:
让模块拥有更好的通用性
AMD: 异步模块定义 require.js
依赖前置:在一开始就将所有的依赖项全部加载
CMD: 通用模块定义 sea.js
依赖延迟:在需要的时候才去加载依赖项
commonJS: nodejs 服务端的模块,CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。
AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。
但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。基本概念
在nodejs中,应用由模块组成,nodejs中采用commonJS模块规范。
- 一个js文件就是一个模块
- 每个模块都是一个独立的作用域,在这个而文件中定义的变量、函数、对象都是私有的,对其他文件不可见。

node中模块分类
- 1 核心模块
- 由 node 本身提供,不需要单独安装(npm),可直接引入使用
- 2 第三方模块
- 由社区或个人提供,需要通过npm安装后使用
- 3 自定义模块
- 由我们自己创建,比如:tool.js 、 user.js
核心模块
- fs:文件操作模块
- http:网络操作模块
- path:路径操作模块
- url: 解析地址的模块
- querystring: 解析参数字符串的模块
- 基本使用:1 先引入 2 再使用
// 引入模块
var fs = require('fs');
第三方模块
- 第三方模块是由 社区或个人 提供的
- 比如:mime模块/art-template/jquery...
- 基本使用:1 先通过npm下载 2 再引入 3 最后使用
用户自定义模块
- 由开发人员创建的模块(JS文件)
- 基本使用:1 创建模块 2 引入模块
- 注意:自定义模块的路径必须以
./获取../开头
// 加载模块
require('./a') // 推荐使用,省略.js后缀!
require('./a.js')
引入模块时,模块的查找规则:
引入第三方模块时的查找规则(以mime包为例)
- 先基于当前文件模块所属目录找 node_modules 目录
- 如果找到,则去该目录中找 mime 目录
- 如果找到 mime 目录,则找该目录中的 package.json 文件
- 如果找到 package.json 文件,则找该文件中的 main 属性
- 如果找到 main 属性,则拿到该属性对应的文件路径
- 如果找到 mime 目录之后如果找不到 index 或者找不到 mime 或者找不到 node_modules
- 发现没有 package.json
- 或者 有 package.json 没有 main 属性
- 或者 有 main 属性,但是指向的路径不存在
- 则 node 会默认去看一下 mime 目录中有没有 index.js index.node index.json 文件
- 则进入上一级目录找 node_moudles 查找规则同上
- 如果上一级还找不到,继续向上,一直到当前文件所属磁盘根目录
- 如果最后到磁盘根目录还找不到,最后报错:
