前几天学习了卷积神经网络之后发现卷积神经网络处理图片时候的优点,同时我发现了神经网络不仅仅在于能处理图片的分类,而且还能实现声音的识别。我就想着既然它能够识别图片的种类,那必定是运用到了图片中的隐含的信息,而这些信息的表示不就是一个个的像素点吗,这个想法让我想将中文转化为像素点,然后将中文的顺序在图片中也按照同样的顺序来进行处理,这样图片中就包含了全部中文的信息,然后将图片放到卷积神经网络上进行处理,那么中文之间的关联信息是否能被挖掘呢(之所以不把中文直接转化为图片是因为这样在神经网络的眼中并不方便处理,直接将中文转化为图片的话会导致一个信息占用太大的空间,不方便存储太多信息,而且中文之间的顺序就变成了图片的特征了,需要神经网络去挖掘,这个的模型我想并不高效)
今我想把上述的想法应用的实际上,首先今天完成第一步,在python中如何将中文转化为像素点。
这个过程应该还是挺容易解决的,python当中支持对中文字符直接的操作,那直接对字符串取ord就得到了对应文字的值
ord('字') ->这个函数在python中就能得出中文的具体值了,那么根据这个具体的值,在图片上对应的点就能设置为相应的颜色的了。
下面参考一个python验证码生成网站:https://blog.csdn.net/peng_for_csdn/article/details/89644853,
实现对中文转化成像素点的过程:
首先
from PIL import Image # 导入画布
import io
首先确定函数,传过来的参数应该是:字符串,输出图片的位置,每行像素点能表示中文的个数即图片的宽度。然后根据这些参数我们定义了以下的函数:
def string_to_imagepixel(str,outpath,width=10):
有了这个函数之后,就要将对应字符串中的信息转化为像素点的信息,我们的思路是将对应的中文字符的值转化为对应表示颜色的值,在这里面可以这么表示。
我们知道每个颜色有0-255这256个数值,然后因为是3通道,所以有3种颜色的表示,在这3种颜色中,所能够表达的种类就有256*256*256种,对于表示汉字来说绰绰有余,而对于这个数值的表示,可以用3位的256进制来表示汉字的信息
我想到用到了对应的python函数int("数值",进制数) ,然后python gg了,提示数值转换超出范围
那这个问题就很有趣了,我们根据网上的资料https://blog.csdn.net/zuofanxiu/article/details/81745334找到了以下的进制转化:
#10进制转其他进制,从地位到高位输出结果 def conversion(n, d): while(n//d >= 1): print(n%d) n = n//d if(n%d !=0):
在这个函数之中我们稍作修改,使其变成我们想要的格式
#10进制转其他进制,从地位到高位输出结果 def conversion(n, d): result=[] while(n//d >= 1): result.append(n%d) n = n//d if(n%d !=0): result.append(n%d) return result;
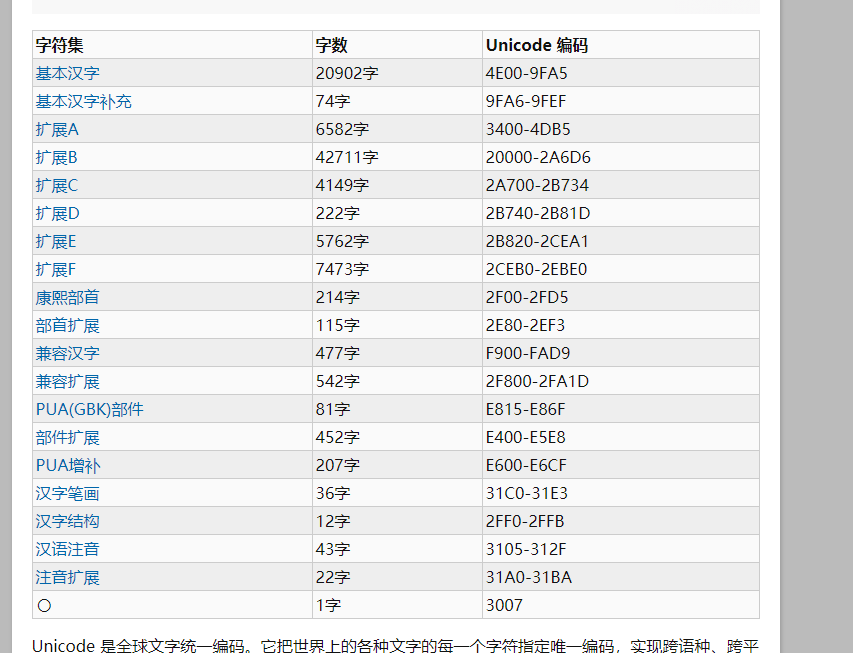
接着,查看中文的范围值有什么,根据资料可以知道中文的范围大概是这么广,接着计算一个3通道像素点表示的范围数是:
256*256=65536
65536*256=16777216种
这远远已经超过了中文的字符种类,还有几位剩余的位置可以留作以后中文的像素点中添加一些额外的信息,暂时当做预设位置。
有了上述的基础之后,我们开始我们中文生成对应的像素点的过程。
首先对字符串进行切分,切分之后的个数就是像素点的个数,但图片有长有宽,所以对像素点的个数除以预设长度得到对应数据的高度,但是这些文字不一定能够填满整张图片,因此对图片的剩余部分进行填充白色的处理,白色的话再中文当中未涉及,因为(255,255,255)即表示为白,而白色的数值16777216大小远远超过了中文的表示范围,因此在这里以白色为填充而不是以黑色
有了上述的设计思想以后,将上述的思想转为代码就是:
