并发编程之线程池

步骤1 :自定义拒绝策略接口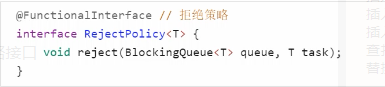

1)线程池状态
ThreadPoolExecutor使用int的高3位来表示线程池状态,低29位表示线程数量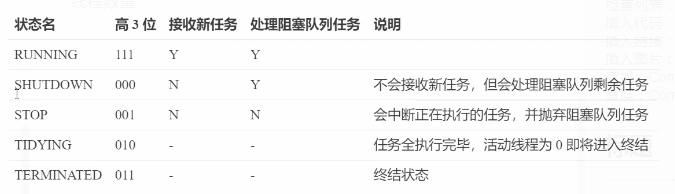
从数字上比较,TERMINATED>TIDYING>STOP>SHUTDOWN>RUNNING
这些信息存储在一个原子变量ctl中目的是将线程池状态与线程个数合二为一,这样就可以用一次cas原子操作进行赋值
2)构造方法
- corePool :Size核心线程数目(最多保留的线程数)
- maximunPoolSize :最大线程数目
- keepAliveTIme :生存时间- 针对救急线程
- unit :时间单位 - 针对救急线程
- workQueue :阻塞队列
- threadFactory :线程工厂 - 可以为线程创建时起个好名字
- handler :拒绝策略
工作方式 :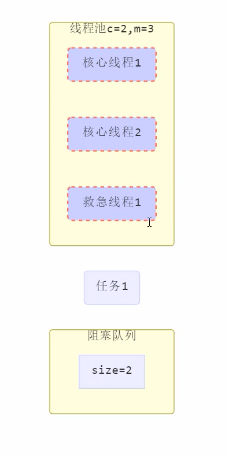
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到corePoolSize并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue队列排队,直到有空闲的线程。
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建maximumPoolSize - corePoolSize 数目的线程来救急。
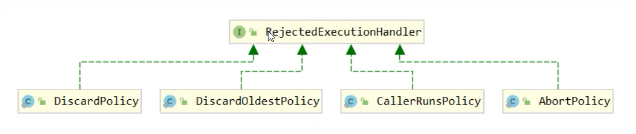
- 如果线程达到maximumPoolSize任然有新任务这时会执行拒绝策略。拒绝策略jdk提供了4种实现,其它著名框架也提供了实现
- AbortPolicy 让调用者抛出RejectedExecutionException异常, 这时默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- Dubbo的实现,在抛出RejectedExecutionException 异常之前会记录日志,并dump线程栈信息,方便定位问题
- Netty的实现,是创建一个新线程来执行任务
- ActiveMQ的实现,待超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
- 当高峰过去后,超过corePoolSize的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由keepAliveTime和unit来控制。
根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
3)newFixedThreadPool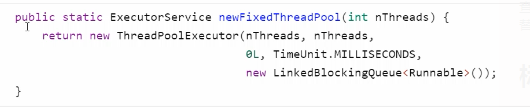
特点 - 核心线程数 == 最大线程数 (没有救急线程被创建),因此也需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
适用于任务量已知,相对耗时的任务
4)newCachedThreadPool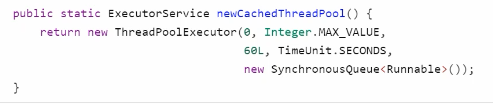
特点 - 核心线程数是0,最大线程数是Integer.MAX_VALUE,救急线程的空闲生存时间是60s,意味着
- 全部都是救急线程(60s后可以回收)
- 救急线程可以无限创建
- 队列采用了SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)