can not find module xxx
CommonJS 规范参考文档
总结:当多个项目文件夹使用共用一些模块时,在开发时候,把node_modules放在与这些文件夹平级,不用每个项目里都放一个自己的node_modules了,节省体积。
模块的导入与导出
模块导入
- 通过
require("fs")来加载模块:require命令用于加载文件,后缀名默认为.js。 - 如果是第三方模块,需要先使用npm进行下载
- 如果是自定义模块,需要加上相对路径
./或者../,可以省略.js后缀,如果文件名是index.js那么index.js也可以省略。 - 模块可以被多次导入,但是只会在第一次加载
模块导出
- 在模块的内部,
module变量代表的就是当前模块,它的exports属性就是对外的接口,加载某个模块,加载的就是module.exports属性,这个属性指向一个空的对象。
//module.exports指向的是一个对象,我们给对象增加属性即可。
//module.exports.num = 123;
//module.exports.age = 18;
//通过module.exports也可以导出一个值,但是多次导出会覆盖
module.exports = '123';
module.exports = "abc";
module.exports与exports
exports是module.exports的引用- 为了方便,Node为每个模块提供一个exports变量,指向module.exports。这等同在每个模块头部,有一行这样的命令:var exports = modules.exports
- 注意:给
module.exports赋值会切断与exports之间的联系- 1 直接添加属性两者皆可
- 2 赋值操作时,只能使用
module.exports
console.log( module.exports === exports ) // ==> true
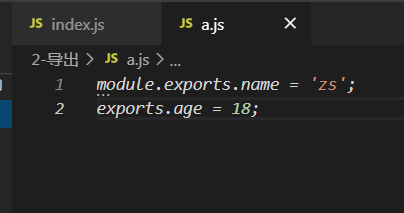
// 等价操作
module.exports.num = 123
exports.num = 123
module.exports与exports以增加属性的方式导出,在另一个模块引入时,都会拿到两者添加的属性
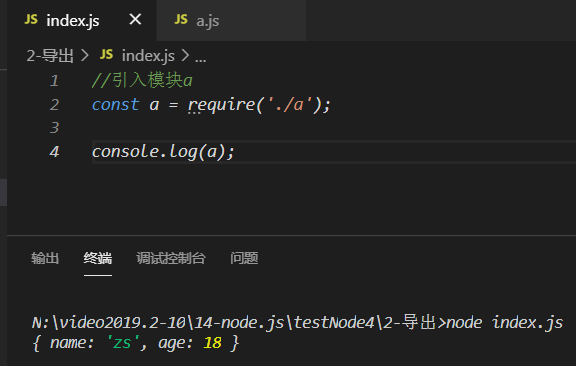
// 赋值操作:
module.exports = 基本数据类型or对象数据类型exports = 基本数据类型or对象数据类型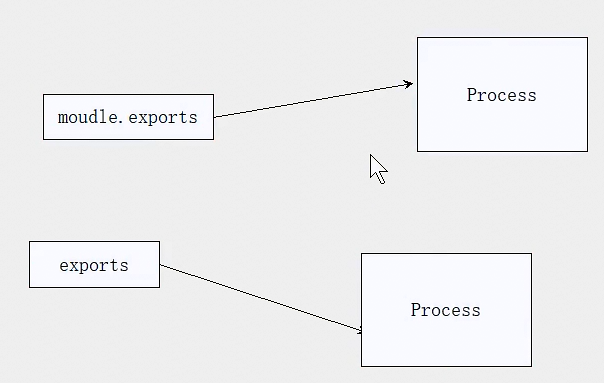
当有exports = 要导出数据 和 module.exports = 要导出数据,同时存在一个模块时候,以module.exports导出为准。


所以不要使用exports = { } 导出,都用module.exports = { } 导出
模块化思想:
之前用的都是别人写好的模块: fs、http、mime .....
模块化,把相同的功能或者代码划分到一个模块,在实际开发过程中,代码结构更加清晰,项目更加方便维护。
CommonJS的规范:
1.模块的缓存