def string_to_imagepixel(str,outpath,width=10): strlen=len(str) #获得字符长度 height=strlen//width+1 #计算获得图片高度 # strfill=(strlen%width) #计算获得图片黑色区域填充大小 # if strfill!=0: # height+=1 #若有填充区域则高度加一 bgcolor = (255 ,255, 255) #设置图片背景颜色为黑色 img = Image.new(mode='RGB', size=(width, height), color=bgcolor) #创建一个画板 # print(width," ",height) for i in range(len(str)): x=i%width y=i//width pointvalues=conversion(ord(str[i]),256) #获得汉字的表示颜色 if(len(pointvalues)==2): color1 = (pointvalues[0], pointvalues[1],0) elif(len(pointvalues)==3): color1 = (pointvalues[0], pointvalues[1], pointvalues[2]) elif (len(pointvalues) == 1): color1 = (pointvalues[0], 0, 0) else: color1 = (255, 255, 255) # print(x, " ", y) img.putpixel((x,y),color1) #设置画布对应点的颜色 img.save(outpath) # 保存 return img
利用上述代码生成的图片为:

已经经过了放大处理,这张图片中存储的中文信息为:
天天开心,每天都是幸福满满的
经过了函数:
string_to_imagepixel("天天开心,每天都是幸福满满的",r"C:UsersHaloDesktop1.6项目开发过程 est.png",10);
的转换,如此一来,就能生成可以产生含有中文信息的图片了
这个过程
为了能让图片更好地代入卷积神经网络(卷积神经网络中有卷积层,会对图片数据进行卷积计算,因此可以将像素点放大到同样的卷积核大小,或者直接将卷积核设置为1),或可以对图片进行放大处理。
然而我发现了在生成的过程当中,图片的大小会随着字符串的长度的改变而改变,可变长度的图片代入神经网络中,很明显是不可能的,因此可以采用一开始就预设多个位置,则给图片设置固定高度,好让其可以代入神经网络当中,图片的高度宽度即固定,则必须对于在此之前长度的字符串均可以代入其中。例如一张宽为40 高为10的图片可以代入0-400个字符,依次类推,这样就实现了动态代入神经网络
修改之后的代码,hum若为空,则高度自己根据图片的所给的宽度而发生改变
def string_to_imagepixel(str,outpath,width=40,hnum=None):
strlen=len(str) #获得字符长度
if(hnum==None):
height=strlen//width+1 #计算获得图片高度
else:
height=hnum
# strfill=(strlen%width) #计算获得图片黑色区域填充大小
# if strfill!=0:
# height+=1 #若有填充区域则高度加一
bgcolor = (0 ,0, 0) #设置图片背景颜色为黑色
img = Image.new(mode='RGB', size=(width, height), color=bgcolor) #创建一个画板
# print(width," ",height)
for i in range(len(str)):
x=i%width
y=i//width
pointvalues=conversion(ord(str[i]),256) #获得汉字的表示颜色
if(len(pointvalues)==2):
color1 = (pointvalues[0], pointvalues[1],0)
elif(len(pointvalues)==3):
color1 = (pointvalues[0], pointvalues[1], pointvalues[2])
elif (len(pointvalues) == 1):
color1 = (pointvalues[0], 0, 0)
else:
color1 = (0, 0, 0)
# print(x, " ", y)
img.putpixel((x,y),color1) #设置画布对应点的颜色
img.save(outpath) # 保存
return img
几百个文字存储信息图片:

经过测试后,在神经网络的识别上,步长设置为1,卷积核设置为1有较好的回溯效果