评价
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲一分钟后释放线程。适合任务数比较密集,但每个任务执行时间较短的情况
5)newSingleThreadExecutor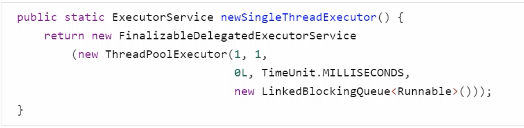
使用场景 :
希望多个任务排队执行。线程数固定为1,任务数多于1时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别 : - 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任务补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor()线程个数始终为1,不能修改
- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了ExecutorService接口,因此不能调用ThreadPoolExecutor中特有的方法
- Executors.newFixedThreadPool(1)初始化时为1,以后还可以修改
- 对外暴露的是ThreadPoolExecutor对象,可以强转后调用 setCorePoolSize 等方法进行修改
6)提交任务
7)关闭线程池
shutdown

shutdownNow

其它方法
- 对外暴露的是ThreadPoolExecutor对象,可以强转后调用 setCorePoolSize 等方法进行修改
1.定义
3. 创建多少线程池合适
- 过小会导致程序不能充分地利用系统资源,容易导致饥饿
- 过大会导致更多的线程上下文切换,占用更多内存
3.1 CPU 密集型运算
通常采用cpu 核数 + 1能够实现最优的CPU利用率, + 1是保证当线程由于页缺失故障(操作系统)或其它原因导致暂停时,额外的这个线程就能顶上去,保证CPU时钟周期不被浪费
3.2 I/O 密集型运算
CPU不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用CPU资源,但当你执行IO操作时、远程RPC调用时,包括进行数据库操作时,这时候CPU就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间 + 等待时间)/ CPU 计算时间
例如4核CPU计算时间是50%,其它等待时间是50%,期望cpu被100%利用,套用公式
4 * 100% * 100% / 50% = 8
例如4核CPU计算时间是10%,其它等待时间是90%,期望CPU被100%利用,套用公式
4 * 100% * 100% / 10% = 40
10)线程池
Tomcat 在哪里用到了线程池呢?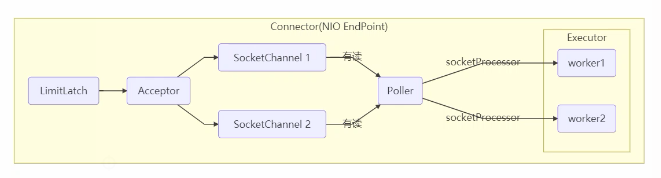
- LimitLatch 用来限流,可以控制最大连接个数,类似J.U.C中的Semaphore
- Acceptor只负责【接收新的socket连接】
- Poller 只负责监听 socket channel 是否有【可读的I/O事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给Executor线程池处理
- Executor 线程池中的工作线程最终负责 【处理请求】
Tomcat线程池扩展了ThreadPoolExecutor,行为稍有不同 - 如果总线程数达到maxmumPoolSize
- 这时不会立刻抛RejectedExecutionException 异常
源码 tomcat-7.0.42

Connector 配置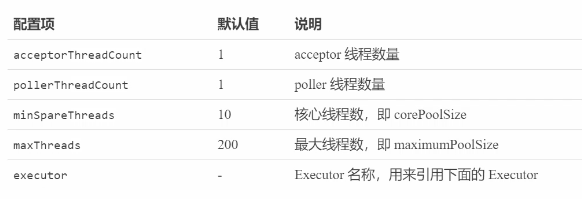
Executor 线程配置
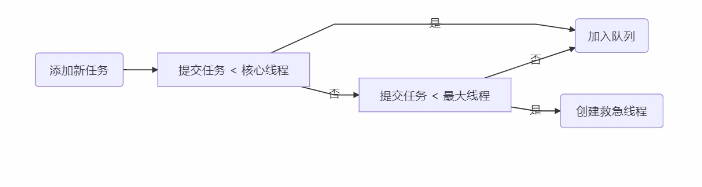
- 这时不会立刻抛RejectedExecutionException 异常
1) 概念
Fork/Join 是 JDK 1.7加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的cpu密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
For/Join 在分治的基础上加入多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率
Fork/Join 默认会创建于cpu核心数大小相同的线程池
2)使用
提交给Fork/ Join线程池的任务需要继承 RecursiveTask (有返回值)或RecursiveAction(没有返回值),列如下面定义了一个队1~n之间的整数求和的任务

用图来表示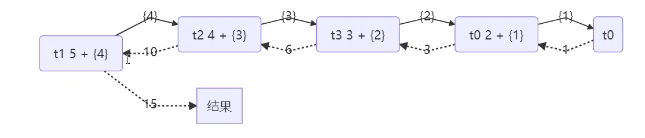
改进优化 :

用图来表示 :