转载:https://www.cxybb.com/article/jiaoyangwm/114845483 建议前往,这里仅当学习
文章目录
一、Detectron2 操作介绍
Detectron2代码链接:https://github.com/facebookresearch/detectron2
Detectron2说明文档:https://detectron2.readthedocs.io/index.html
安装之后要编译:
# 编译
python setup.py build develop
1.1 训练
1、训练有两个脚本, tools/plain_train_net.py 提供的默认参数更少
- tools/plain_train_net.py
- tools/train_net.py
2、训练之前要设置对应数据集
https://github.com/facebookresearch/detectron2/blob/master/datasets/README.md
3、训练
# 单GPU
cd toos/
./train_net.py \
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
--num-gpus 1 SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025
# 多GPU
cd tools/
./train_net.py --num-gpus 8 \
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml
4、评估模型性能
./train_net.py \
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
--eval-only MODEL.WEIGHTS /path/to/checkpoint_file
更多的信息可以使用下面的命令查看:
./train_net.py -h
1.2 测试
1、从 model zoo 下载官方训好的模型
2、测试demo
# demo测试
cd demo/
python demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--input input1.jpg input2.jpg \
[--other-options]
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
# 可修改细节
- To run on your webcam, replace --input files with --webcam.
- To run on a video, replace --input files with --video-input video.mp4.
- To run on cpu, add MODEL.DEVICE cpu after --opts.
- To save outputs to a directory (for images) or a file (for webcam or video), use --output.
1.3 数据及格式要求
https://detectron2.readthedocs.io/en/latest/tutorials/builtin_datasets.html
1.4 Load/Save model
1、detectron2 的 Models (和其他 sub-models) 以如下形式建立:
build_model, build_backbone, build_roi_heads:
from detectron2.modeling import build_model
model = build_model(cfg) # returns a torch.nn.Module
2、Load/Save checkpoint:
from detectron2.checkpoint import DetectionCheckpointer
DetectionCheckpointer(model).load(file_path_or_url) # load a file, usually from cfg.MODEL.WEIGHTS
checkpointer = DetectionCheckpointer(model, save_dir="output")
checkpointer.save("model_999") # save to output/model_999.pth
Detectron2 的 checkpointer 将模型以 .pth 和 .pkl 的形式保存,可以使用 torch.load / torch.save 来处理前者,使用pickle.dump / pickle.load 来处理后者。
1.5 模型输入形式
outputs = model(inputs) # inputs is a list[dict]
The dict may contain the following keys:
- “image”: Tensor in (C, H, W) format. The meaning of channels are defined by cfg.INPUT.FORMAT. Image normalization, if any, will be performed inside the model using cfg.MODEL.PIXEL_{
MEAN,STD}.
- “height”, “width”: the desired output height and width, which is not necessarily the same as the height or width of the image field. For example, the image field contains the resized image, if resize is used as a preprocessing step. But you may want the outputs to be in original resolution. If provided, the model will produce output in this resolution, rather than in the resolution of the image as input into the model. This is more efficient and accurate.
- “instances”: an Instances object for training, with the following fields:
- “gt_boxes”: a Boxes object storing N boxes, one for each instance.
- “gt_classes”: Tensor of long type, a vector of N labels, in range [0, num_categories).
- “gt_masks”: a PolygonMasks or BitMasks object storing N masks, one for each instance.
- “gt_keypoints”: a Keypoints object storing N keypoint sets, one for each instance.
- “sem_seg”: Tensor[int] in (H, W) format. The semantic segmentation ground truth for training. Values represent category labels starting from 0.
- “proposals”: an Instances object used only in Fast R-CNN style models, with the following fields:
- “proposal_boxes”: a Boxes object storing P proposal boxes.
- “objectness_logits”: Tensor, a vector of P scores, one for each proposal.
For inference of builtin models, only “image” key is required, and “width/height” are optional.
1.6 模型输出
训练模式:a dict[str->ScalarTensor] with all the losses.
推理模式: a list[dict], one dict for each image.
每个dict包含内容如下:
- “instances”: Instances object with the following fields:
- “pred_boxes”: Boxes object storing N boxes, one for each detected instance.
- “scores”: Tensor, a vector of N confidence scores.
- “pred_classes”: Tensor, a vector of N labels in range [0, num_categories).
- “pred_masks”: a Tensor of shape (N, H, W), masks for each detected instance.
- “pred_keypoints”: a Tensor of shape (N, num_keypoint, 3). Each row in the last dimension is (x, y, score). Confidence scores are larger than 0.
- “sem_seg”: Tensor of (num_categories, H, W), the semantic segmentation prediction.