第一次加载某个模块时,Node会缓存该模块。以后再加载该模块,就直接从缓存取出该模块的module.exports属性。
如果想要多次执行某个模块,可以让该模块输出一个函数,然后每次require这个模块的时候,重新执行一下输出的函数。
所有缓存的模块保存在require.cache之中,如果想删除模块的缓存,可以像下面这样写。

注意,缓存是根据绝对路径识别模块的,如果同样的模块名,但是保存在不同的路径,require命令还是会重新加载该模块。
2.模块的循环加载
如果发生模块的循环加载,即A加载B,B又加载A,则B将加载A的不完整版本。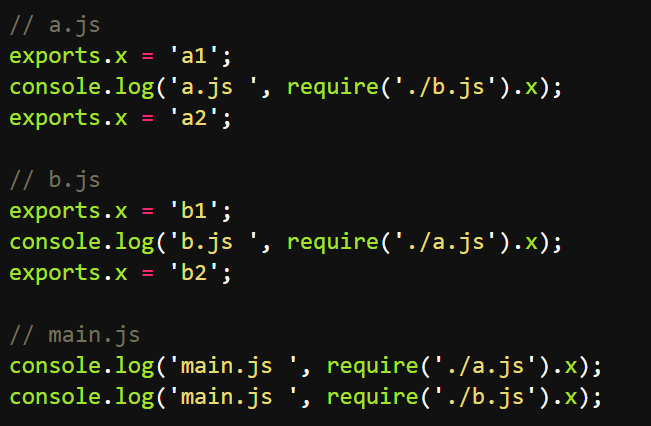 输出--->
输出---> 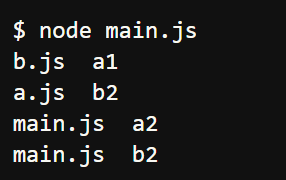
上面代码是三个JavaScript文件。其中,a.js加载了b.js,而b.js又加载a.js。这时,Node返回a.js的不完整版本,如上右小图。
修改main.js,再次加载a.js和b.js
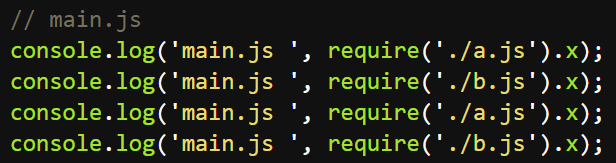 输出---->
输出----> 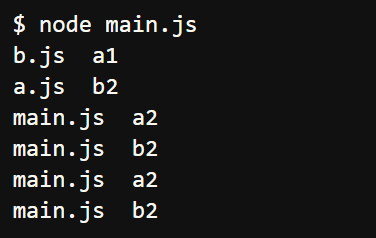
上面代码中,第二次加载a.js和b.js时,会直接从缓存读取exports属性,所以a.js和b.js内部的console.log语句都不会执行了。
3.require.main
require方法有一个main属性,可以用来判断模块是直接执行,还是被调用执行。
直接执行的时候(node module.js),require.main属性指向模块本身。通过 require.main === modele ,为true表示当前模块是直接执行的,反之是被别的模块调用执行。
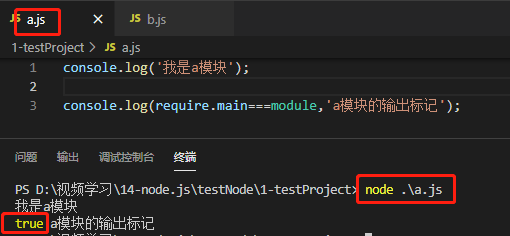
示例1:
a.js中判断打印: require.main === modele
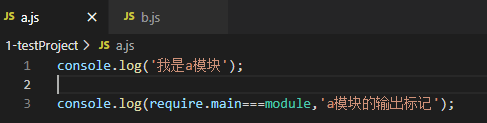
a.js中引入,并且在b模块中运行:发现a中打印require.main ==== module 输出是false,说明a模块是被调用执行的,然而事实的确如此,在b中被调用执行的。
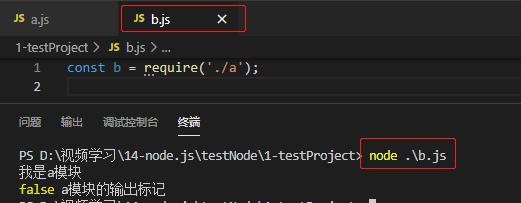
示例2:
在a.js中自己执行:输出为true的话就说明就是直接执行的,结果的确如此。
4.模块的加载机制
CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。请看下面这个例子。
下面是一个模块文件lib.js。
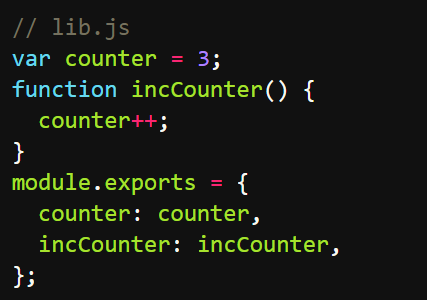
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。然后,加载上面的模块。
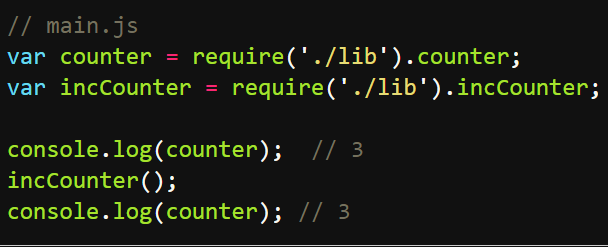
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。