第二章节
数据类型和文件类型
2.1 上章补充-变量的创建过程
2.1.1
(变量名指向内存地址)
查询内存地址>>>id(name)
python解释器有自动垃圾回收机制,自动隔一段时间把没有跟变量关联的内存数据回收
2.1.2 变量的指向关系
name = Alex
name1 = name
name1= Alex
如果这个时候,修改name的值
name = Jake
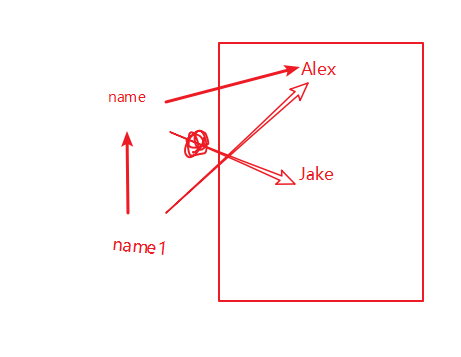
>>>name1 = Alex
如何判断一个值是不是字符串
python 中有很多数据类型,查看一个数据的类型的方法是type()
type(name),type(age)
type(name) is str
2.2 上章补充-身份运算和None
None 什么也没有
name = None
age = None
weight = None
if name is None:
print("请输入名字")
#为什么不用==
不符合python开发规范
三元运算
d= a if a > 15 else b
d = 值1 if 条件A else 值32
如果条件A成立,就取左边的值1,否则取值2
2.3 细讲数据类型-列表
列表的特点:
1.可存放多个值
2.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
3.可修改制定索引位置对应的值,可变
列表的增加操作
追加,数据会追加到尾部 append

插入,可插入任何位置 insert

合并,可以把另一外列表的值合并起来 extend

n2=["a,"b,"c"]
names = ["1","2","3","4"]
names.extend(n2)= ["1","2","3","4","a,"b,"c"]
列表的嵌套
insert

删除操作
del 直接删除

pop 删 【删除并返回最后一个值】【删除指定元素】

# name.pop() 如果列表内没有元素为空,再执行pop就会报错
clear 清空

remove
从左到右的第一个,如果有两个,则会删除从左到右的第一个
如果元素内没有,则报错
修改操作
赋值

查操作

如果查询的元素不在列表里,则会报错
切片
切片就像切面包,可以同时取出元素的多个值

切片的特性是顾头不顾尾,即start的元素会被包含,end-1是实际取出来的值
(a[1:5],其实就是从第二个切到第四个)
倒着切
>>>a=[1,2,3,4,5,6,7,8,0]
>>>a [-5:-1]
>>>a=[5,6,7,8]
步长
步长:步子的长度

步长-1代表真正的从右往左走
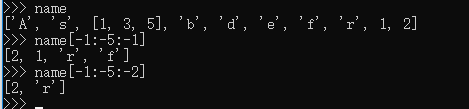
列表的反转
-步长,即可实现列表的反转
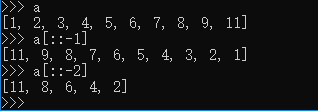
字符串的反转
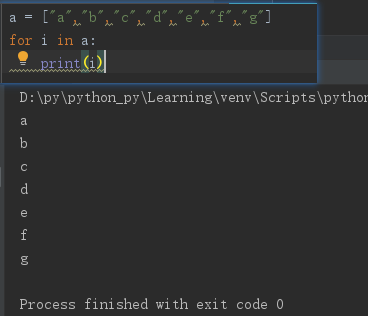
for循环
2.4 细讲数据类型-元祖
特点:
不可变,只读列表;
name=("","","",)
2.5 细讲数据类型-字符串
2.6 细讲数据类型-字典
1.字典的定义:{key1:value1,key2:value2}
2.字典的特性:
1.key-value结构
2.key必须可hash,且必须为不可变数据类型、必须唯一
3.可存放任意多个值,可修改,可以不唯一
4.无序
字典的创建
1、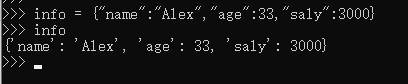
2、dict