- “proposals”: Instances object with the following fields:
- “proposal_boxes”: Boxes object storing N boxes.
- “objectness_logits”: a torch vector of N confidence scores.
- “panoptic_seg”: A tuple of (pred: Tensor, segments_info: Optional[list[dict]]). The pred tensor has shape (H, W), containing the segment id of each pixel.
If segments_info exists, each dict describes one segment id in pred and has the following fields:
- “id”: the segment id
- “isthing”: whether the segment is a thing or stuff
- “category_id”: the category id of this segment.
If a pixel’s id does not exist in segments_info, it is considered to be void label defined in Panoptic Segmentation.
If segments_info is None, all pixel values in pred must be ≥ -1. Pixels with value -1 are assigned void labels. Otherwise, the category id of each pixel is obtained by category_id = pixel // metadata.label_divisor.
1.7 config usage
from detectron2.config import get_cfg cfg = get_cfg() # obtain detectron2's default config cfg.xxx = yyy # add new configs for your own custom components cfg.merge_from_file("my_cfg.yaml") # load values from a file cfg.merge_from_list(["MODEL.WEIGHTS", "weights.pth"]) # can also load values from a list of str print(cfg.dump()) # print formatted configs
二、Detectron2 代码结构介绍

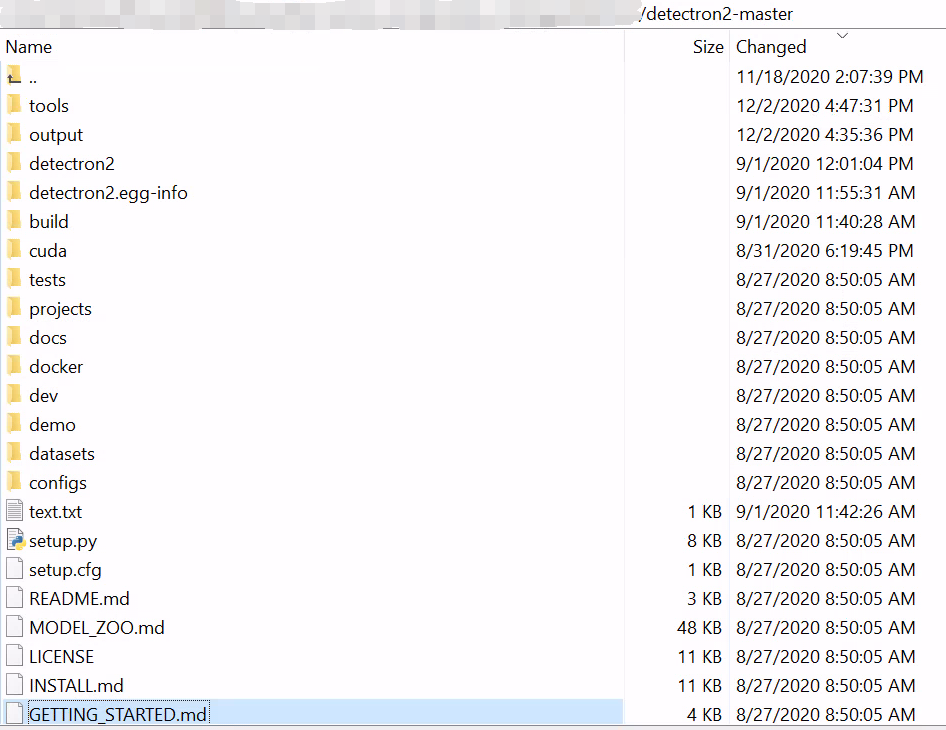
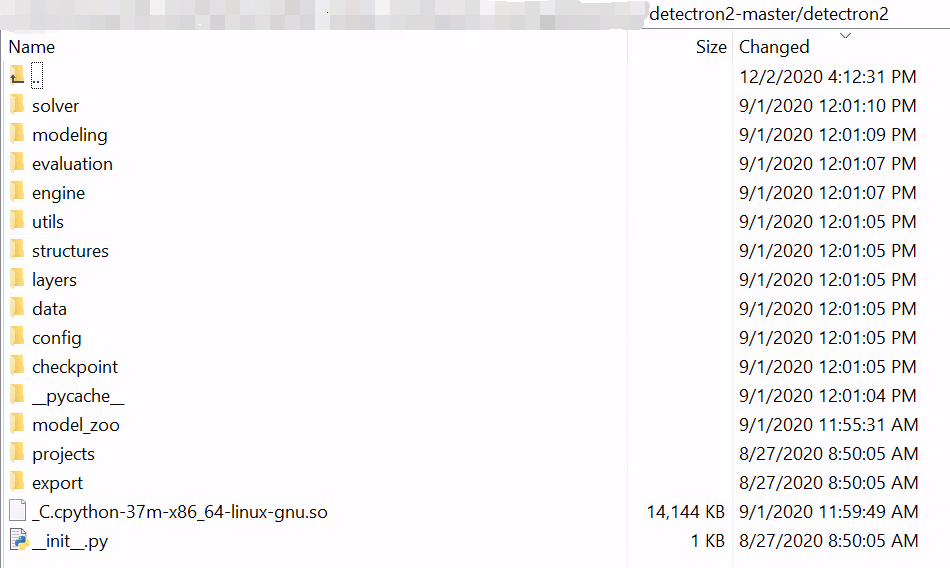
- engine:整合数据和model的过程,实现训练、测试
- data:model的输入
- modeling:solver(optimizer)的输入
- solver:优化器
- layers:构成modeling的基本层
- evaluation:评估
- config:读取配置文件
- projects:工程示例
- checkpoint:存储和加载模型权重
2.1 数据
./detectron2/data/

1、读取图片
./data/common.py
2、数据增强
./data/common.py
3、转化为batch
./data/build.py
4、修改数据路径
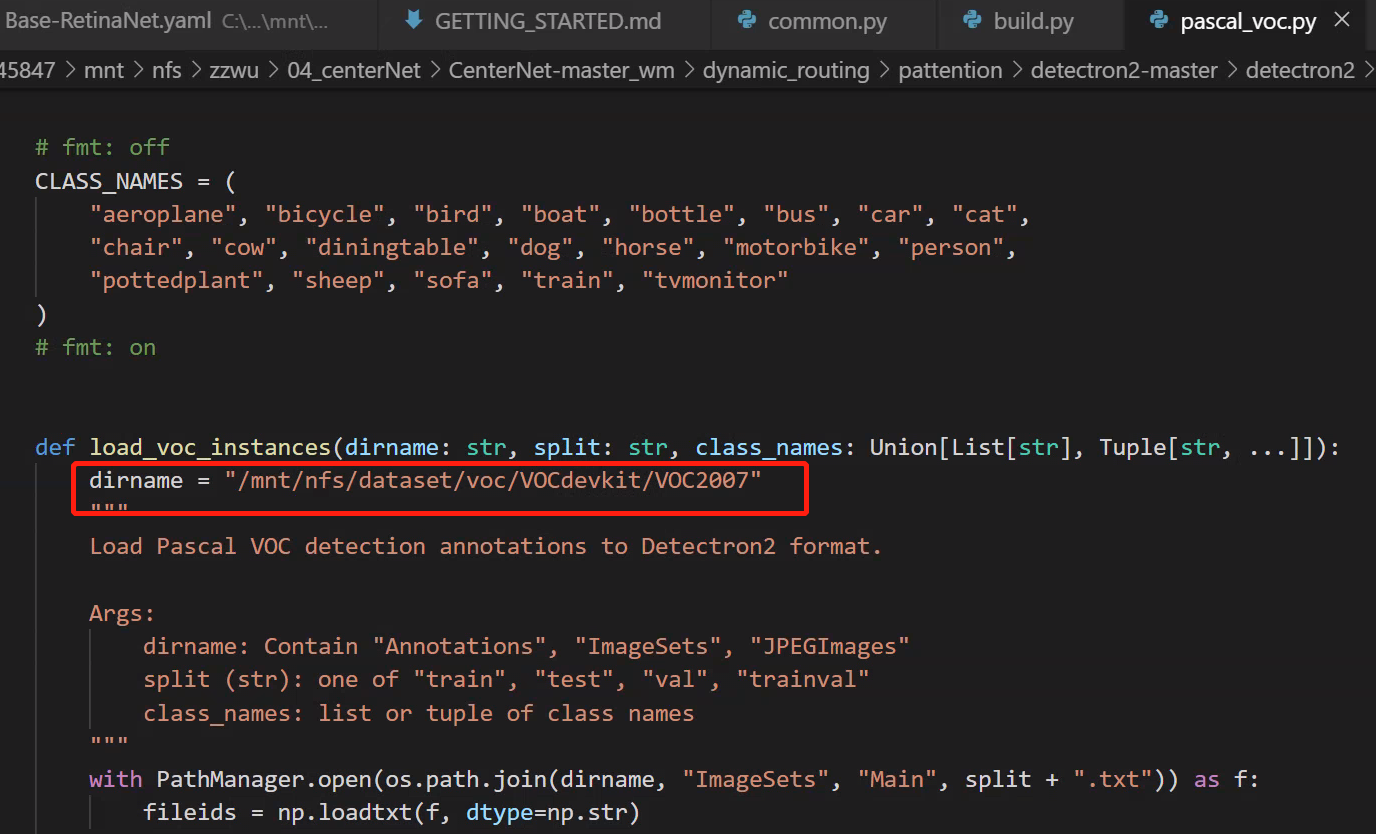
./data/datasets/

-
pascal voc
-
coco (
register_coco.py & coco.py)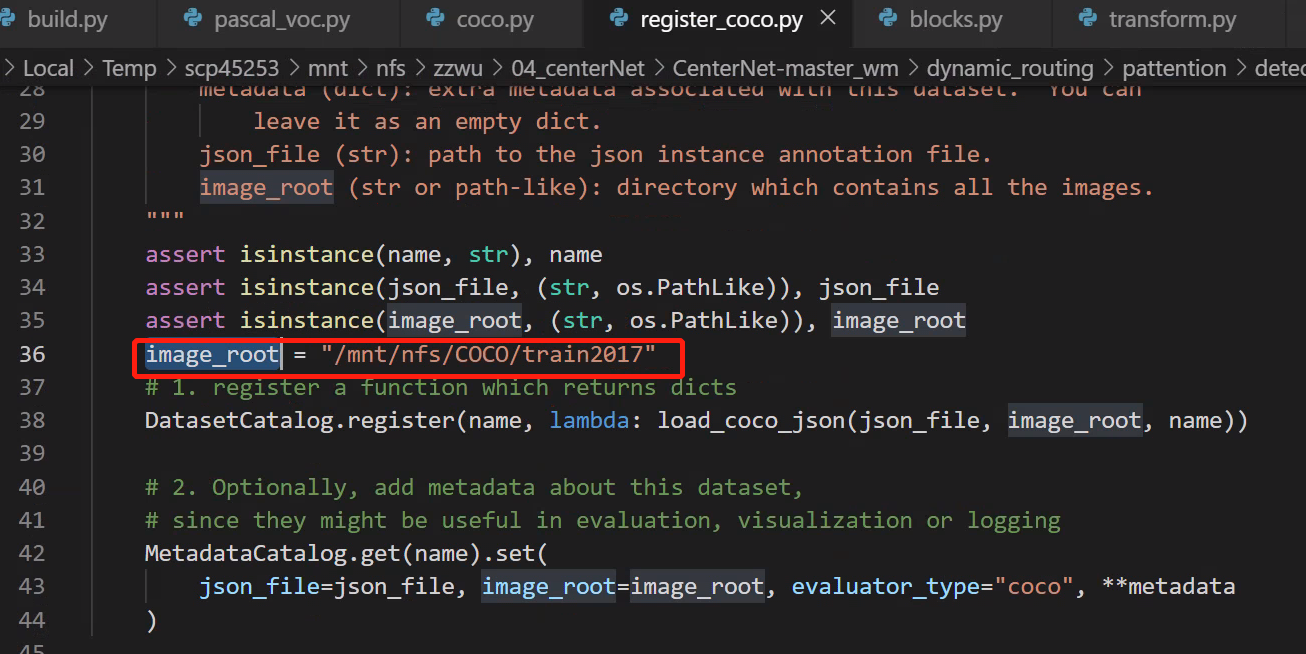
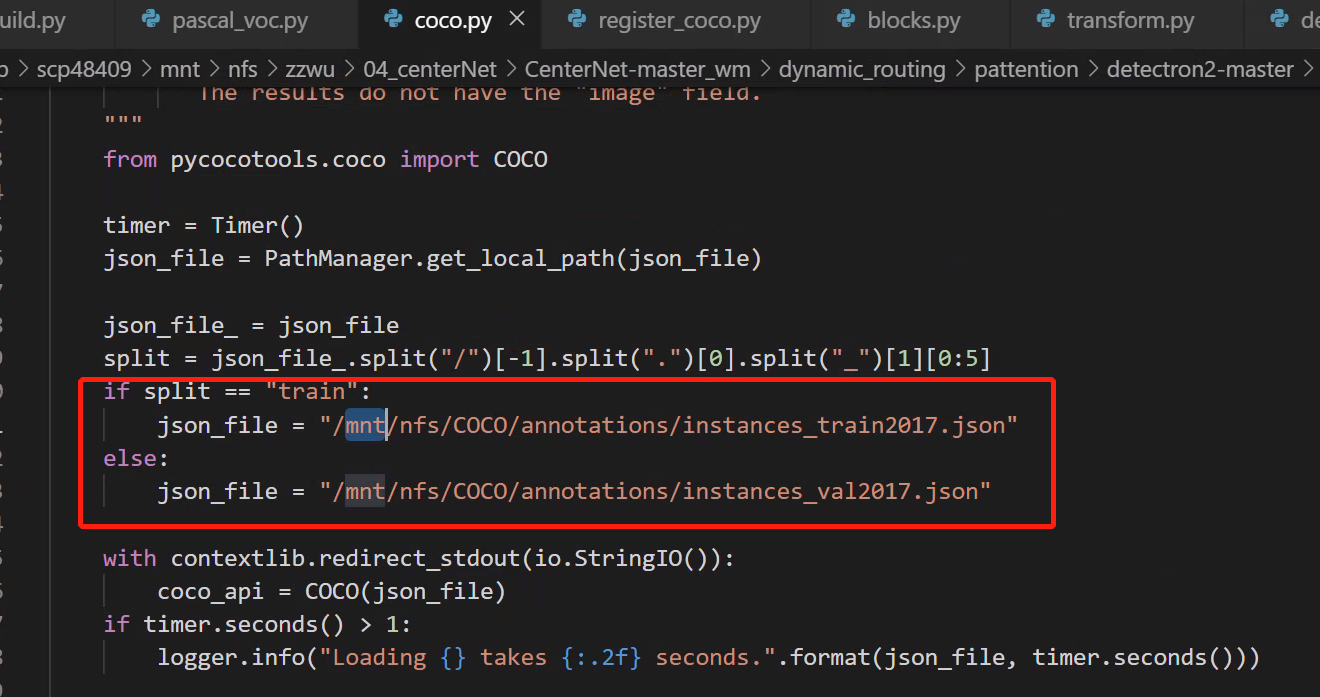
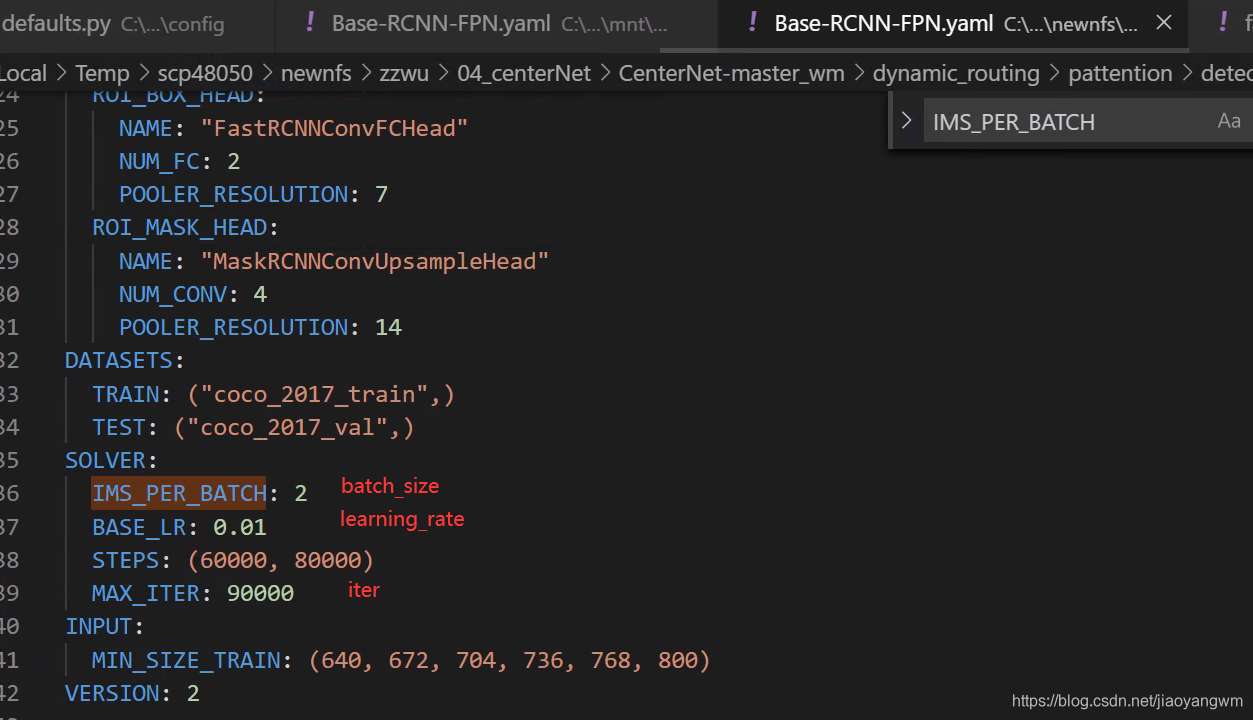
修改超参数:
./configs/Base-RCNN-FPN.yaml
2.2 模型
./detectron2/modeling/

1、backbone
# backbone的抽象基类
# ./modeling/backbone/backbone.py
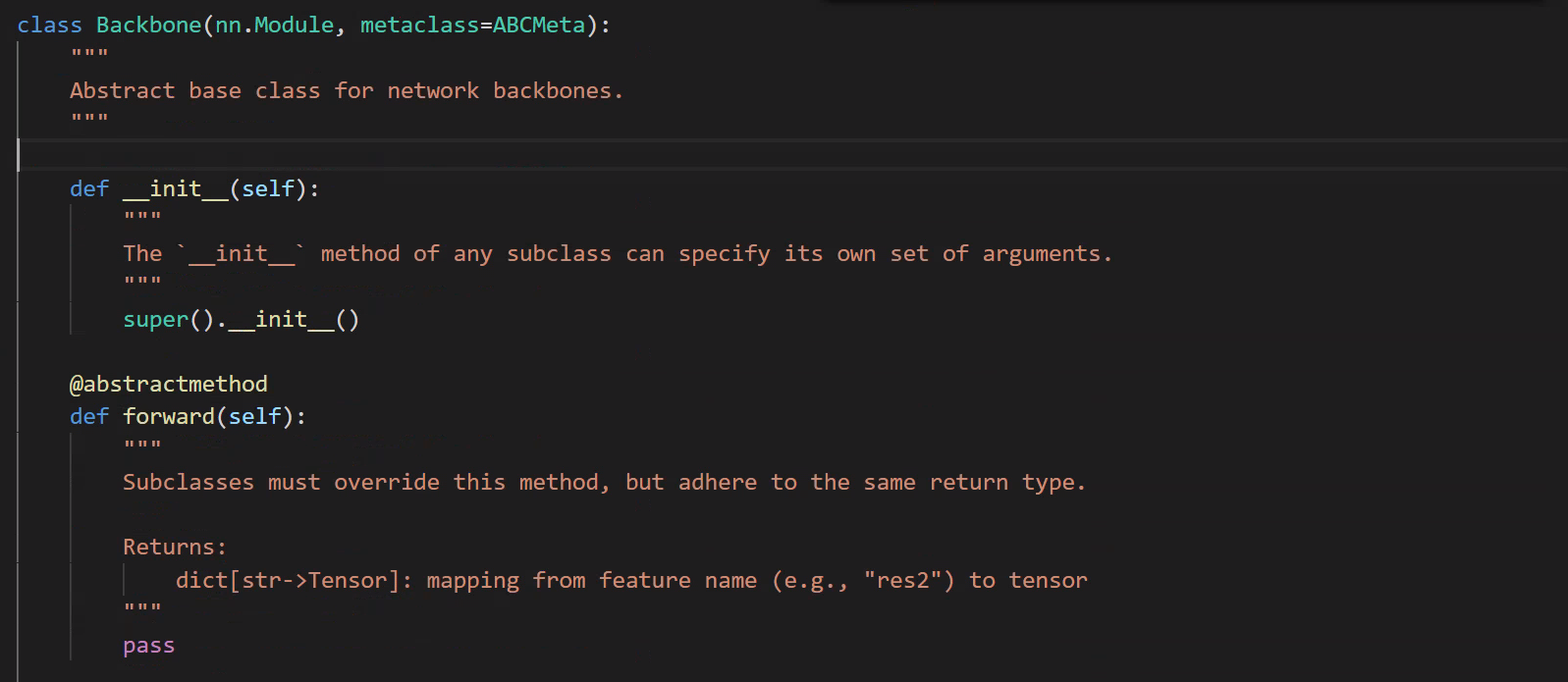
抽象类:
-
类, 是从一堆对象中抽象出来的, 比如猫类,狗类,人类
-
抽象类, 是从一堆类中抽象出来的, 比如上面的三个类可以抽取出动物类
-
抽象类的特点是不能给实例化, 只能被子类继承, 由子类实现了父类的抽象方法后, 子类才能被实例化
-
Python的abc提供了@abstractmethod装饰器实现抽象方法
build backbone
./modeling/backbone/build.py
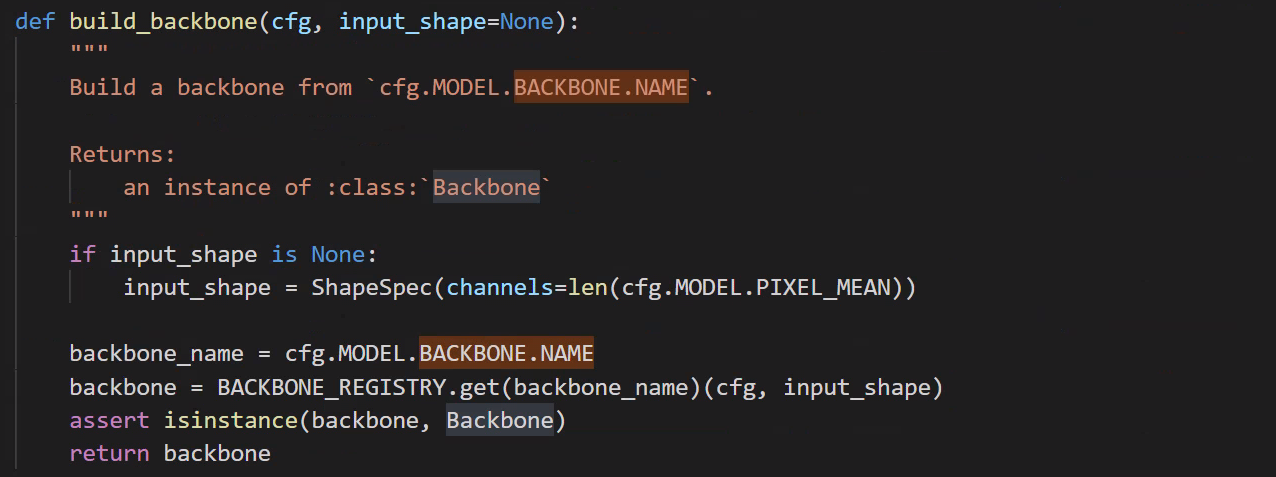
backbone/resnet.py 中继承了 CNNBlockBase,定义了不同的Block,ResNet继承Backbone,并使用定义的block实现ResNet的backbone
当使用 from 模块名 import * 时,想要有一些变量不被调用,可以借助模块提供的 __all__ 变量:
- 该变量的值是一个列表,存储的是当前模块中一些成员(变量、函数或者类)的名称。通过在模块文件中设置
__all__变量,当其它文件以“from 模块名 import * ”的形式导入该模块时,该文件中只能使用__all__列表中指定的成员。 - 也就是说,只有以
“from 模块名 import *”形式导入的模块,当该模块设有__all__变量时,只能导入该变量指定的成员,未指定的成员是无法导入的。
注册与调用:
定义:
@BACKBONE_REGISTRY.register()