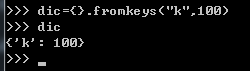
3.fromkeys
{}.fromkeys(seq,100)#不指定100默认为None

info= {“name”= "py","age"= 23}
d= {1,2,3,"Alex"}
字典中items()的用法:
将字典以列表返回可遍历的(键,值)元祖数组
d = {1:'a',2:'b',3:'c'}
print(d.items())
输出结果:
dict_items([(1, 'a'), (2, 'b'), (3, 'c')])
dict.keys()函数:以列表返回一个字典所有的键
d = {1:'a',2:'b',3:'c'}
print(dict.keys(d))
输出结果:
dict_keys([1, 2, 3])
dict.values()函数:以列表返回字典中的所有值
2.7 细讲数据类型-集合
集合的元素有三个特性:
1. 确定性
2.互异性
3.无序性
集合的关系运算
包含关系
in not in 判断元素是否在集合内
== != 判断两个集合是否相等
两个集合之间一般有是三种关系:相交,包含,不相交
set.isdisjoint() 判断两个集合是不是相交
set.issuperset() 判断两个几个是不是包含其他集合,等同于a>=b
set.issubset() 判断集合是不是被其他集合包含 等同于a<=b
集合的常用操作
元素的增加
单个元素的增加:add(),add类似于列表的append
>>> a = {1,2}
>>> a.add("hello")
>>> a
{1, 2, 'hello'}
>>>
对序列的增加:update()
>>> a = {1,2}
>>> a.update([3,4],[1,2,7])
>>> a
{1, 2, 3, 4, 7}
>>>
元素的删除
1.元素不在原集合中时:
set.discard() 不会抛出异常
a = {1,2}
a.update([3,4],[1,2,7])
a.update("hello")
print(a)
a.discard(1) #元素在集合内
print(a)
a.discard(8) #元素不在集合内
print(a)
输出结果:
{'l', 1, 2, 3, 4, 'o', 7, 'e', 'h'}
{'l', 2, 3, 4, 'o', 7, 'e', 'h'}
{'l', 2, 3, 4, 'o', 7, 'e', 'h'}
set.remove() 会抛出keyerror错误
a = {1,2}
a.update([3,4],[1,2,7])
a.update("hello")
print(a)
a.remove(7)
print(a) #元素在集合内
a.remove("x") #元素不在集合内
print(a)
输入结果:
Traceback (most recent call last):
File "D:/py/test/第四章/homework/test.py", line 7, in <module>
a.remove("x") #元素不在集合内
KeyError: 'x'
{1, 2, 3, 4, 7, 'h', 'l', 'o', 'e'}
{1, 2, 3, 4, 'h', 'l', 'o', 'e'}
pop() 由于集合是无需的,pop返回的结果不能确定,且当集合为空是调用pop会抛出keyerror错误
a = {1,2}
a.update([3,4],[1,2,7])
a.update("hello")
print(a)
a.pop(9) #不在集合内
print(a)
输出结果:
Traceback (most recent call last):
File "D:/py/test/第四章/homework/test.py", line 5, in <module>
a.pop(9)
TypeError: pop() takes no arguments (1 given)
{1, 2, 3, 4, 7, 'h', 'l', 'o', 'e'}
a = {1,2}
a.update([3,4],[1,2,7])
a.update("hello")
print(a)
a.pop()
print(a)
输出结果:
{1, 2, 3, 4, 'l', 7, 'h', 'e', 'o'}
{2, 3, 4, 'l', 7, 'h', 'e', 'o'}
chear() 清空集合
a = {1,2}
a.update([3,4],[1,2,7])
a.update("hello")
print(a)
a.clear()
print(a)
输出结果:
{1, 2, 3, 4, 7, 'h', 'e', 'o', 'l'}
set()
2.8 秒懂二进制
2.9 秒懂十六进制
2.10 字符编码之文字是如何显示的
2.11 hash是个什么东西
2.12 用python操作文件
2.13本章练习题&作业