def build_resnet_backbone(cfg, input_shape):
return ResNet(stem, stages, out_features=out_features).freeze(freeze_at)
调用:./build.py中根据配置文件名调用之前Register好的backbone
backbone = BACKBONE_REGISTRY.get(backbone_name)(cfg, input_shape)
./modeling/backbone/fpn.py 文件又把build_resnet_backbone生产的resnet作为子结构输入,扩展了不同的FPN的backbone:
# resnet @BACKBONE_REGISTRY.register() def build_resnet_fpn_backbone(cfg, input_shape: ShapeSpec): # retinanet @BACKBONE_REGISTRY.register() def build_resnet_fpn_backbone(cfg, input_shape: ShapeSpec):
2、proposal 生成
./modeling/proposal_generator/build.py
根据配置文件调用相应的 proposal generator :
PROPOSAL_GENERATOR_REGISTRY.get(name)(cfg, input_shape)
# 1
@RPN_HEAD_REGISTRY.register()
class StandardRPNHead(nn.Module):
# 2
@PROPOSAL_GENERATOR_REGISTRY.register()
class RPN(nn.Module):
3、RoI Heads
接口:
./modeling/roi_heads/roi_heads.py
实现:
# 1
@ROI_HEADS_REGISTRY.register()
class Res5ROIHeads(ROIHeads):
# 2
@ROI_HEADS_REGISTRY.register()
class StandardROIHeads(ROIHeads):
4、mask head
def build_mask_head(cfg, input_shape):
name = cfg.MODEL.ROI_MASK_HEAD.NAME
return ROI_MASK_HEAD_REGISTRY.get(name)(cfg, input_shape)
5、keypoint head
def build_keypoint_head(cfg, input_shape):
name = cfg.MODEL.ROI_KEYPOINT_HEAD.NAME
return ROI_KEYPOINT_HEAD_REGISTRY.get(name)(cfg, input_shape)
6、执行流程
./modeling/meta_arch/
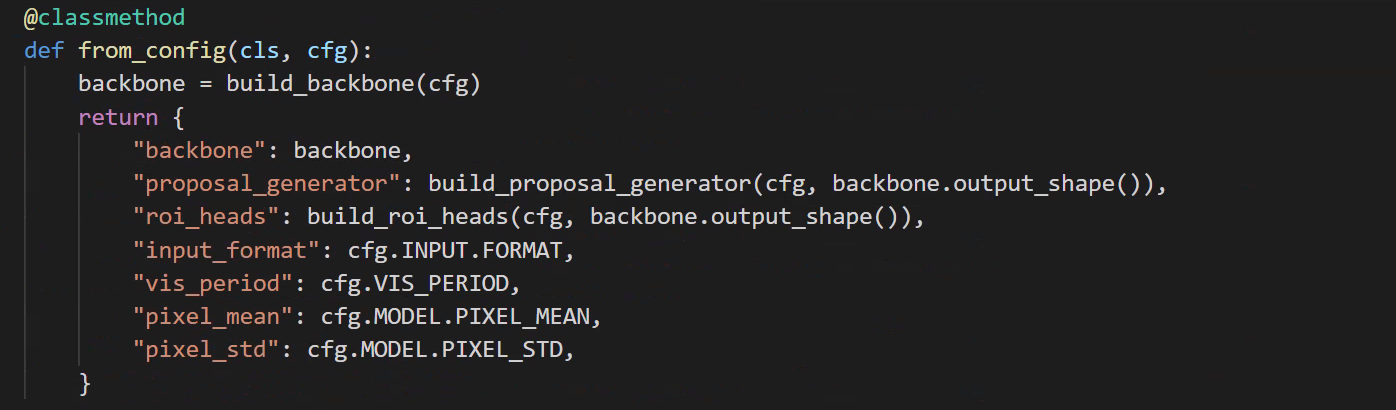
- batch_input 进行预处理
- 输入backbone进行特征提取
- 将feature和img输入给proposal_generator
- 将proposal 结果给到 RoI Heads
def forward(self, batched_inputs):
if not self.training:
return self.inference(batched_inputs)
images = self.preprocess_image(batched_inputs)
if "instances" in batched_inputs[0]:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
else:
gt_instances = None
features = self.backbone(images.tensor)
if self.proposal_generator:
proposals, proposal_losses = self.proposal_generator(images, features, gt_instances)
else:
assert "proposals" in batched_inputs[0]
proposals = [x["proposals"].to(self.device) for x in batched_inputs]
proposal_losses = {
}
_, detector_losses = self.roi_heads(images, features, proposals, gt_instances)
if self.vis_period > 0:
storage = get_event_storage()
if storage.iter % self.vis_period == 0:
self.visualize_training(batched_inputs, proposals)
losses = {
}
losses.update(detector_losses)
losses.update(proposal_losses)
return losses
2.3 训练类的实现
./detectron2/engine/train_loop.py
1、HookBase 定义了四个阶段:
- before_train
- after_train
- before_step
- after_step
2、TrainerBase 对 hook 灵活调用,使用各个功能
3、SimpleTrainer (./train_loop.py) 继承自TrainerBase,对TrainerBase中预留接口的训练核心部分的方法def run_step(self)做了具体实现,包括推理计算loss以及backward:
4、DefaultTrainer(./defaults.py)继承自SimpleTrainer,实现了训练流程,包括创建model, optimizer, scheduler, dataloader,根据配置文件增加了辅助功能hooks类中的功能
2.4 训练
./tools/
可见GPU号修改:
os.environ['CUDA_VISIBLE_DEVIES'] = '0, 1, 2'
train_net.py中层层抽象,在之前TrainBase → \to → SimpleTrainer → \to →DefaultTrainer上又增加了一层抽象,添加evaluation模块的功能,以及inference with test-time augmentation功能
2.5 推理
./detectron2/engine/defaults.py
2.6 模型的加载和保存
1、两种保存模型的方法:
- 仅保存权重
# 保存
torch.save(model.state_dict(), path)
# 加载
model = Model()
model.load_state_dict(torch.load(path))
model.eval()
- 保存整个模型和对应权重
# 保存
torch.save(model, path)
# 加载
model = torch.load(path)
model.eval()
2、保存 checkpoint 的方法
完整的checkpoint一般保存了模型的 state_dict、优化器的state_dict、epoch等
- 保存checkpoint
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss}, path)
- 加载checkpoint
checkpoitn = torch.load(path)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
2.7 性能评估
./detectron2/evaluation/evaluator.py
2.8 日志存储
./engine/hooks.py
日志存储是通过 hook 来控制的,hooks.py 中的 after_step() 方法调用 writer.write() 进行日志的写入。